The NVIDIA Titan V Preview - Titanomachy: War of the Titans
by Ryan Smith & Nate Oh on December 20, 2017 11:30 AM ESTCompute Performance
Diving in, I want to start with a look at compute performance. Titan V is first and foremost a compute product, so what makes or breaks the card – what justifies its existence – is how well it does at compute.
This is actually a more challenging aspect to test than it may first appear, as NVIDIA’s top-down architecture launch strategy means that there’s not a lot of commercial or otherwise widely-used software written that can take full advantage of the Volta architecture. Even in the major deep learning frameworks, their support for Volta is still in the early phases or still under active development. So I’ve opted to excise the deep learning tests for the moment, while we get a better handle on those for our full review. Meanwhile software that can take advantage of Volta’s fast FP16 and FP64 modes is also quite rare, especially as fast FP16 is not a consumer NVIDIA feature at this time.
Compute overall is harder to test, as unlike games or even professional visualization tasks, there’s far fewer standard workloads. Even tasks using major compute frameworks are often heavily tailored towards a specific need. So while our compute benchmarks are meant to be enlightening, software developers and compute users will want to carefully study how their workloads map to GPU hardware.
Anyhow, before we get too deep here, I want to take a quick look at FMA latency. Over successive generations of GPU architectures NVIDIA has continued to find ways to reduce the latency of what’s perhaps the most critical instruction in the GPU space, and Volta continues this trend.
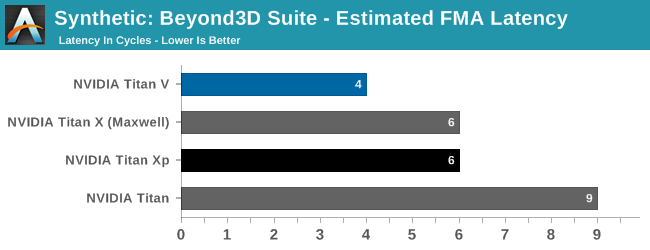
With Volta NVIDIA has been able to knock another two clock cycles off of the latency for an FMA, reducing it from 6 cycles on Pascal/Maxwell to 4 cycles. This is thanks to NVIDIA’s separating the INT32 and FP32 units in the Volta architecture, which allows more of the overall FMA operation to be performed in parallel. The end result is that for any instructions that depend on the result of an FMA operation, they can kick off 33% sooner, improving overall compute/shader efficiency.
Interestingly this was one area of compute where NVIDIA was trailing AMD – who has an average latency of around 4.5 cycles – so it’s great to see NVIDIA close the gap here. And this shouldn’t be considered a trivial change, as reducing the number of clock cycles for any fundamental operation is quite difficult. Case in point, I’m not sure just how NVIDIA could get FMAs any lower than 4 cycles.
General Matrix Multiply (GEMM) Performance
Starting things off, let’s take a look at General Matrix Multiply (GEMM) performance. GEMM measures the performance of dense matrix multiplication, which is an important operation in a variety of scientific fields. GEMM is highly parallel and typically compute heavy, and one of the first tests of performance and efficiency on any parallel architecture geared towards HPC workloads.
Since matrix multiplication is such a fundamental operation, it’s one of the operations included in NVIIDA’s CUBLAS library, meaning NVIDIA offers a highly optimized version of the function. Importantly, it also means that NVIDIA offers Volta-optimized implementations of the function, including operations that run on the densest matrix multiplication core of them all, the tensor core. So GEMM provides us a fantastic opportunity to look at the performance of not only the usual FP16/FP32/FP64 operations, but also the FP16 tensor cores themselves. This is very much an ideal case, but it gives us the means to see what kind of maximum throughput Titan V can reach.
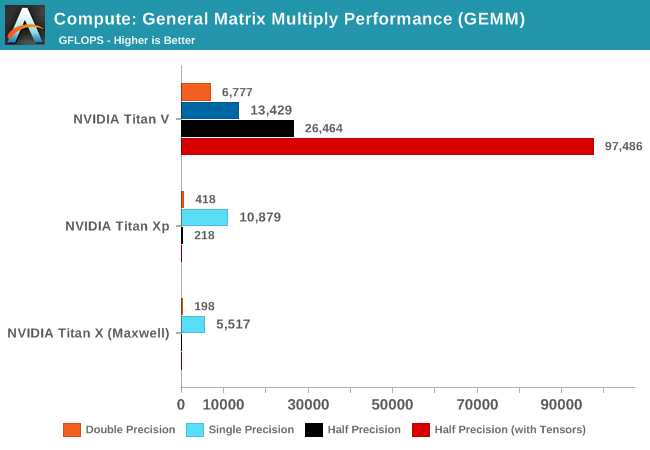
Burying the lede here, let’s start with single precision (FP32) performance. As mentioned briefly in our look at the specifications of the Titan V, the Titan V is not immensely more powerful than the Titan Xp when it comes to standard FP32 operations. It has a much greater number of FP32 CUDA cores, but the compute-centric chip trades that off with lower average clockspeeds, which dulls the difference some.
