AI On The Edge: New Flex Logix X1 Inference AI Chip For Fanless Designs
by Ian Cutress on April 10, 2019 8:30 AM EST- Posted in
- SoCs
- PCIe
- AI
- TensorFlow
- Inference
- Flex Logix
- nnMax
- InferX X1
A large number of inference demonstrations published by the big chip manufacturers revolve around processing large batch sizes of images on trained networks. In reality, when video is being inferenced, it is frame by frame – an effective batch size of one. The large chips on the market aren’t optimized for a batch size of one, and grossly overconsume power to do so: Flex Logix believes it has the answer with its new InferX chip design and IP for this market, focusing directly on those edge devices that process at a batch size of one and are fanless.
InferX X1: A Chip with nnMax IP
The announcement today from Flex Logix at the Linley Processor Conference has multiple angles:
- nnMax IP, built on eFPGA technologies, making the inference possible
- Infer X1 chips, built on nnMax but with a software stack for custom designs
- Infer X1 PCIe cards, with X1 chips onboard.
On one side, the company is promoting its new nnMax IP which makes this AI inference possible. On the other, based on customer demand, they are creating their own silicon using the IP to make dedicated chips and a software stack available as dedicated chips for customer designs, or as a PCIe card.

The InferX X1 chip is what brings all of the technology together. The chip is built on TSMC 16FF, and combines a lot of Flex Logix IP into a single design that takes advantage of the eFPGA technology to provide a lower power and higher performance solution. The best way to describe it is to go through how an inference pattern is computed in the chip.
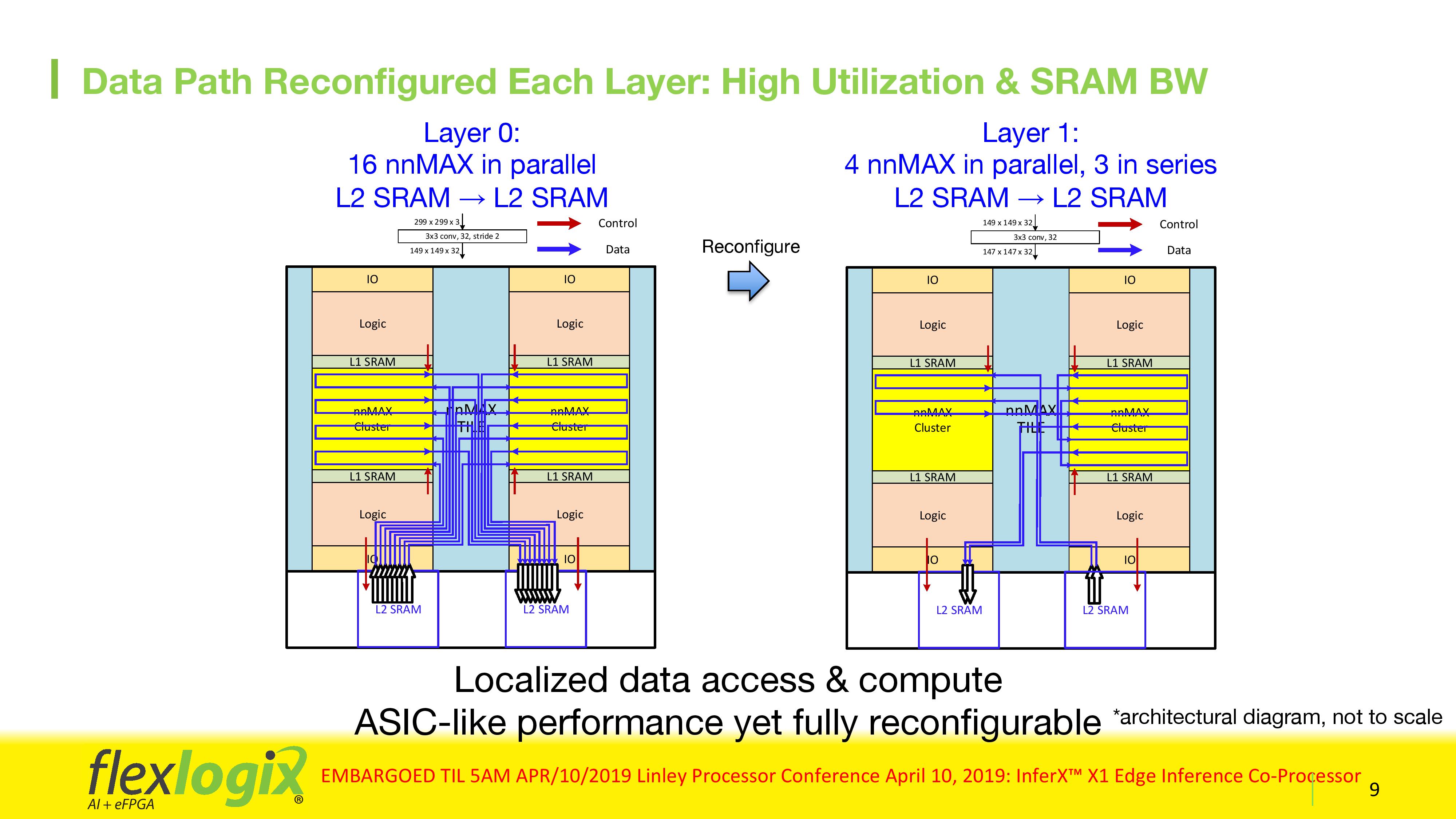
