The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTDeepBench Training: Convolutions
Moving on to DeepBench's convolutions training workloads, we should see tensor cores significantly accelerate performance once again. Given that convolutional layers are essentially standard for image recognition and classification, convolutions are one of the biggest potential beneficiaries of tensor core acceleration.
Taking the average of all tests, we again see Volta's mixed precision (FP16 with tensor cores enabled) taking the lead. Unlike with GEMM, enabling tensors on FP32 convolutions results in a tangible performance penalty.
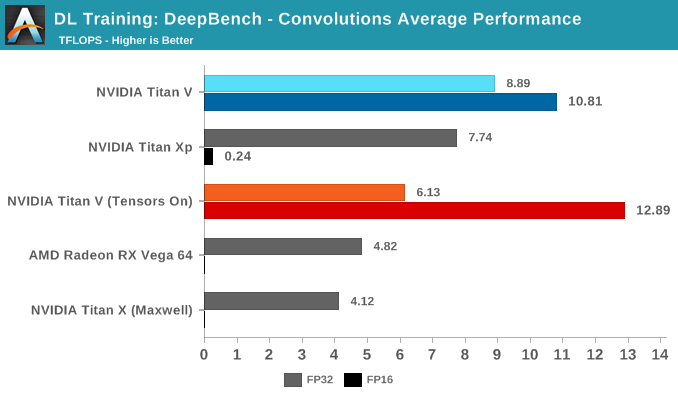
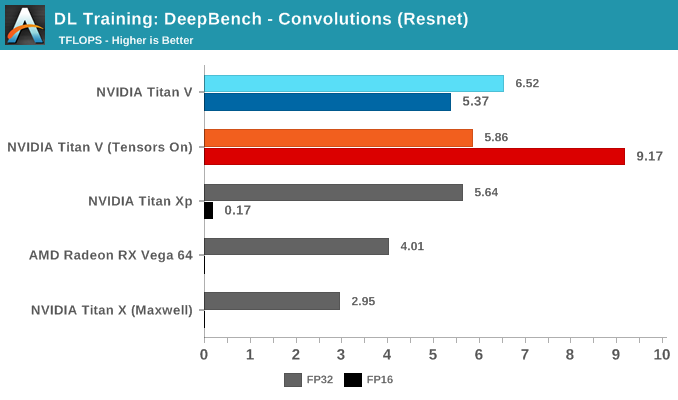
Breaking the tests out by application does not particularly clarify matters. It's only when we return to the DeepBench convolution kernels that we get a little more detail. Performance drops for both mixed precision modes when computations involve ill-matching tensor dimensions, and while standard precision modes follow a cuDNN-specified fastest forward algorithm, such as Winograd, the mixed precision modes are obliged to use implicit precomputed GEMM for all kernels.
To qualify for tensor core acceleration, both input and output channel dimensions must be a multiple of eight, and the input, filter, and output data-types must be half precision. Without going too deep into detail, the implementation of convolution acceleration with tensor cores requires tensors to be in a NHWC format (Number-Height-Width-Channel), but DeepBench, and most frameworks, expect NCHW formatted tensors. In this case, the input channels are not multiples of eight, but DeepBench does automatic padding to account for this.
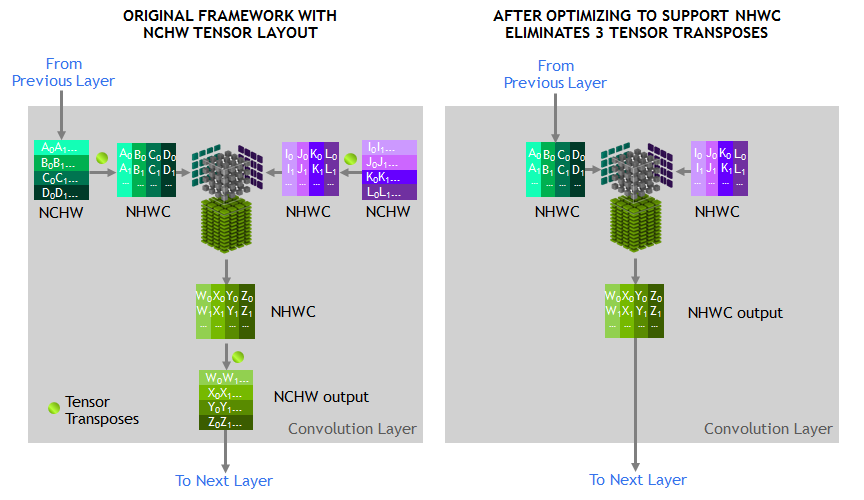
The other factor is that all these NCHW kernels would require transposition to NHWC, which NVIDIA has noted takes up appreciable runtime once convolutions are accelerated. This would affect both FP32 and FP16 mixed precision modes.
