The NVIDIA Titan V Preview - Titanomachy: War of the Titans
by Ryan Smith & Nate Oh on December 20, 2017 11:30 AM ESTCompute Performance: Geekbench 4
In the most recent version of its cross-platform Geekbench benchmark suite, Primate Labs added CUDA and OpenCL GPU benchmarks. This isn’t normally a test we turn to for GPUs, but for the Titan V launch it offers us another perspective on performance.
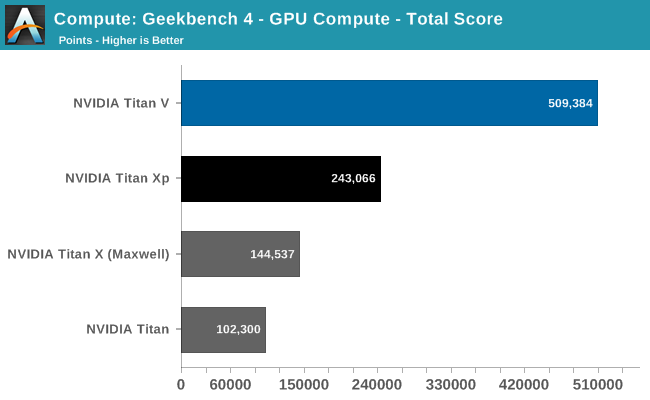
The results here are interesting. We’re not the only site to run Geekbench 4, and I’ve seen other sites with much different scores. But as we haven’t used this benchmark in great depth before, I’m hesitant to read too much into it. What it does show us, at any rate, is that the Titan V is well ahead of the Titan Xp here, more than doubling the latter’s score.
| NVIDIA Titan Cards GeekBench 4 Subscores | ||||||
| Titan V | Titan Xp | GTX Titan X | GTX Titan | |||
| Sobel (GigaPixels per second) |
35.1 | 24.9 | 16.5 | 9.4 | ||
| Histogram Equalization (GigaPixels per second) |
21.2 | 9.43 | 5.58 | 4.27 | ||
| SFFT (GFLOPS) |
180 | 136.5 | 83 | 60.3 | ||
| Gaussian Blur (GigaPixels per second) |
23.9 | 2.67 | 1.57 | 1.45 | ||
| Face Detection (Msubwindows per second) |
21.7 | 12.4 | 8.66 | 4.92 | ||
| RAW (GigaPixels per second) |
18.2 | 10.8 | 5.63 | 4.12 | ||
| Depth of Field (GigaPixels per second) |
3.31 | 2.74 | 1.35 | 0.72 | ||
| Particle Physics (FPS) |
83885 | 30344 | 18725 | 18178 | ||
Looking at the subscores, the Titan V handily outperforms the Titan Xp on all of the subtests. However it’s one test in particular that stands out here, and is likely responsible for the huge jump in the overall score, and that’s the Gaussian Blur, where the Titan V is 9x (!) faster than the Titan Xp. I am honestly not convinced that this isn’t a driver or benchmark bug of some sort, but it may very well be that Primate Labs has hit on a specific workload or scenario that sees some rather extreme benefits from the Volta architecture.
Folding @ Home
Up next we have the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, giving us a good opportunity to let Titan V flex its FP64 muscles.
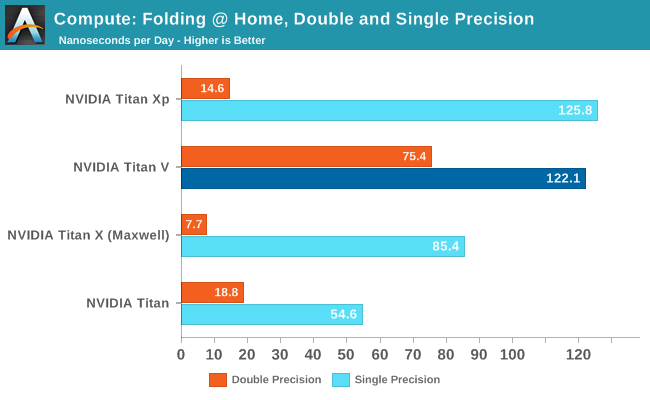
A CUDA-backed benchmark, this is the first sign that Titan V’s performance lead over the Titan Xp won’t be consistent. And more specifically that existing software and possibly even NVIDIA’s drivers aren’t well-tuned to take advantage of the Volta architecture just yet.