None the less, the Titan V is 23% faster in FP32 GEMM, which is actually a greater improvement than the 14% increase that we’d expect going by the specifications. In fact at 13.4 TFLOPS, the Titan V is at 97% of its rated 13.8 TFLOPS FP32 performance, an amazingly efficient metric. The Titan Xp isn’t as efficient here – hitting 10.9 of 12.1 TFLOPs for a 90% rating – underscoring the important architectural improvements Volta brings. I am not 100% sure on just which factors lead to this improvement, but the separation of INT32 and FP32 cores along with the scheduling changes are likely candidates. Titan V also benefits from improvements in caching and more memory bandwidth, which further reduces any potential bottlenecks in feeding the beast.
As for double precision (FP64) and half precision (FP16) performance, these are in line with our expectations. The official FP64 and FP16 rates for Titan V are 1:2 and 2:1 FP32 respectively, and this is what we find on GEMM. Compared to the Titan Xp, which didn’t offer fast FP64 or FP16 modes, the difference is night and day: Titan V is 16x and 121x faster respectively.
Last but not least, let’s talk tensors. I almost removed the tensor core results from this graph, but ultimately I left them in to highlight just what the tensor cores mean for compute developers who have tasks well-suited for them. When configured to use the tensor cores, our GEMM benchmark runs hit 97.5 TFLOPs, 3.7x faster than Titan V’s already fast FP16 performance. Or to put this another way, this one card is doing 97 trillion floating point operations in a single second.
Relative to the high efficiency marks we saw earlier with the CUDA cores, the tensor cores don’t come quite as close. 97.5 TFLOPs is about 89% of the Titan V’s rated 110 TFLOPs tensor core performance. Besides the fact that the tensor cores are extremely dense – they’ll give your power and cooling a good run for their money – I suspect that Titan V is feeling the pinch of memory bandwidth. The loss of a stack of HBM2 means that it’s trying to perform trillions of operations on only billions of bytes of memory bandwidth.
Finally, I can’t reiterate enough that when looking at tensor core performance, context is king here. The tensor cores are very fast, but they are highly specialized. GPUs in general are only good for a subset of overall computing tasks, and the tensor cores take that one step further. In super dense matrix multiplication scenarios they excel, but they have little to offer outside of that. Thankfully for NVIDIA and its newly found deep learning empire, neural networks map very well to tensor operations.
SiSoftware Sandra
Moving on from our low-level GEMM benchmark, let’s move up a level to something a bit more practical with some of SiSoftware’s Sandra’s GPU compute benchmarks. Unfortunately for reasons I haven’t yet been able to determine, Sandra’s CUDA benchmarks aren’t working with NVIDIA’s latest drivers, which limits us to working with OpenCL and DirectX compute shaders. Still, this gives us a chance a look at performance outside of specialized CUDA applications.
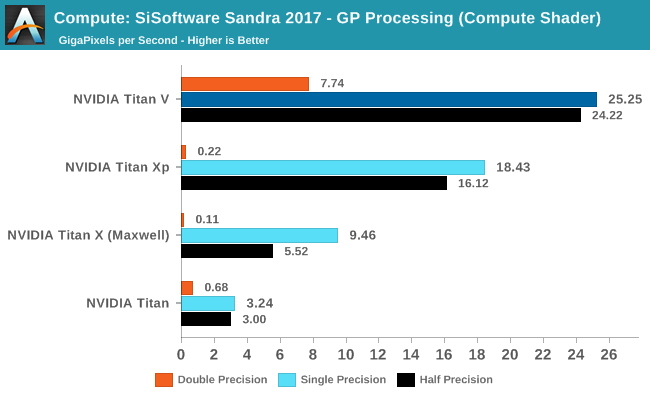
Relatively speaking, Titan V once again punches above its weight. In FP32 mode Sandra’s compute shader benchmark clocks the card as processing 25 Gigapixels per second, versus 18.4 for the Titan Xp, a 37% difference and once again exceeding the on-paper differences between these products. I suggest caution in reading too much into these synthetic compute results, as real-world workloads aren’t nearly as neat and tidy. But it continues to point to the Volta architecture having improved things by quite a bit under the hood.
Meanwhile, because NVIDA doesn’t expose fast FP16 mode outside of CUDA, the Titan V’s FP16 performance doesn’t get used to its fullest extent here. Fast FP64 on the other hand is exposed, and Titan V leaves every other Titan in the dust.

