AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
Decode
For the decode stage, the main uptick here is the micro-op cache. By doubling in size from 2K entry to 4K entry, it will hold more decoded operations than before, which means it should experience a lot of reuse. In order to facilitate that use, AMD has increased the dispatch rate from the micro-op cache into the buffers up to 8 fused instructions. Assuming that AMD can bypass its decoders often, this should be a very efficient block of silicon.
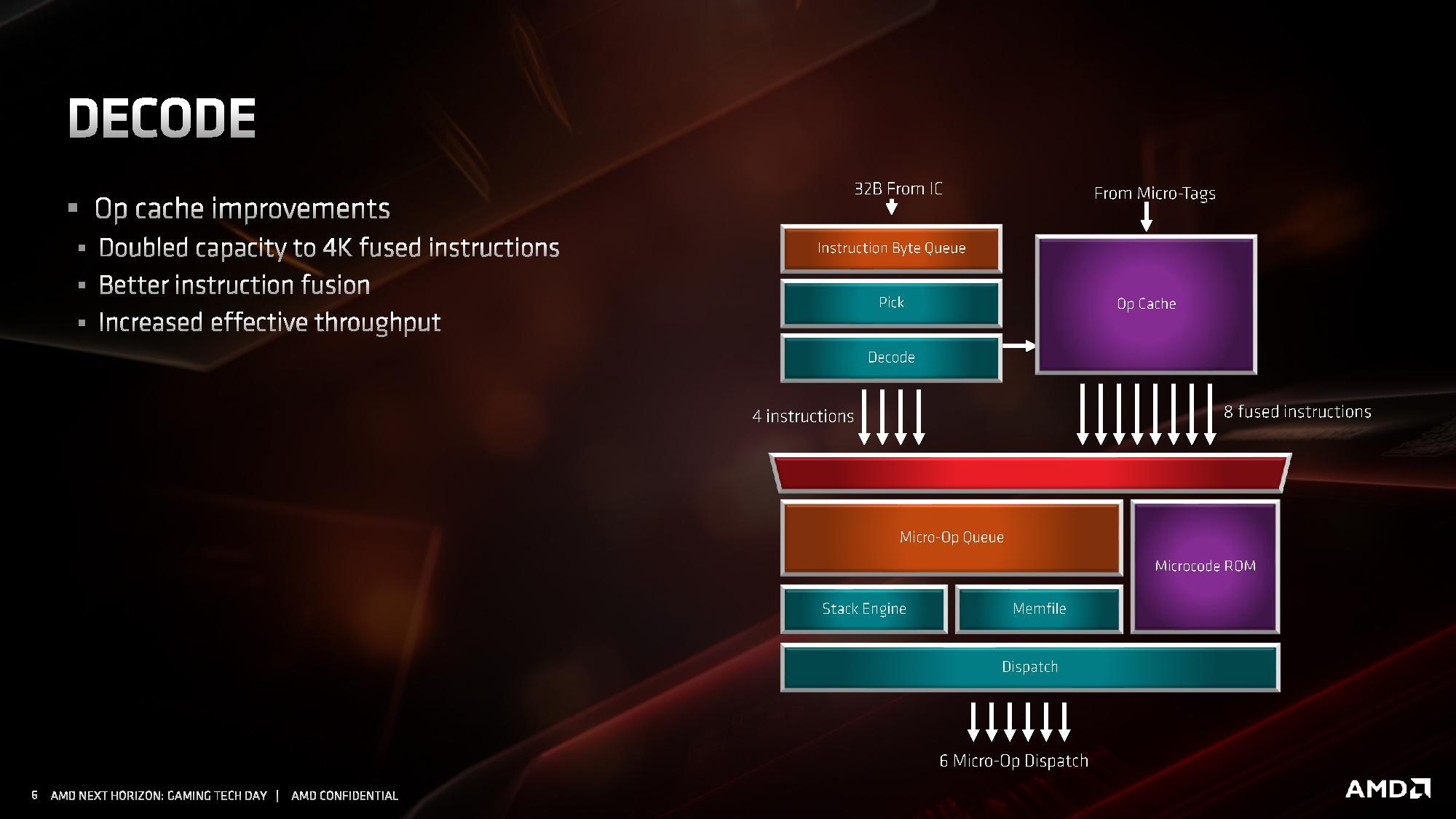
What makes the 4K entry more impressive is when we compare it to the competition. In Intel’s Skylake family, the micro-op cache in those cores are only 1.5K entry. Intel increased the size by 50% for Ice Lake to 2.25K, but that core is coming to mobile platforms later this year and perhaps to servers next year. By comparison AMD’s Zen 2 core will cover the gamut from consumer to enterprise. Also at this time we can compare it to Arm’s A77 CPU micro-op cache, which is 1.5K entry, however that cache is Arm’s first micro-op cache design for a core.
The decoders in Zen 2 stay the same, we still have access to four complex decoders (compared to Intel’s 1 complex + 4 simple decoders), and decoded instructions are cached into the micro-op cache as well as dispatched into the micro-op queue.
AMD has also stated that it has improved its micro-op fusion algorithm, although did not go into detail as to how this affects performance. Current micro-op fusion conversion is already pretty good, so it would be interesting to see what AMD have done here. Compared to Zen and Zen+, based on the support for AVX2, it does mean that the decoder doesn’t need to crack an AVX2 instruction into two micro-ops: AVX2 is now a single micro-op through the pipeline.
Going beyond the decoders, the micro-op queue and dispatch can feed six micro-ops per cycle into the schedulers. This is slightly imbalanced however, as AMD has independent integer and floating point schedulers: the integer scheduler can accept six micro-ops per cycle, whereas the floating point scheduler can only accept four. The dispatch can simultaneously send micro-ops to both at the same time however.








216 Comments
View All Comments
stance_changer - Sunday, June 23, 2019 - link
Does IF use PCI E? I thought it used the wiring in 2p epyc systems, and IIRC PCI E doesn't double the bus width every gen, but I would love to be proven wrong.SlitheryDee - Friday, June 28, 2019 - link
I've been using intel for a few years now, but I must say I can't describe how much I love what AMD is doing these days. I go where the performance per dollar is generally, so the best complement I can pay them is to say my next upgrade will be based on an AMD chip.SlyNine - Sunday, July 7, 2019 - link
So, what time exactly do these new cpus launch. I mean. The hour.Dodozoid - Sunday, July 7, 2019 - link
Yeah, I was also trying to find that information with no success.Do the reviewers know already or are they waiting for a release instruction from AMD?
ilux.merks - Sunday, July 7, 2019 - link
What nobody is talking about is how are the fixes for meltdown and spectre on these new amd processors?Korguz - Sunday, July 7, 2019 - link
simple.. they dont exist, from what i have seen.. those issues.....are intels only ...