Intel Details Manufacturing through 2023: 7nm, 7+, 7++, with Next Gen Packaging
by Ian Cutress & Anton Shilov on May 8, 2019 4:35 PM EST
At Intel's Investor Day today, CEO Bob Swan and Murthy Renduchintala spoke to the ability of the company with respect to its manufacturing capabilities. Intel has historically been strong in its ability to execute on its process technology, however the delay of its 10nm process has obviously raised multiple question marks, and has done for several years. The two Intel executives went into a little detail about what Intel was doing in the interim, and how it has learned from the issues.

Back in 2013, Intel envisoned its 10nm to succeed the 14nm by providing 2.7x density, with new technologies such as Self-Aligned Quad Patterning (SAQP), Contact over Active Gate (COAG), Cobolt Interconnects, and new packaging technologies such as EMIB and Foveros. Intel admits that this was an ambitious plan, and the goals were not clearly defined with the teams and it was ultimately overly complex and not managed in an ideal way.
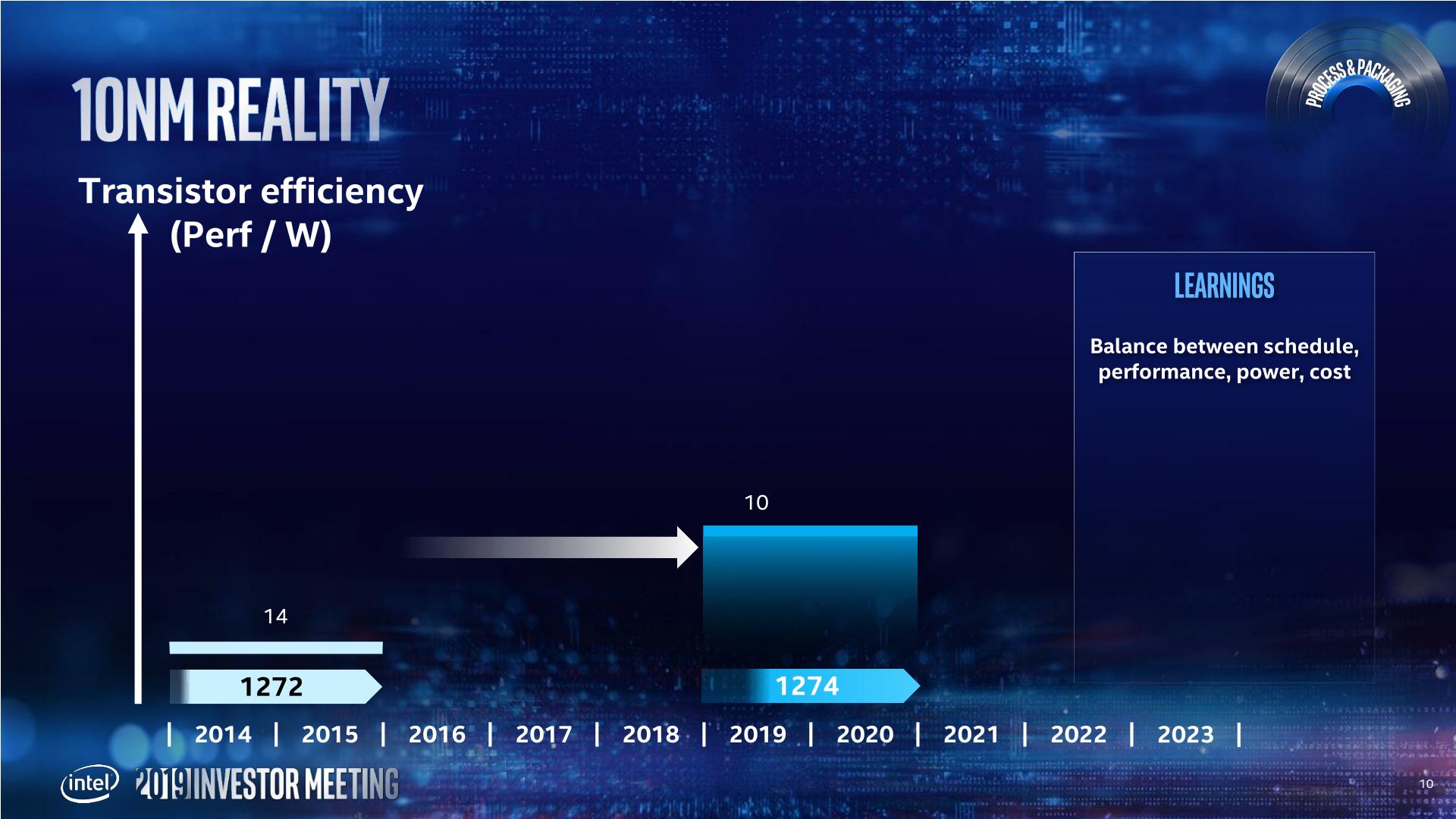
This ended up pushing 10nm out into a later time frame. In this case, Intel pushed 10nm out to 2019 (technically they shipped Cannon Lake in small quantities on 10nm in 2017, however that is nothing more than a curio in the timeline of semiconductors), and filled the gap with 14+ and 14++.
