The NVIDIA Titan V Preview - Titanomachy: War of the Titans
by Ryan Smith & Nate Oh on December 20, 2017 11:30 AM ESTCompute Performance: Geekbench 4
In the most recent version of its cross-platform Geekbench benchmark suite, Primate Labs added CUDA and OpenCL GPU benchmarks. This isn’t normally a test we turn to for GPUs, but for the Titan V launch it offers us another perspective on performance.
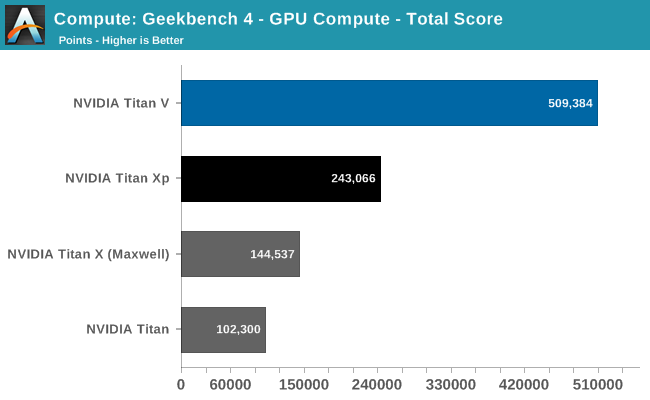
The results here are interesting. We’re not the only site to run Geekbench 4, and I’ve seen other sites with much different scores. But as we haven’t used this benchmark in great depth before, I’m hesitant to read too much into it. What it does show us, at any rate, is that the Titan V is well ahead of the Titan Xp here, more than doubling the latter’s score.
| NVIDIA Titan Cards GeekBench 4 Subscores | ||||||
| Titan V | Titan Xp | GTX Titan X | GTX Titan | |||
| Sobel (GigaPixels per second) |
35.1 | 24.9 | 16.5 | 9.4 | ||
| Histogram Equalization (GigaPixels per second) |
21.2 | 9.43 | 5.58 | 4.27 | ||
| SFFT (GFLOPS) |
180 | 136.5 | 83 | 60.3 | ||
| Gaussian Blur (GigaPixels per second) |
23.9 | 2.67 | 1.57 | 1.45 | ||
| Face Detection (Msubwindows per second) |
21.7 | 12.4 | 8.66 | 4.92 | ||
| RAW (GigaPixels per second) |
18.2 | 10.8 | 5.63 | 4.12 | ||
| Depth of Field (GigaPixels per second) |
3.31 | 2.74 | 1.35 | 0.72 | ||
| Particle Physics (FPS) |
83885 | 30344 | 18725 | 18178 | ||
Looking at the subscores, the Titan V handily outperforms the Titan Xp on all of the subtests. However it’s one test in particular that stands out here, and is likely responsible for the huge jump in the overall score, and that’s the Gaussian Blur, where the Titan V is 9x (!) faster than the Titan Xp. I am honestly not convinced that this isn’t a driver or benchmark bug of some sort, but it may very well be that Primate Labs has hit on a specific workload or scenario that sees some rather extreme benefits from the Volta architecture.
Folding @ Home
Up next we have the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, giving us a good opportunity to let Titan V flex its FP64 muscles.
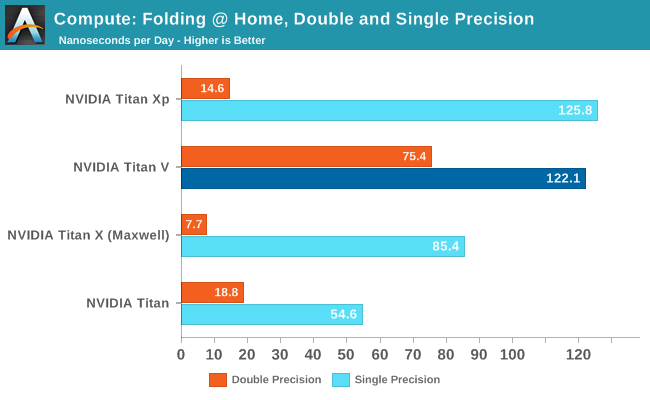
A CUDA-backed benchmark, this is the first sign that Titan V’s performance lead over the Titan Xp won’t be consistent. And more specifically that existing software and possibly even NVIDIA’s drivers aren’t well-tuned to take advantage of the Volta architecture just yet.
In this case the Titan V actually loses to the Titan Xp ever so slightly. The scores are close enough that this is within the usual 3% margin of error, which is to say that it’s a wash overall. But it goes to show that Titan V isn’t going to be an immediate win everywhere for existing software.
CompuBench
Our final set of compute benchmarks is another member of our standard compute benchmark suite: CompuBench 2.0, the latest iteration of Kishonti's GPU compute benchmark suite. CompuBench offers a wide array of different practical compute workloads, and we’ve decided to focus on level set segmentation, optical flow modeling, and N-Body physics simulations.