In this case the Titan V actually loses to the Titan Xp ever so slightly. The scores are close enough that this is within the usual 3% margin of error, which is to say that it’s a wash overall. But it goes to show that Titan V isn’t going to be an immediate win everywhere for existing software.
CompuBench
Our final set of compute benchmarks is another member of our standard compute benchmark suite: CompuBench 2.0, the latest iteration of Kishonti's GPU compute benchmark suite. CompuBench offers a wide array of different practical compute workloads, and we’ve decided to focus on level set segmentation, optical flow modeling, and N-Body physics simulations.
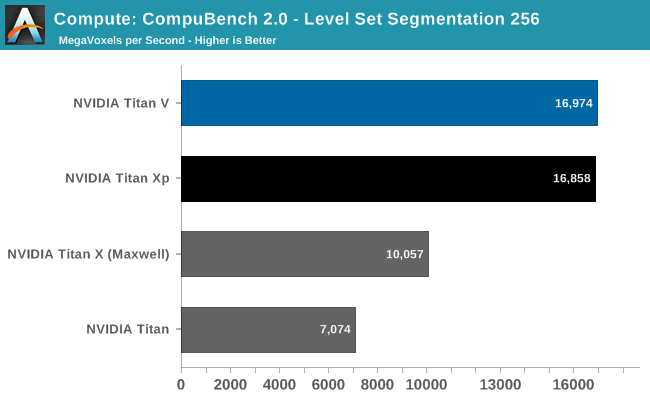
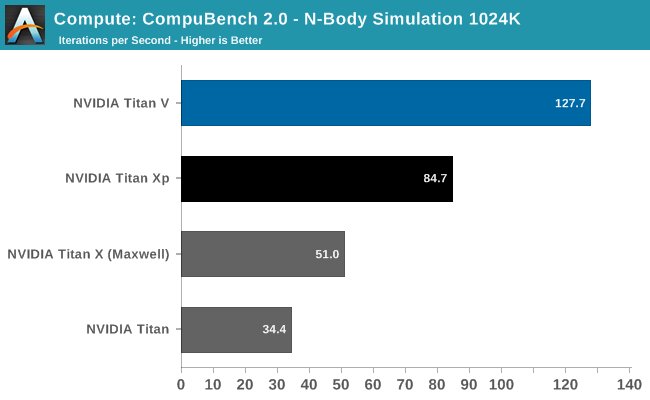
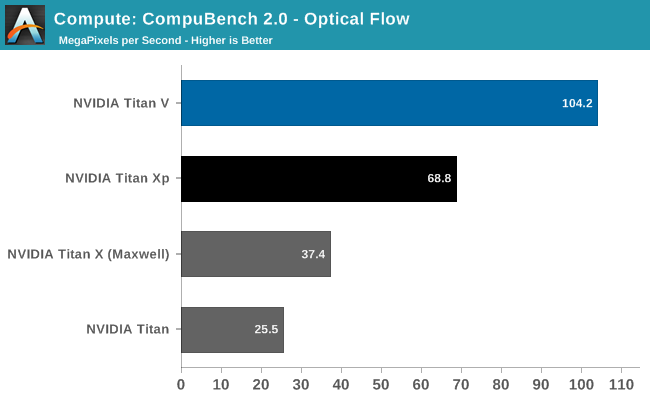
It’s interesting how the results here are all over the place. The Titan V shows a massive performance improvement in both N-Body simulations and Optical Flow, once again leading to the Titan V punching well above its weight. But then the Level Set Segmentation benchmark is practically tied with the Titan Xp. Suffice it to say that this puts the Titan V in a great light, and conversely makes one wonder how the Titan Xp was (apparently) so inefficient. The flip side is that it’s going to be a while until we fully understand why certain workloads seem to benefit more from Volta than other workloads.








