AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
Fetch/Prefetch
Starting with the front end of the processor, the prefetchers.
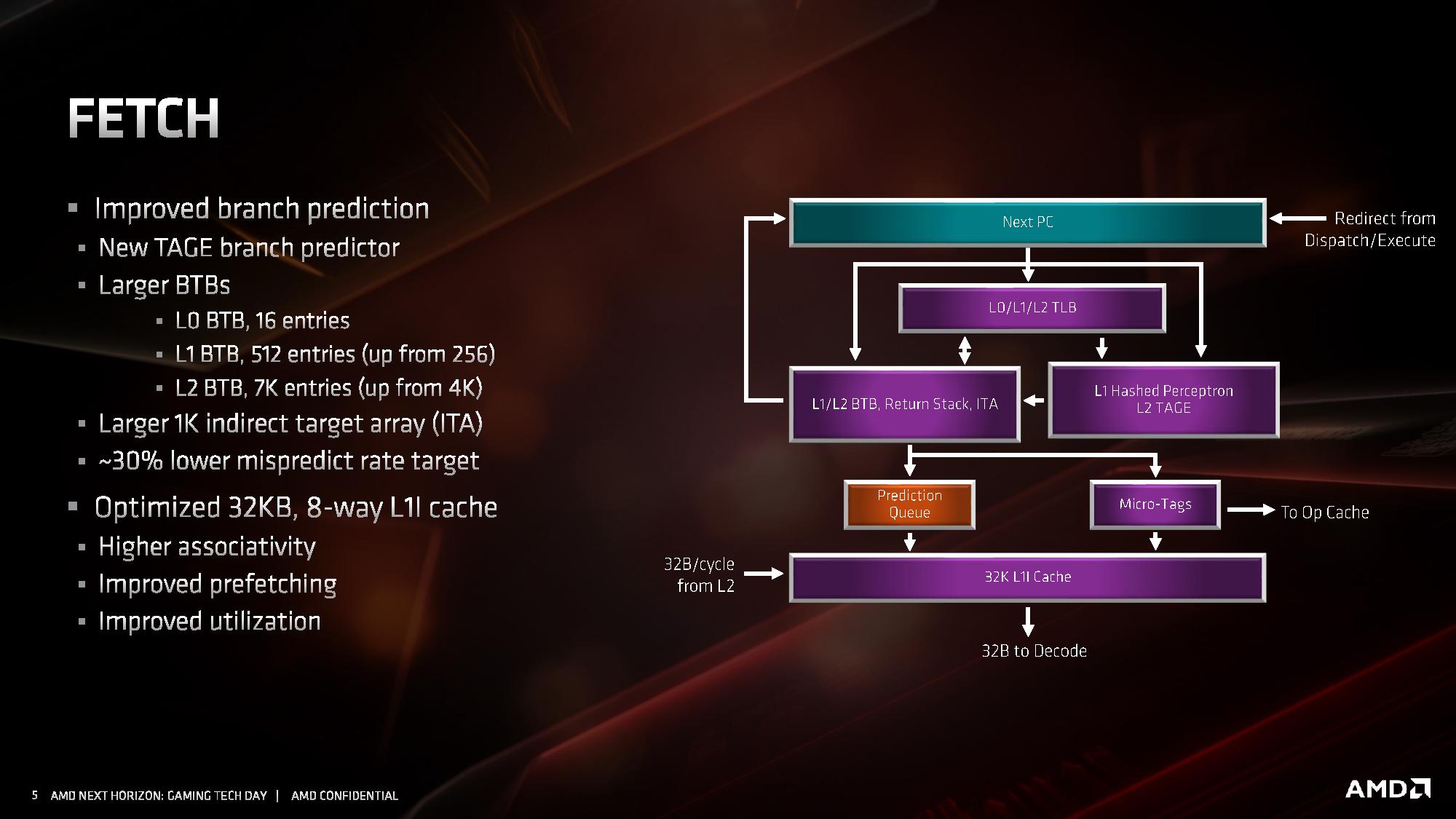
AMD’s primary advertised improvement here is the use of a TAGE predictor, although it is only used for non-L1 fetches. This might not sound too impressive: AMD is still using a hashed perceptron prefetch engine for L1 fetches, which is going to be as many fetches as possible, but the TAGE L2 branch predictor uses additional tagging to enable longer branch histories for better prediction pathways. This becomes more important for the L2 prefetches and beyond, with the hashed perceptron preferred for short prefetches in the L1 based on power.
