The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTDeepBench Training: GEMM and RNN
Opening up our DeepBench results are GEMM tests, which we've already seen as pure synthetic operations. Using kernels and GEMM operations used in certain deep learning applications (DeepSpeech, Speaker ID, and Language Modelling), performance here is a little more representative than running through pure matrix-matrix multiplications in cuBLAS.
To preface, the NVIDIA Titan Xp has crippled half precision, while the GeForce GTX Titan X (Maxwell) only supports single precision. According to Baidu, they test a FP32 with tensor cores mode for Volta, where 32-bit inputs undergo 16-bit multiplication and 32-bit accumulation. The specifics of this are somewhat unclear, but we've gone ahead and included those results. Otherwise, FP16 with tensor cores is the 'standard' Volta mixed precision.
The average results of all sub-tests seem unsurprising: enabling tensor cores results in large performance increases all around. Digging into the details reveals just how specific tensor core acceleration is to certain types of matrix-matrix multiplications.
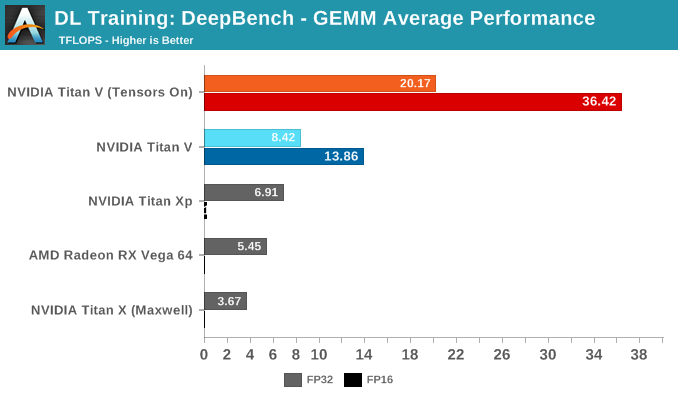
Splitting up the GEMM tests by DL application, we can start to see how tensor cores fare in ideal (and non-ideal) circumstances.
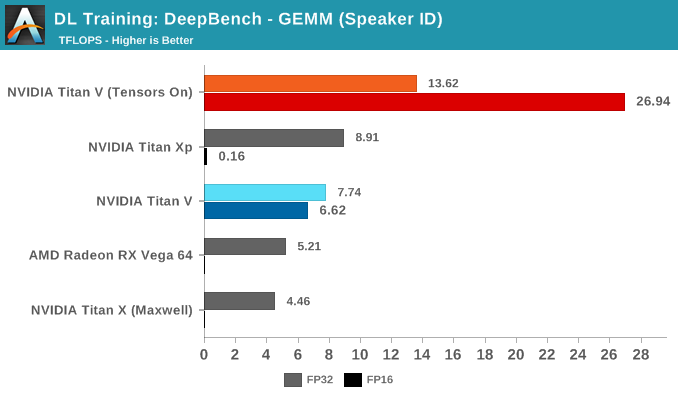
The Speaker ID GEMM workloads actually consist of only two kernels, where a difference of 10 microseconds means a difference of around 1 TFLOPS. The Titan Xp's higher performance is normal variance.
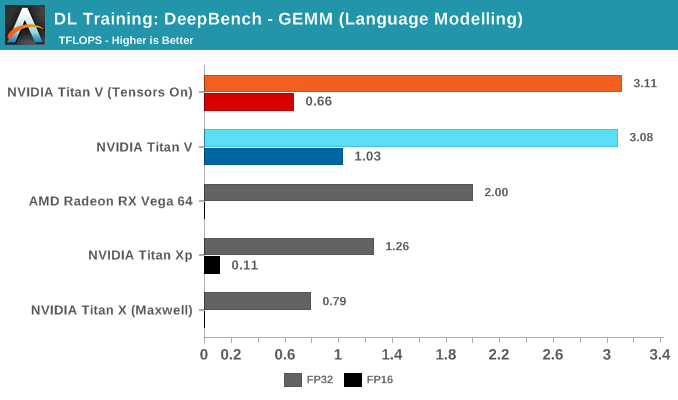
Looking into the Language Modelling kernels explains the poor performance of tensor cores. The sizes of those kernel matrices are m = 512 or 1024, n = 8 or 16, and k = 500000, and the small size of n compared to the very large k is notable. While each number is technically divisible by 8 – one of the basic requirements to qualify for tensor core acceleration – the shape of these matrices isn't a neat fit with the supported basic WMMA shapes: 16x16x16, 32x8x16, and 8x32x16. Nor does it go well with 8x8x8, if we're assuming that tensor cores truly operate on an independent 8x8x8 level.