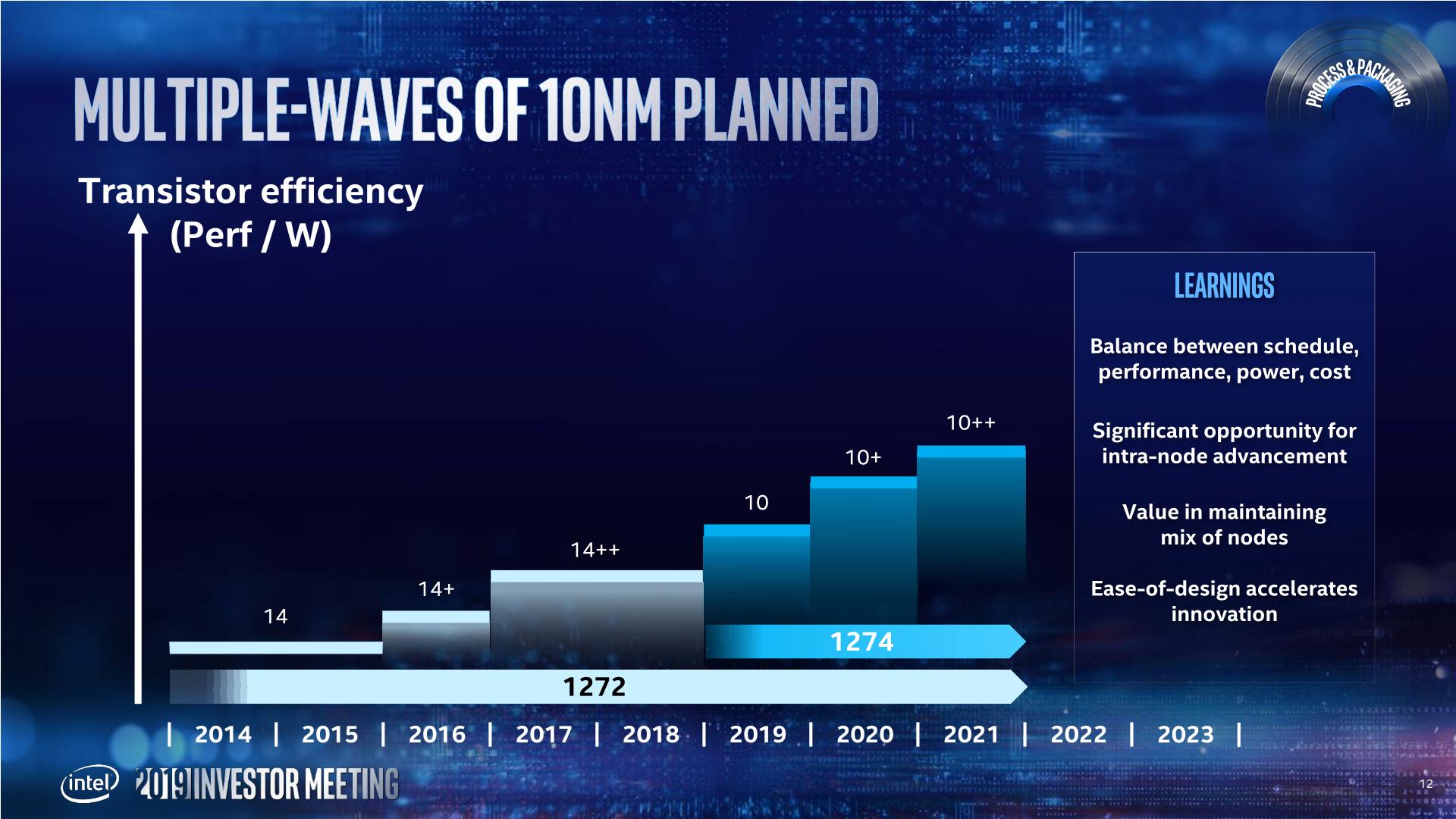
Intels 14+ and 14++ processes extracted more than 20% more performance (from Broadwell to Whiskey Lake) from the process since its inception. As a result, Intel is prepared to not only get ready for future intra-node optimizations, but actually adjust the roadmap to compensate for it. Murthy made it clear that Intel wants to introduce a Moore's Law-like gain at the beginning of a new process, and another similar gain by the end of the process.