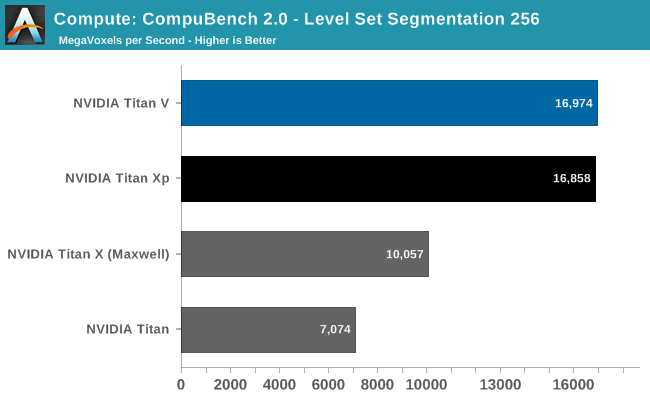
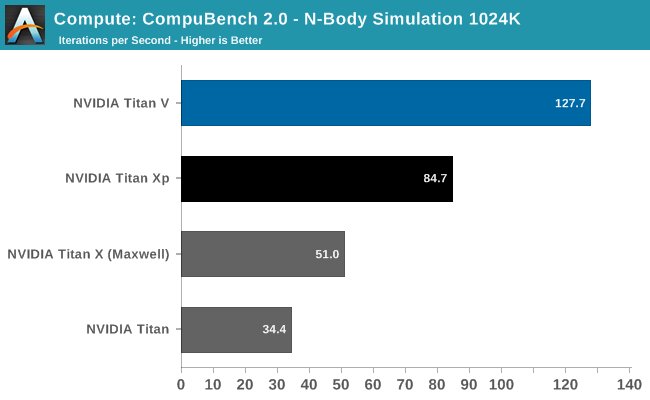
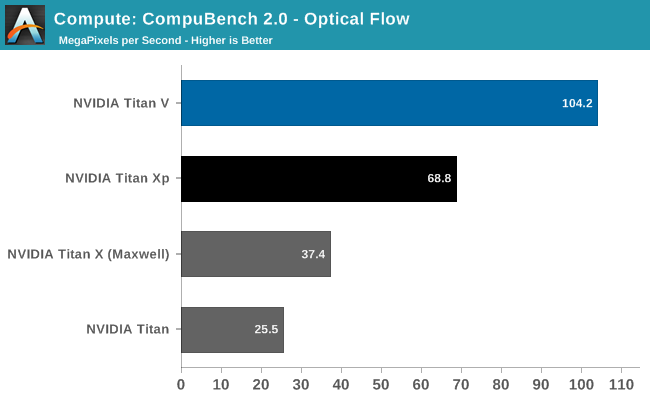
It’s interesting how the results here are all over the place. The Titan V shows a massive performance improvement in both N-Body simulations and Optical Flow, once again leading to the Titan V punching well above its weight. But then the Level Set Segmentation benchmark is practically tied with the Titan Xp. Suffice it to say that this puts the Titan V in a great light, and conversely makes one wonder how the Titan Xp was (apparently) so inefficient. The flip side is that it’s going to be a while until we fully understand why certain workloads seem to benefit more from Volta than other workloads.








111 Comments
View All Comments
praktik - Wednesday, December 20, 2017 - link
Actually probably both XP and V could run 4k Crysis pretty well - do we need 4xssaa @ 4k??Ryan Smith - Wednesday, December 20, 2017 - link
"do we need 4xssaa"If it were up to me, the answer to that would always be yes. Jaggies suck.
tipoo - Wednesday, December 20, 2017 - link
Do they plan on exposing fast FP16 in software? When consumer Volta launches maybe?Ryan Smith - Wednesday, December 20, 2017 - link
Nothing has been announced at this time.Keldor314 - Wednesday, December 20, 2017 - link
The part of the article about Volta no longer having a superscalar architecture is incorrect. Although there is only one warp scheduler per SM partition (what do you call those things anyway?), each clock cycles only serves half a warp, so it takes two clock cycles for an instruction to feed into one of the execution pipelines, but during the second cycle, the warp schedular is free is issue a second instruction to one of the other pipelines. IIRC, Fermi did this too.mode_13h - Wednesday, December 27, 2017 - link
Also, the part about per-thread PC and Stack is misleading. Warps are still executing (or not executing) from a single instruction sequence. The threads within a warp are not concurrently executing different instructions, nor are threads being dynamically shuffled between different warps - at least, not at a hardware level.MrSpadge - Wednesday, December 20, 2017 - link
> Sure, compute is useful. But be honest: you came here for the 4K gaming benchmarks, right?Actually, no: I came for compute, power and voltage.
jabbadap - Wednesday, December 20, 2017 - link
Interesting, so it have full floating point compute capabilities 1*fp64 -> 2*fp32 -> 4*fp16 + Tensor cores. But that half precision is only for CUDA? So no direct3d 12 minimum floating point precision.Native7i - Wednesday, December 20, 2017 - link
So it looks like V series focused on machine learning and development.Maybe rumors are correct about Ampere replacing Pascal...
extide - Saturday, December 23, 2017 - link
Maybe, I mean GP100 was very different than GP102 on down, so they could do the same thing..