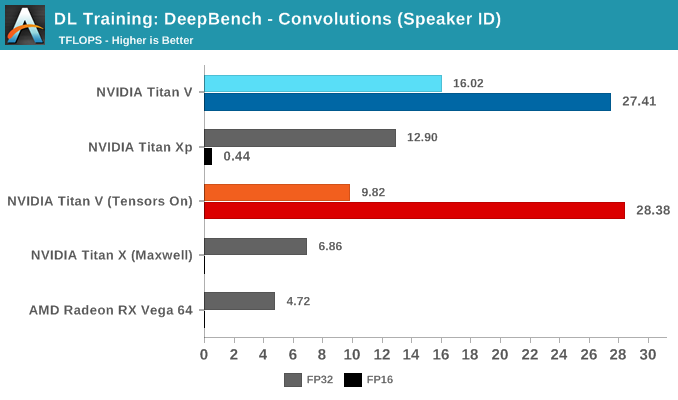
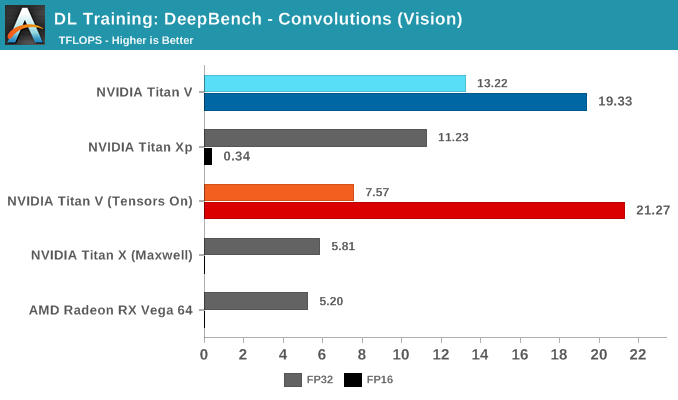
Convolutions still have to be adjusted correctly to benefit from tensor core acceleration. As DeepBench uses the NVIDIA-supplied libraries and makefiles, it's interesting that the standard behavior here would be to force tensor core use at all times.








65 Comments
View All Comments
krazyfrog - Saturday, July 7, 2018 - link
I don't think so.https://www.anandtech.com/show/12170/nvidia-titan-...
mode_13h - Saturday, July 7, 2018 - link
Yeah, I mean why else do you think they built the DGX Station?https://www.nvidia.com/en-us/data-center/dgx-stati...
They claim "AI", but I'm sure it was just an excuse they told their investors.
keg504 - Tuesday, July 3, 2018 - link
"With Volta, there has little detail of anything other than GV100 exists..." (First page)What is this sentence supposed to be saying?
Nate Oh - Tuesday, July 3, 2018 - link
Apologies, was a brain fart :)I've reworked the sentence, but the gist is: GV100 is the only Volta silicon that we know of (outside of an upcoming Drive iGPU)
junky77 - Tuesday, July 3, 2018 - link
ThanksAny thoughts about Google TPUv2 in comparison?
mode_13h - Tuesday, July 3, 2018 - link
TPUv2 is only 45 TFLOPS/chip. They initially grabbed a lot of attention with a 180 TFLOPS figure, but that turned out to be per-board.I'm not sure if they said how many TFLOPS/w.
SirPerro - Thursday, July 5, 2018 - link
TPUv3 was announced in May with 8x the performance of TPUv2 for a total of a 1 PF per podtuxRoller - Tuesday, July 3, 2018 - link
Since utilization is, apparently, an issue with these workloads, I'm interested in seeing how radically different architectures, such as tpu2+ and the just announced ibm ai accelerator (https://spectrum.ieee.org/tech-talk/semiconductors... which looks like a monster.MDD1963 - Wednesday, July 4, 2018 - link
4 ordinary people will buy this....by mistake, thinking it is a gamer. :)philehidiot - Wednesday, July 4, 2018 - link
"With DL researchers and academics successfully using CUDA to train neural network models faster, it was only a matter of time before NVIDIA released their cuDNN library of optimized deep learning primitives, of which there was ample precedent with the HPC-focused BLAS (Basic Linear Algebra Subroutines) and corresponding cuBLAS. So cuDNN abstracted away the need for researchers to create and optimize CUDA code for DL performance. As for AMD’s equivalent to cuDNN, MIOpen was only released last year under the ROCm umbrella, though currently is only publicly enabled in Caffe."Whatever drugs you're on that allow this to make any sense, I need some. Being a layman, I was hoping maybe 1/5th of this might make sense. I'm going back to the porn. </headache>