A single tile of the design features 1024 MAC units and 2MB of on-die memory, and the data comes in through the ArrayLINX interconnect into the first nnMax cluster. Due to the eFPGA design, with a precomputed bitstream, the convolution layer of the model is channelled through the MACs with the appropriate weights fed in through the SRAM in the most power efficient and performant way possible. Given that a layer for a typical large image database, such as YOLOv3, can take a billion MAC passes to finish, this gives the logic time to pull the next layer of weights from DRAM into SRAM. Between layers, the eFPGA-based nnMax reconfigures based on the layer requirements, so if data is required to be fed differently, the IP already knows which way to send the data to get the best out of it. This realignment takes 512-1024 cycles, which at the rated 1 GHz speed at worst is only one microsecond.
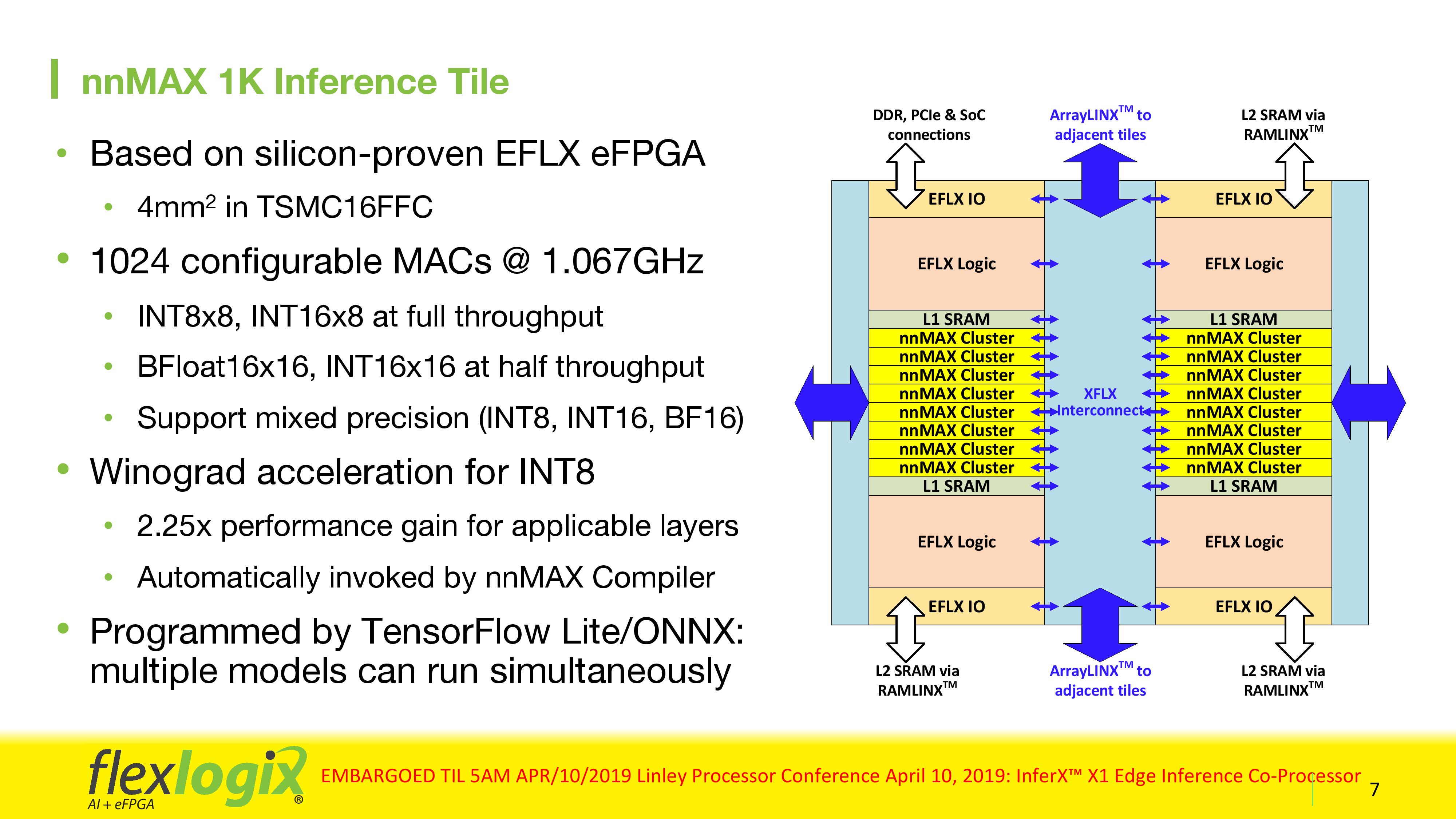
The Infer X1 chip is actually four of these 1K MAC tiles, for a total of 4096 MACs and 8MB of SRAM, and allows for the results of one layer to feed