TensorFlow
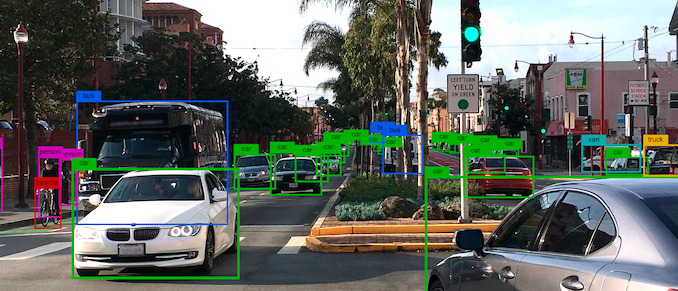
A large number of inference demonstrations published by the big chip manufacturers revolve around processing large batch sizes of images on trained networks. In reality, when video is being inferenced, it is frame by frame – an effective batch size of one. The large chips on the market aren’t optimized for a batch size of one, and grossly overconsume power to do so: Flex Logix believes it has the answer with its new InferX chip design and IP for this market, focusing directly on those edge devices that process at a batch size of one and are fanless.

The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
When we last discussed the NVIDIA Titan V in our preview, it was only a few weeks after its surprise launch at NIPS 2017. We came away with the...
65 by Nate Oh on 7/3/2018
Google Announces Cloud TPU v2 Beta Availability for Google Cloud Platform
This week, Google announced Cloud TPU beta availability on the Google Cloud Platform (GCP), accessible through their Compute Engine infrastructure-as-a-service. Using the second generation of Google’s tensor processing units...
8 by Nate Oh on 2/15/2018
AMD Announces Wider EPYC Availability and ROCm 1.7 with TensorFlow Support
Earlier this year AMD announced its return to the high-end server market with a series of new EPYC processors. Inside is AMD’s new Zen core, up to 32 of...
20 by Ian Cutress on 11/13/2017