In the front end we also get larger BTBs, to help keep track of instruction branches and cache requests. The L1 BTB has doubled in size from 256 entry to 512 entry, and the L2 is almost doubled to 7K from 4K. The L0 BTB stays at 16 entries, but the Indirect target array goes up to 1K entries. Overall, these changes according to AMD affords a 30% lower mispredict rate, saving power.
One other major change is the L1 instruction cache. We noted that it is smaller for Zen 2: only 32 KB rather than 64 KB, however the associativity has doubled, from 4-way to 8-way. Given the way a cache works, these two effects ultimately don’t cancel each other out, however the 32 KB L1-I cache should be more power efficient, and experience higher utilization. The L1-I cache hasn’t just decreased in isolation – one of the benefits of reducing the size of the I-cache is that it has allowed AMD to double the size of the micro-op cache. These two structures are next to each other inside the core, and so even at 7nm we have an instance of space limitations causing a trade-off between structures within a core. AMD stated that this configuration, the smaller L1 with the larger micro-op cache, ended up being better in more of the scenarios it tested.








216 Comments
View All Comments
JohnLook - Monday, June 10, 2019 - link
@Ian Cutress Are you sure the Io dies are on TSMC's 14 & 12 nm processes ?all info so far was that they were on GloFo's 14 nm ...
Ian Cutress - Monday, June 10, 2019 - link
Sorry, glofo 14 and 12. Matisse IO die is Glofo 12nm. We triple confirmed.JohnLook - Monday, June 10, 2019 - link
Thanks :-)scineram - Tuesday, June 11, 2019 - link
It still says Epyc is TSMC.John_M - Tuesday, June 11, 2019 - link
It would be nice if the article was updated as not everyone reads the comments section and AnandTech articles do often get cited in Wikipedia articles.Smell This - Wednesday, June 12, 2019 - link
I feel safe in saying that Wiki-Dom will be right on it . . .;-)
So __ those little white lines are the Infinity Scalable Data Fabric (SDF) and the Infinity Scalable Control Fabric (SCF), connecting "Core" chiplets to the I/O core.
"The SDF might have dozens of connecting points hooking together things such as PCIe PHYs, memory controllers, USB hub, and the various computing and execution units."
"The SDF is a superset of what was previously HyperTransport. The SCF is a complementary plane that handles the transmission ..."
https://en.wikichip.org/wiki/amd/infinity_fabric
Of course, I counted them (rolling eyes at myself), and determined there were 32 connecting a single core chiplet to the I/O core. I'm smelling a rational relationship between those 32, and other such stuff. Are the number of IF links a proprietary secret to AMD?
Yah know? It would be a nice 'get' if a tech writer interviewed someone in that former Sea Micro bunch, and spilled a few beans . . .
Smell This - Wednesday, June 12, 2019 - link
Might be 36 ... LOL
Smell This - Wednesday, June 12, 2019 - link
Could be 42- or 46 IF links on the right(I'll stop obsessing)
sweetca - Thursday, June 13, 2019 - link
I don't understand anything you said 🙂Smell This - Sunday, June 16, 2019 - link
I was (am) trolling Ian/AT for a **Deep(er) Dive** on the Infinity Fabric -- its past, and its future. The EPYC Rome processors have 8 "Core" chiplets connecting to the I/O core. Right? Those 'little white lines' (32- to 46?) from each chiplet, presumably, scale to ... infinity?AMD purchased SeaMicro 7 years ago as the "Freedom Fabric" platform was developed. Initially the SM15000 'stitched' together 512 compute cores, 160 gigabits of I/O networking and 5+ petabytes of storage to form a 'very-high-density server.'
And then . . . they went dark.
https://www.anandtech.com/show/9170/amd-exits-dens...
(see the last comment on that link)