So tensor cores are being pulled into action on very lopsided matrices that can't be broken up easily as n = 8 or 16, at least, not without performance penalties.
Meanwhile, the tensor cores have runaway performance on DeepSpeech kernels:
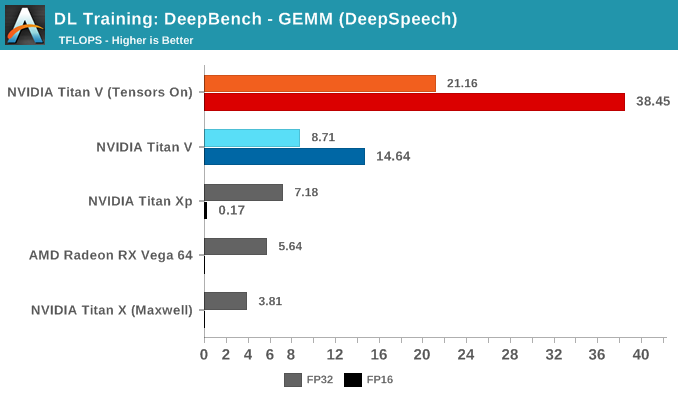
As an average, it turns out to be an impressive number of TFLOPs. Granularly, the same impact of wrong-proportioned matrices is occuring. When matrices fit the tensor core proportions, performance can jump to more than 90 TFLOPS. When they don't, and the right transpositions are not in play, then performances can drop to below 1 TFLOPS.
For the DeepBench RNN kernels, there is no drastic divergence between RNN type. But within in each RNN type, the same patterns can be seen if judging kernel-by-kernel.
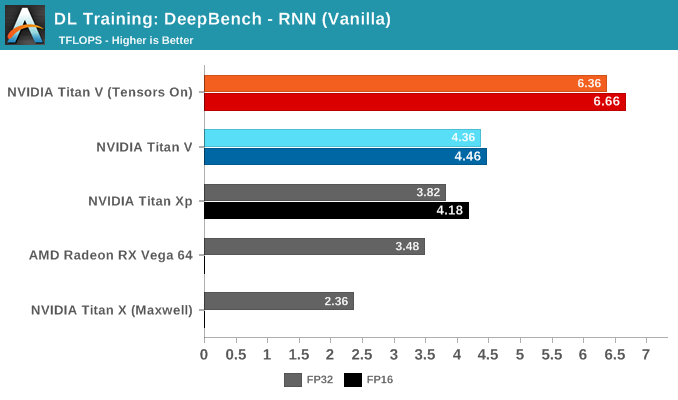
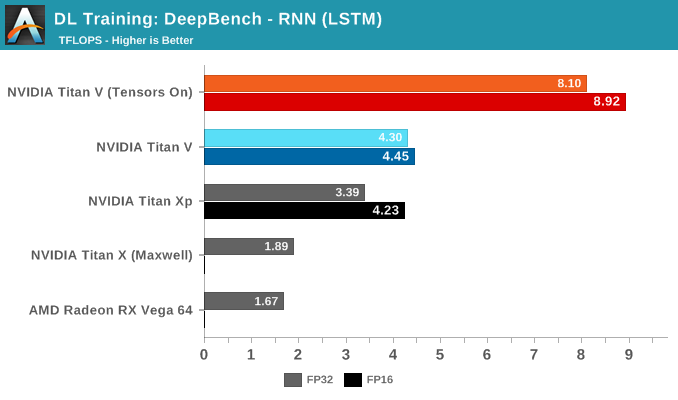
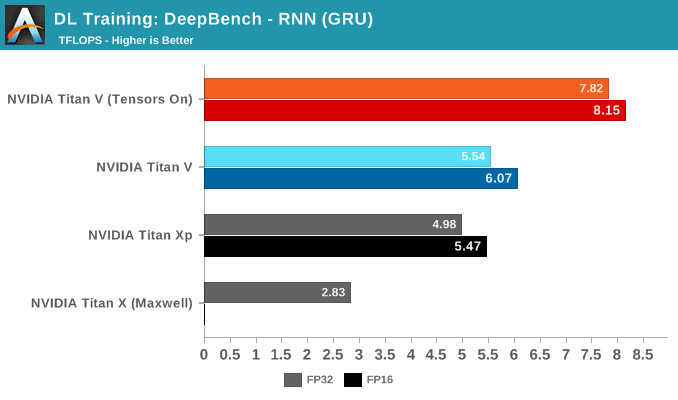
What is interesting is how close the Titan Xp can come to non-tensor core accelerated Titan V performance. We know that the Titan Xp's superior clockspeeds are doing it a favor here, but also one of Titan V's big advantages – HBM2 – is partially mitigated by its 3 controller configuration. Bandwidth-to-bandwidth, the Titan V only has theoretically around 100GB/s more, but at the same amount of VRAM; and while Volta's HBM controller efficiency has improved over Pascal P100, Titan Xp presumably features NVIDIA's 2nd generation GDDR5X controller.








65 Comments
View All Comments
SirCanealot - Tuesday, July 3, 2018 - link
No overclocking benchmarks. WAT. ¬_¬ (/s)Thanks for the awesome, interesting write up as usual!
Chaitanya - Tuesday, July 3, 2018 - link
This is more of an enterprise product for consumers so even if overclocking it enabled its something that targeted demographic is not going to use.Samus - Tuesday, July 3, 2018 - link