into the other, which is especially useful if the new weights require more than the on-chip SRAM available and saves power with fewer accesses out to the DRAM. Even if layers require access to off-chip DRAM, the connections are non-blocking, and the company states that the bandwidth is far in excess of what the L1 needs to feed the MACs.
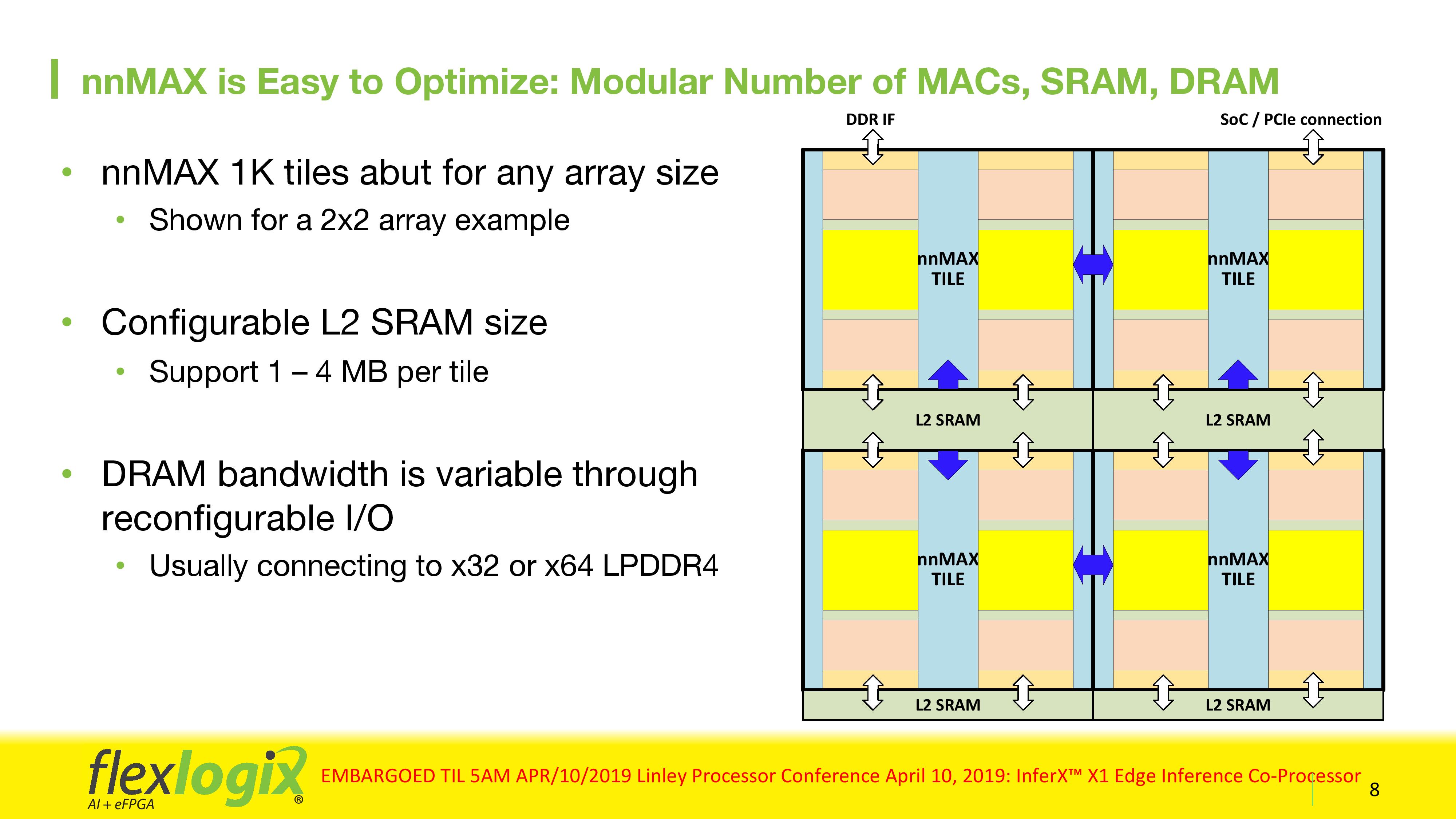
Flex Logix aims to make using the X1 very easy: the customer does not need to know any FPGA programming tools. Their API uses TensorFlow Lite (and soon ONNX), and their software stack automatically generates the required bitstream for the network that the customer requires. The chip supports INT8, INT16, and bfloat16, and will automatically cast between them as needed for the precision required.
One feature that Flex Logix states is important for some customers the support for INT8 Winograd acceleration for 3x3 convoltuion layers with a stride of 1. It involves taking