The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTNVIDIA Caffe2 Docker: ResNet50 and ImageNet
Kernels and deep learning math operations may be useful, but in the end devices are trained with real datasets. Using the standard ILSVRC 2012 pictureset, we run the standard ResNet-50 training implementation that is included in NVIDIA's Caffe2 Docker image. The model trains on ImageNet and gives us some throughput data.
While there were separate switches for FP16 and tensor cores, running FP16 mode with tensors enabled and disabled resulted in identical results for the Titan V.
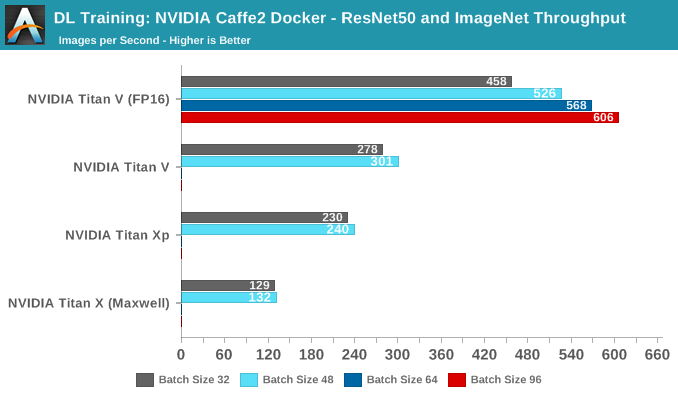
No score indicates card ran out of video memory
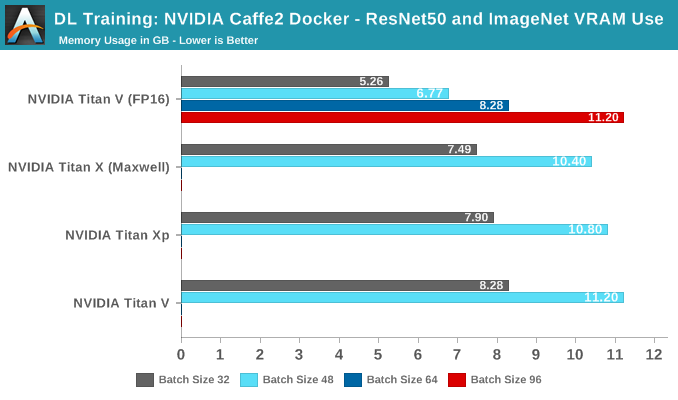
In terms of pure throughput, the Titan V takes the lead at all batch sizes. In fact, with tensors enabled it is able to go beyond 64 batches, as opposed to the other cards, even though they all have 12 GBs of VRAM. The reasoning is that FP16 consumes less video memory.
The issue with raw throughput metrics is that real-world performance for deep learning is never so simple. For one, many models might be optimized for throughput but sacrifice accuracy and/or training time. Peak or even sustained images trained per second may not be useful if the model takes an extended amount of time to converge. This is particularly relevant for Volta with FP16 storage and tensor cores, as there may be a number of necessary mitigations like loss scaling or single precision batch normalization, which wouldn't be directly accounted for in throughput metrics.
That being said, finding modern benchmarks that are Volta-aware, reasonably close to state-of-the-art, provide better metrics, go beyond CNNs for computer vision, and are accessible by non-researchers, has been a struggle. Throughput benchmarks are easier to validate and create, but in many situations they are better suited for identifying bottlenecks, platform differences, and optimization points.








65 Comments
View All Comments
krazyfrog - Saturday, July 7, 2018 - link
I don't think so.https://www.anandtech.com/show/12170/nvidia-titan-...
mode_13h - Saturday, July 7, 2018 - link
Yeah, I mean why else do you think they built the DGX Station?https://www.nvidia.com/en-us/data-center/dgx-stati...
They claim "AI", but I'm sure it was just an excuse they told their investors.
keg504 - Tuesday, July 3, 2018 - link
"With Volta, there has little detail of anything other than GV100 exists..." (First page)What is this sentence supposed to be saying?
Nate Oh - Tuesday, July 3, 2018 - link
Apologies, was a brain fart :)I've reworked the sentence, but the gist is: GV100 is the only Volta silicon that we know of (outside of an upcoming Drive iGPU)
junky77 - Tuesday, July 3, 2018 - link
ThanksAny thoughts about Google TPUv2 in comparison?
mode_13h - Tuesday, July 3, 2018 - link
TPUv2 is only 45 TFLOPS/chip. They initially grabbed a lot of attention with a 180 TFLOPS figure, but that turned out to be per-board.I'm not sure if they said how many TFLOPS/w.
SirPerro - Thursday, July 5, 2018 - link
TPUv3 was announced in May with 8x the performance of TPUv2 for a total of a 1 PF per podtuxRoller - Tuesday, July 3, 2018 - link
Since utilization is, apparently, an issue with these workloads, I'm interested in seeing how radically different architectures, such as tpu2+ and the just announced ibm ai accelerator (https://spectrum.ieee.org/tech-talk/semiconductors... which looks like a monster.MDD1963 - Wednesday, July 4, 2018 - link
4 ordinary people will buy this....by mistake, thinking it is a gamer. :)philehidiot - Wednesday, July 4, 2018 - link
"With DL researchers and academics successfully using CUDA to train neural network models faster, it was only a matter of time before NVIDIA released their cuDNN library of optimized deep learning primitives, of which there was ample precedent with the HPC-focused BLAS (Basic Linear Algebra Subroutines) and corresponding cuBLAS. So cuDNN abstracted away the need for researchers to create and optimize CUDA code for DL performance. As for AMD’s equivalent to cuDNN, MIOpen was only released last year under the ROCm umbrella, though currently is only publicly enabled in Caffe."Whatever drugs you're on that allow this to make any sense, I need some. Being a layman, I was hoping maybe 1/5th of this might make sense. I'm going back to the porn. </headache>