Intel has stated that its 10nm product family (beyond Cannon Lake) will start to be available from the middle of this year (2019), with Ice Lake on client platforms (notebooks).

Intel will be launching multiple 10nm products through 2019 and 2020, including server based 10nm in the first half of 2020:

In the above slide, Intel states that it will have 7nm in production and launching a product in 2021. That sounds very aggressive for a company that has had issues with 10nm. It even shows in Intels radmap, with 10nm (and 10+ and 10++) having a much shorter life cycle than the 14nm family of processes.
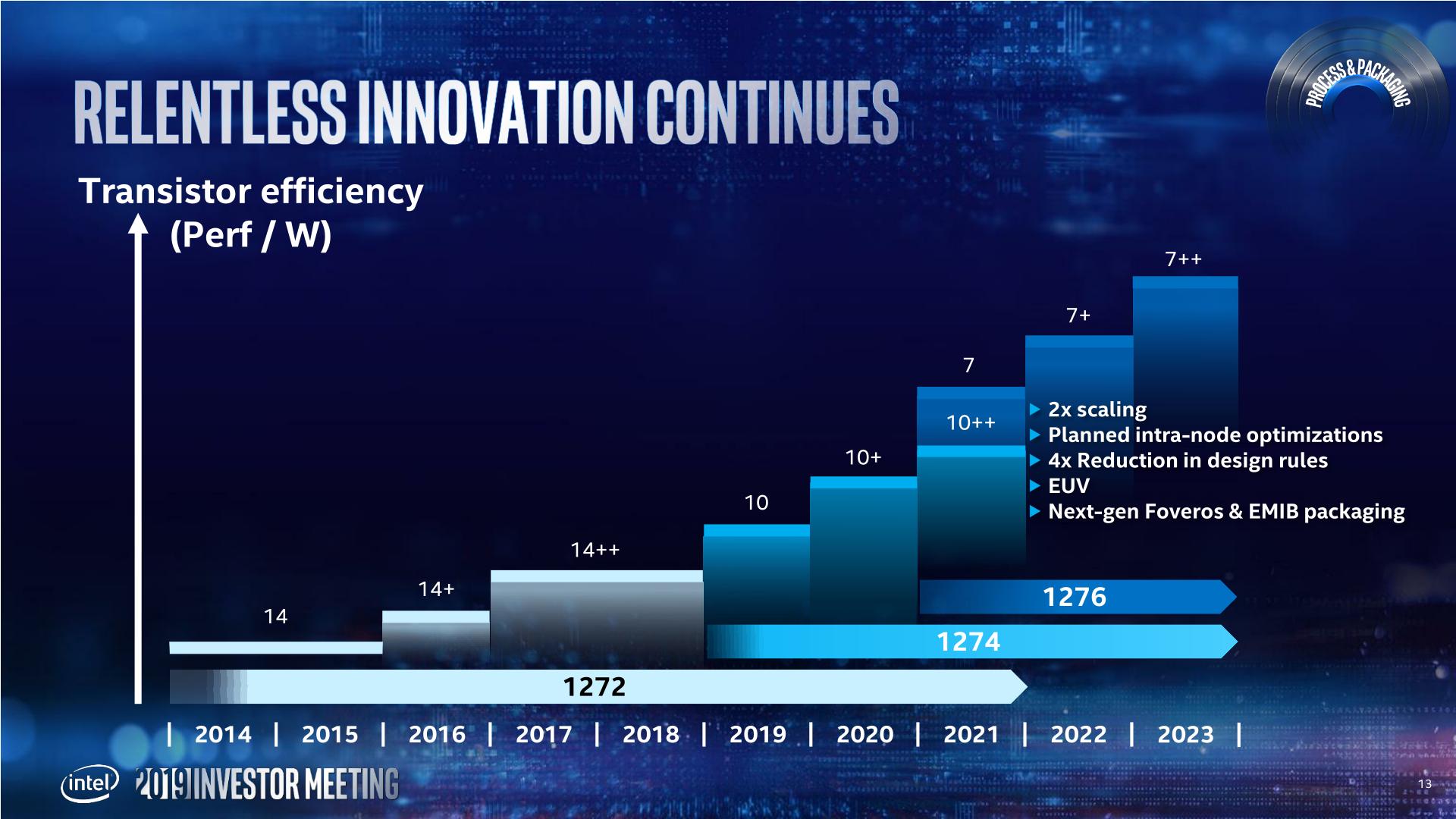
With this in mind, Intel's 7nm is going to be the combination of what Intel has learned from the 14nm and 10nm family of products. Intel wants that 2x scaling (Moores Law), but with intra-node optimations planned as part of the roadmap. Intel is also reducing its number of design rules, which should help with execution. 7nm will also be where Intel intersects with EUV, and also introduce next-gen Foveros and EMIB packainging.

Intel provided this slide, which shows a monolithic PC-Centric die with a multi-die Data-Centric chip built on both Foveros and EMIB. This corroborates our discussion with Intel's chiplet and packaging team, who also stated that we would see Foveros and EMIB on a combined product - specifically the GPU.

Intel announced that its lead 7nm product (lead = top, or lead = first?) would be its new GPGPU, built on the Xe graphics architecture. Intel has stated that its Xe product stack will feature two different microarchitectures from mobile client up to GPGPU, with one of those architectures called Arctic Sound - technically Intel will launch its first discrete GPU in 2020 according to its press release, however the 7nm GPGPU will be launched in 2021.
More information is coming out of Intel's Event, more to follow.