woooooooshMrSpadge - Tuesday, July 3, 2018 - link
He even put the "end sarcasm" tag (/s) to point out this was a joke.Ticotoo - Tuesday, July 3, 2018 - link
Where oh where are the MacOS drivers? It took 6 months to get the pascal Titan drivers.Hopefully soon
cwolf78 - Tuesday, July 3, 2018 - link
Nobody cares? I wouldn't be surprised if support gets dropped at some point. MacOS isn't exactly going anywhere.eek2121 - Tuesday, July 3, 2018 - link
Quite a few developers and professionals use Macs. Also college students. By manufacturer market share Apple probably has the biggest share, if not then definitely in the top 5.mode_13h - Tuesday, July 3, 2018 - link
I doubt it. Linux rules the cloud, and that's where all the real horsepower is at. Lately, anyone serious about deep learning is using Nvidia on Linux. It's only 2nd-teir players, like AMD and Intel, who really stand anything to gain by supporting niche platforms like Macs and maybe even Windows/Azure.Once upon a time, Apple actually made a rackmount OS X server. I think that line has long since died off.
Freakie - Wednesday, July 4, 2018 - link
Lol, those developers and professionals use their Macs to remote in to their compute servers, not to do any of the number crunching with.The idea of using a personal computer for anything except writing and debugging code is next to unheard of in an environment that requires the kind of power that these GPUs are meant to output. The machine they use for the actual computations are 99.5% of the time, a dedicated server used for nothing but to complete heavy compute tasks, usually with no graphical interface, just straight command-line.
philehidiot - Wednesday, July 4, 2018 - link
If it's just a command line why bother with a GPU like this? Surely integrated graphics would do?(Even though this is a joke, I'm not sure I can bear the humiliation of pressing "submit")