the 3x3 matrices and converting them into 4x4 for compute, but the X1 solution means that the transformation, in order to maintain accuracy, will convert weights on the fly from 8-bit to 12-bit, and expand results only when needed, saving power and maintaining accuracy. The result is a 2.25x overall acceleration, even though more compute is needed, but offers full accuracy without penalties.
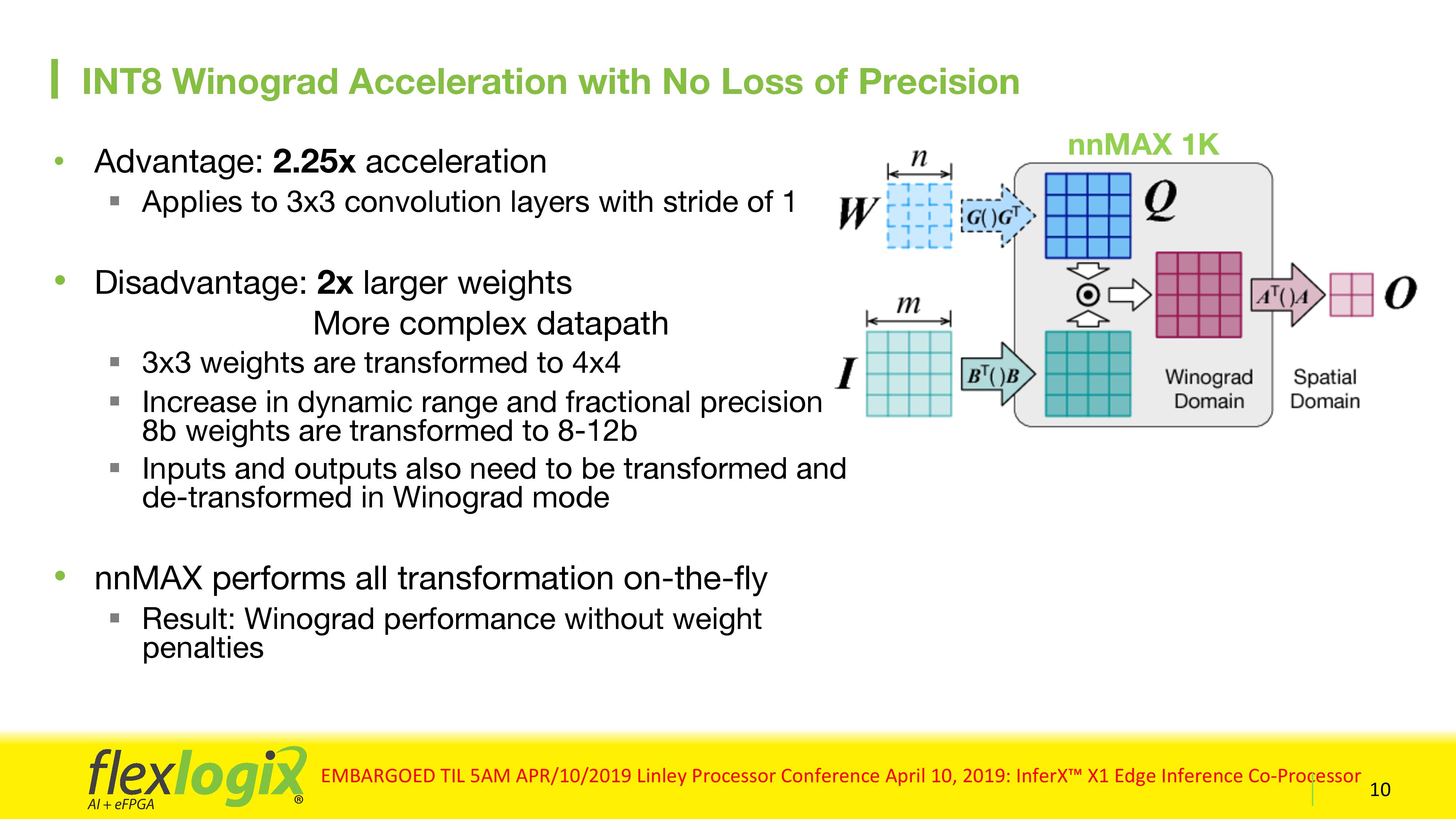
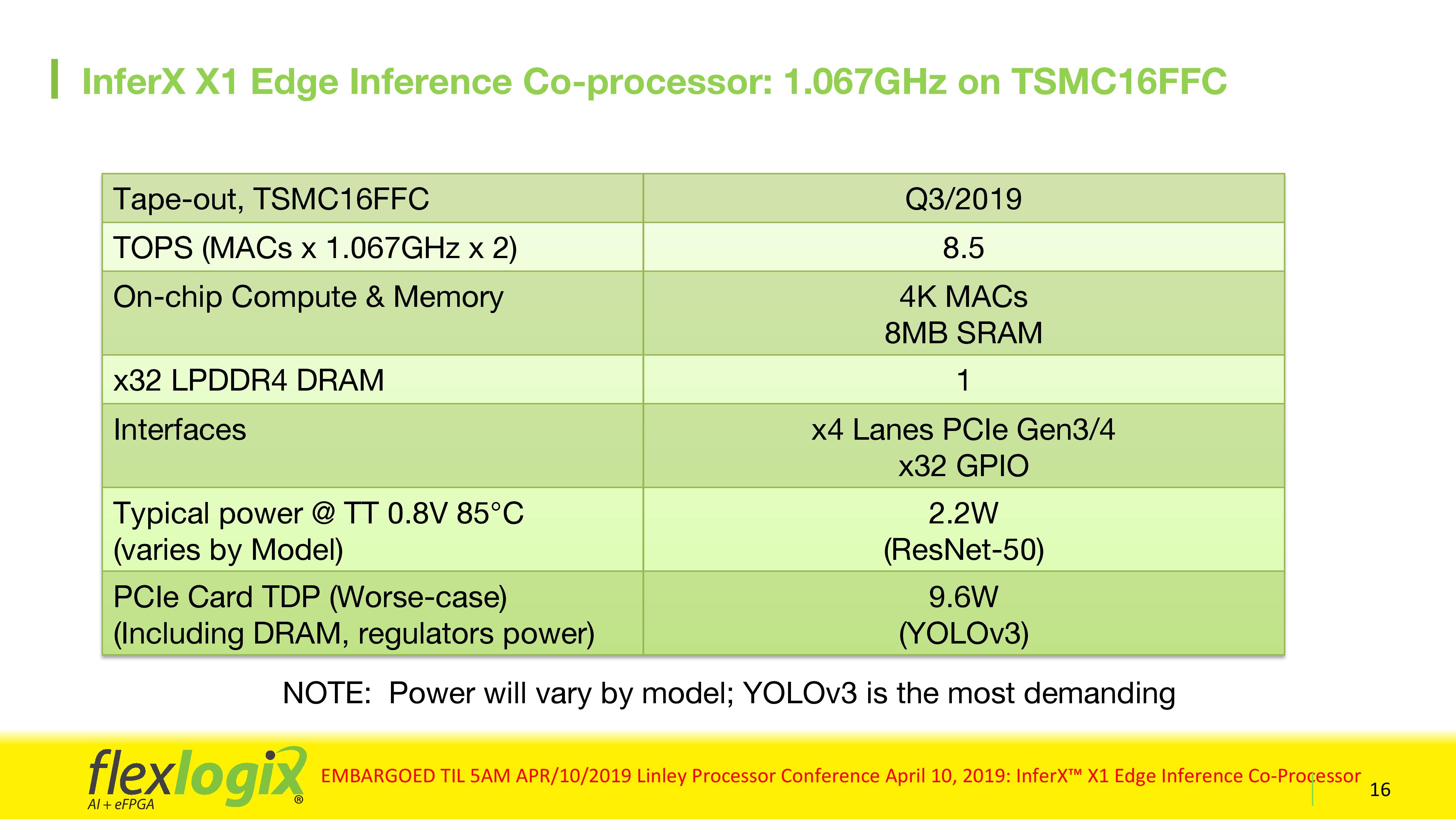
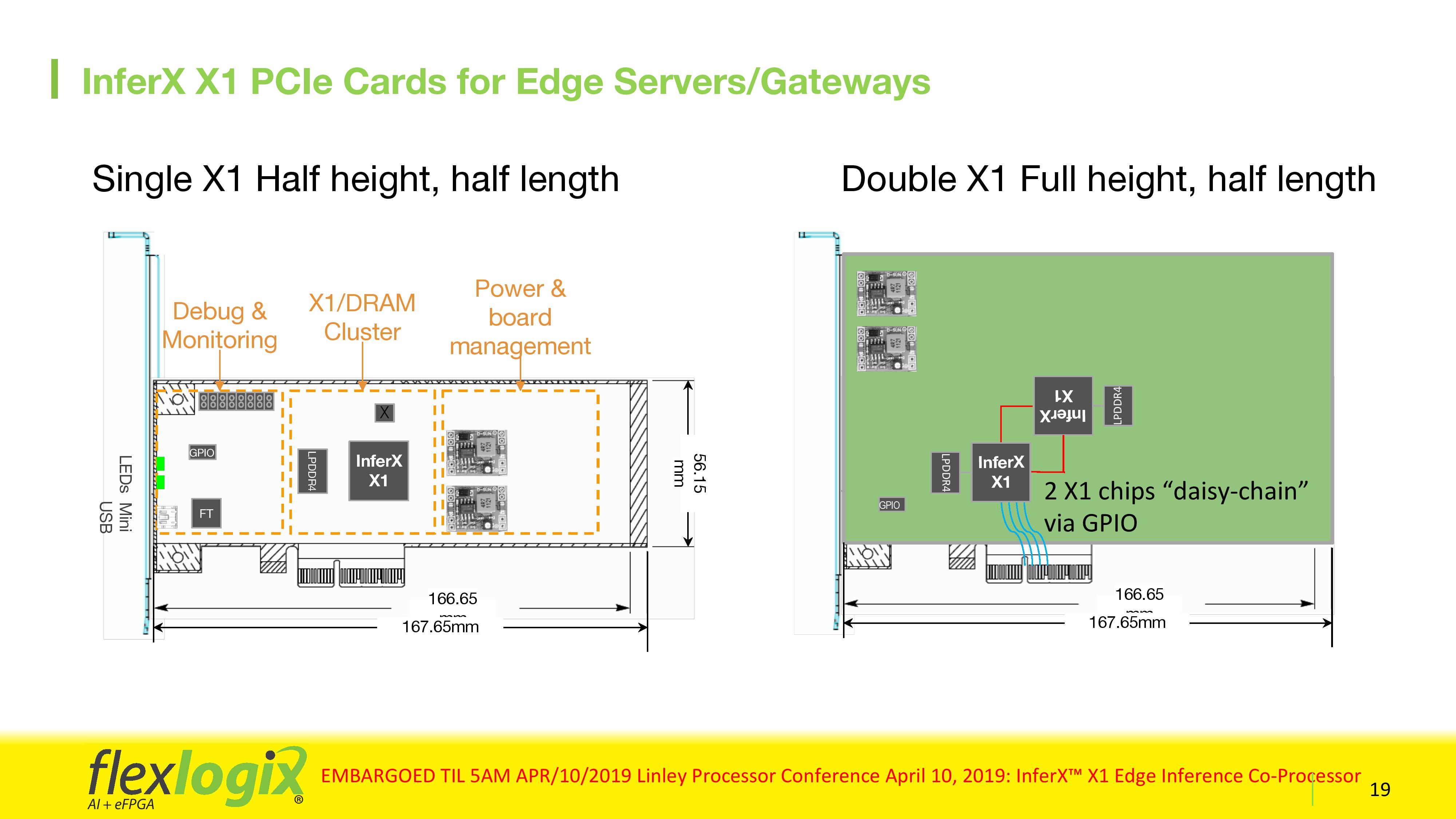
Overall, a single X1 chip with 4096 MACs, at 1.067 GHz, can hit a peak of 8.5 TOPS. Power consumption depends on the model used, but Flex Logix quotes 2.2 W for ResNet-50, or 9.6 W for YOLOv3 in a worst-case scenario. The chip has four PCIe 3.0 lanes (as well as GPIO), allowing it to be used on a PCIe card. Flex Logix will offer two PCIe card variants, a single X1 solution and a double X1 solution where two chips are daisy chained