Related Reading
- Intel: EUV-Enabled 7nm Process Tech is on Track
- Intel Starts Qualification of Ice Lake CPUs, Raises 10nm Volume Expectation for 2019
- Intel Agilex: 10nm FPGAs with PCIe 5.0, DDR5, and CXL
- Intel to Equip Fab 42 for 7 nm
- Intel Discloses Plans to Spend $5 Billion on Fab 28 Expansion in Israel
- Intel Submits Ireland Fab Expansion Plan: $8 Billion Price Tag, With a 4 Year Lead Time
- Intel Details Plans for Its Oregon Fab Expansion: D1X Phase 3
- Intel to Expand Production Capacities at Multiple Fabs
Source: Intel








237 Comments
View All Comments
ZolaIII - Thursday, May 9, 2019 - link
All of those (N7, N7+, N6, Samsung 7 nm, 5 nm) are the "7 nm" (10 really) with denser rooting libs. I also noted how TSMC N5 is a comply new node. F*ck the theory I calculated based on primary T9 lib or better say split Intels high performance lib in half to match real difference per gate. What good is theoretical density when Intel node's won't ever see anything other than HP lib? TSMC is also behind in GAA and FF isn't beneficial (much) any more in many aspects (power consumption, performance basically leaking to much). TSMC 5 nm is a win regarding density but unfortunately they don't manufacture SRAM where this win would pay out the most, its not beneficial for HP but they could win big times if they menage to score GPU & FPGA contracts along with top mobile phone SoC's...ajc9988 - Thursday, May 9, 2019 - link
What are you talking that FF isn't useful anymore? GAA doesn't get used until around 3nm TSMC and Samsung (5nm if it really must be used), but they are also looking at ways to incorporate FF into SoS structures. Also, TSMC manufactures both AMD and Nvidia GPUs at the moment. They manufacture AMD's upcoming CPUs. They have been doing high powered ARM products for ARM servers for years.So WTH are you talking about?