111 Comments
View All Comments
maroon1 - Wednesday, December 20, 2017 - link
Correct if I'm wrong, Crysis warhead running 4K with 4xSSAA means it is running 8K (4 times as much as 4K) and then downscale to 4KRyan Smith - Wednesday, December 20, 2017 - link
Yes and no. Under the hood it's actually using a rotated grid, so it's a little more complex than just rendering it at a higher resolution.The resource requirements are very close to 8K rendering, but it avoids some of the quality drawbacks of scaling down an actual 8K image.
Frenetic Pony - Wednesday, December 20, 2017 - link
A hell of a lot of "It works great but only if you buy and program exclusively for Nvidia!" stuff here. Reminds me of Sony's penchant for exclusive lock in stuff over a decade ago when they were dominant. Didn't work out for Sony then, and this is worse for customers as they'll need to spend money on both dev and hardware.I'm sure some will be shortsighted enough to do so. But with Google straight up outbuying Nvidia for AI researchers (reportedly up to, or over, 10 million for just a 3 year contract) it's not a long term bet I'd make.
tuxRoller - Thursday, December 21, 2017 - link
I assumed you've not heard of CUDA before?NVIDIA had long been the only game in town when it comes to gpgpu HPC.
They're really a monopoly at this point, and researchers have no interest in making they're jobs harder by moving to a new ecosystem.
mode_13h - Wednesday, December 27, 2017 - link
OpenCL is out there, and AMD has had some products that were more than competitive with Nvidia, in the past. I think Nvidia won HPC dominance by bribing lots of researchers with free/cheap hardware and funding CUDA support in popular software packages. It's only with Pascal that their hardware really surpassed AMD's.tuxRoller - Sunday, December 31, 2017 - link
Ocl exists but cuda has MUCH higher mindshare. It's the de facto hpc framework used and taught in schools.mode_13h - Sunday, December 31, 2017 - link
True that Cuda seems to dominate HPC. I think Nvidia did a good job of cultivating the market for it.The trick for them now is that most deep learning users use frameworks which aren't tied to any Nvidia-specific APIs. I know they're pushing TensorRT, but it's certainly not dominant in the way Cuda dominates HPC.
tuxRoller - Monday, January 1, 2018 - link
The problem is that even the gpu accelerated nn frameworks are still largely built first using cuda. torch, caffe and tensorflow offer varying levels of ocl support (generally between some and none).Why is this still a problem? Well, where are the ocl 2.1+ drivers? Even 2.0 is super patchy (mainly due to nvidia not officially supporting anything beyond 1.2). Add to this their most recent announcements about merging ocp into vulkan and you have yourself an explanation for why cuda continues to dominate.
My hope is that khronos announce vulkan 2.0, with ocl being subsumed, very soon. Doing that means vendors only have to maintain a single driver (with everything consuming spirv) and nvidia would, basically, be forced to offer opencl-next. Bottom-line: if they can bring the ocl functionality into vulkan without massively increasing the driver complexity, I'd expect far more interest from the community.
mode_13h - Friday, January 5, 2018 - link
Your mistake is focusing on OpenCL support as a proxy for AMD support. Their solution was actually developing OpenMI as a substitute for Nvidia's cuDNN. They have forks of all the popular frameworks to support it - hopefully they'll get merged in, once ROCm support exists in the mainline Linux kernel.Of course, until AMD can answer the V100 on at least power-effeciency grounds, they're going to remain an also-ran, in the market for training. I think they're a bit more competitive for inferencing workloads, however.
CiccioB - Thursday, December 21, 2017 - link
What are you suggesting?GPU are a very customized piece of silicon and you have to code for them with optimization for each single architecture if you want to exploit them at the maximum.
If you think that people buy $10.000 cards to be put in $100.000 racks for a multiple $1.000.000 server just to use open source not optimized not supported not guarantee code in order to make AMD fanboys happy, well, not, it's not like the industry works.
Grow up.