via GPIO. Customers are free to take the chips and build bigger solutions over PCIe as required. We suggested that Flex Logix should offer the chip in an M.2 form factor, which would expand the usability of the chip to many other systems.
Customers interested in the design can either look at the nnMax IP, the X1 chip, or the X1 PCIe cards. The company is targeting edge devices, such as surveillance cameras, industrial robots, or interactive set top boxes, although the PCIe card is likely to appeal to edge gateway and edge server customers.
As a general marker of performance, Flex Logix cited that on a more ‘standard’ model that the chip wasn’t optimized for, the chip at a batch size of 1 will compute ResNet-50 at 1/3 the rate of a Tesla T4, but offer 3x the throughput per $, which would suggest that the company is overall targeting 1/9 of the cost of a Tesla T4. Flex Logix states that for the PCIe cards, most of the cost is actually in the card design (PCB, voltage regulators, assembly), not the X1 chip, suggesting that customers could build 10-20x chip daisy chain designs without too much overhead.
The silicon is expected to tapeout in Q3, with silicon and PCIe card samples available at the end of the year or Q1 2020. Currently a performance estimation tool is available, allowing customers to put in their own models and get an estimate of performance in terms of frames per second, MAC utilization, die area, SRAM bandwidth, latency, etc.
-page-001_thumb.jpg)
-page-002_thumb.jpg)
-page-003_thumb.jpg)
-page-004_thumb.jpg)
-page-005_thumb.jpg)
-page-006_thumb.jpg)








1 Comments
View All Comments
p1esk - Wednesday, April 10, 2019 - link
Ok, so this one is a "proper" paper launch, unlike Qualcomm's :)Sounds like Nvidia Jetson competitor, and is probably better than Jetson Nano, but by the time it's out next year, Nvidia will probably release the successor. It's a tough market!