ZolaIII - Friday, May 10, 2019 - link
Things you actually need brains to understand.FinFET never whose good for many things to start with. Whosent good for analogue at all nor mixed circuit's for that matter which means not good for transceivers, MOSFET's cetera. It whose an Intel's child all together on the quest & design methodology to ensure peak higher possible clocks, two fins instead one. Does that sound familiar & then let's tie even more fets together (high performance lib) to ensure even better drain so that pore thing could hit even more MHz. The strategy whose wrong from beginning all together. FinFET brought a modest bump (200 MHz) over the planar in terms of what is industrialy considerd as sustainable leak for a complex structure as transistor but with an almost 2x power cost in a idle state it also enabled higher density of around 20~25% compared to planar in terms of possible miniaturisation but again with much higher both design and manufacturing costs. The AMD's (& IBM's also) idea originally with SOI whose much better one overlay but they didn't had enough money to push it to the end so didn't the Global foundries. It remains to be seen how good will Gate All Around be but FinFET really needs to die for many reasons.
Arsenica - Wednesday, May 8, 2019 - link
One word: heatYou cannot really compare a mobile chip with a power consumption of >5W to a 150W server chip. When the transistor count for AMD's 7nm and Intel's 10nm chips are released you will see that their density is comparable.
name99 - Wednesday, May 8, 2019 - link
This would be rather more convincing if Intel didn't ALSO make 5W chips...Which have very similar (low...) densities:
https://en.wikichip.org/wiki/intel/microarchitectu...
RSAUser - Thursday, May 9, 2019 - link
The main problem there is that the architecture for their mobile chips is based on the desktop one; it's basically an optimized desktop chip with way lower power limits, so not really comparable.The mobile SoC are basically 5W for the entire thing, with 5W basically being max draw, while Intel's one is usually just the CPU and GPU together going to 5W.
Then take into account performance differences, density isn't everything, but it sure does help a lot.
name99 - Thursday, May 9, 2019 - link
(a) "it's basically an optimized desktop chip with way lower power limits "Whose fault is that? Apple manages to design three rather different CPU cores just for 2018 (Vortex, Tempest, Chinook). There is nothing STOPPING Intel from a better, more appropriate, design for their low power end, obtained through a recompile of their higher end microarchitecture!
(b) If even Intel's lowest power actually shipping cores don't really use that 100MTr/mm^2 metric, then WHY THE FSCK is it Intel's metric of choice?
I don't go around telling the world repeatedly that real soon now I'll be running a 4 minute mile, then when someone calls me out, say "Well, I'm not really a runner you know, I actually spend all my time reading and using my computer"!
Arsenica - Thursday, May 9, 2019 - link
"There is nothing STOPPING Intel from a better, more appropriate, design for their low power end,"Actually: Economics
Developing a new process with low power metal layers for a ultra-low volume part makes no financial sense to Intel. The Pentium 4405Y is the only part with a >7W TDP and that was a chromebook-only part, so it doesn't even make sense to make the die smaller as a chromebook has plenty of PCB space for a less dense chip.
if some phone manufacturer were to select such part then it may make sense to actually make the die physically smaller, but as X86 never caught as a phone architecture then Intel has no financial incentive to satisfy your MT/mm^2 fetishism.
ZolaIII - Friday, May 10, 2019 - link
Lack of brain stops them... Switch to UHD lib from HP one makes 2.5x increase in MT/mm² & with it more than sizable price reduction per functional die & power reduction more than 2x.It's not a "new" anything, just software lib and design approach. The cost is it won't be working on 4+ GHz but it will happily work on 2 GHz and top at around 3 GHz which is more then enough for anything mobile.Irata - Thursday, May 9, 2019 - link
Curious what the density of Radeon VII is - that is a very large high TDP chip on TSMC 7nm.