The story is much the same using DX11 video (pixel) shaders. Though it’s very interesting that Titan V isn’t showing the same kind of sizable performance gains here as it did using a compute shader.
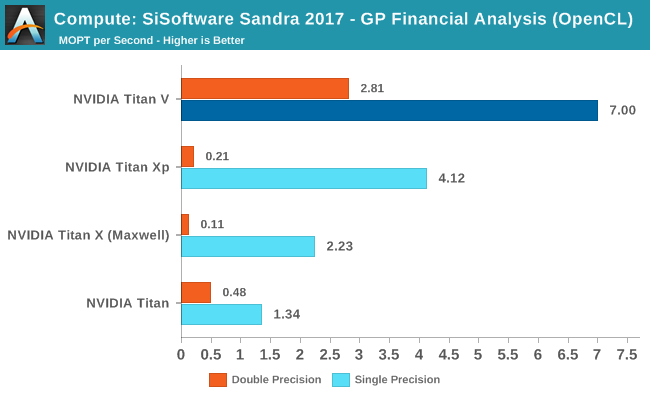
A bit more real-world is Sandra’s financial analysis benchmark, which performs a series of operations including the ever-important Monte Carlo simulation. Titan V is once again well in the lead here, punching above its weight relative to the Titan Xp. FP64 performance is also much stronger than the other Titans, though on a relative basis, the performance drop-off for moving to FP64 is much more than the 50% performance hit that we’d expect on paper.








111 Comments
View All Comments
maroon1 - Wednesday, December 20, 2017 - link
Correct if I'm wrong, Crysis warhead running 4K with 4xSSAA means it is running 8K (4 times as much as 4K) and then downscale to 4KRyan Smith - Wednesday, December 20, 2017 - link
Yes and no. Under the hood it's actually using a rotated grid, so it's a little more complex than just rendering it at a higher resolution.The resource requirements are very close to 8K rendering, but it avoids some of the quality drawbacks of scaling down an actual 8K image.
Frenetic Pony - Wednesday, December 20, 2017 - link
A hell of a lot of "It works great but only if you buy and program exclusively for Nvidia!" stuff here. Reminds me of Sony's penchant for exclusive lock in stuff over a decade ago when they were dominant. Didn't work out for Sony then, and this is worse for customers as they'll need to spend money on both dev and hardware.I'm sure some will be shortsighted enough to do so. But with Google straight up outbuying Nvidia for AI researchers (reportedly up to, or over, 10 million for just a 3 year contract) it's not a long term bet I'd make.
tuxRoller - Thursday, December 21, 2017 - link
I assumed you've not heard of CUDA before?NVIDIA had long been the only game in town when it comes to gpgpu HPC.
They're really a monopoly at this point, and researchers have no interest in making they're jobs harder by moving to a new ecosystem.
mode_13h - Wednesday, December 27, 2017 - link
OpenCL is out there, and AMD has had some products that were more than competitive with Nvidia, in the past. I think Nvidia won HPC dominance by bribing lots of researchers with free/cheap hardware and funding CUDA support in popular software packages. It's only with Pascal that their hardware really surpassed AMD's.tuxRoller - Sunday, December 31, 2017 - link
Ocl exists but cuda has MUCH higher mindshare. It's the de facto hpc framework used and taught in schools.mode_13h - Sunday, December 31, 2017 - link
True that Cuda seems to dominate HPC. I think Nvidia did a good job of cultivating the market for it.The trick for them now is that most deep learning users use frameworks which aren't tied to any Nvidia-specific APIs. I know they're pushing TensorRT, but it's certainly not dominant in the way Cuda dominates HPC.
tuxRoller - Monday, January 1, 2018 - link
The problem is that even the gpu accelerated nn frameworks are still largely built first using cuda. torch, caffe and tensorflow offer varying levels of ocl support (generally between some and none).Why is this still a problem? Well, where are the ocl 2.1+ drivers? Even 2.0 is super patchy (mainly due to nvidia not officially supporting anything beyond 1.2). Add to this their most recent announcements about merging ocp into vulkan and you have yourself an explanation for why cuda continues to dominate.
My hope is that khronos announce vulkan 2.0, with ocl being subsumed, very soon. Doing that means vendors only have to maintain a single driver (with everything consuming spirv) and nvidia would, basically, be forced to offer opencl-next. Bottom-line: if they can bring the ocl functionality into vulkan without massively increasing the driver complexity, I'd expect far more interest from the community.
mode_13h - Friday, January 5, 2018 - link
Your mistake is focusing on OpenCL support as a proxy for AMD support. Their solution was actually developing OpenMI as a substitute for Nvidia's cuDNN. They have forks of all the popular frameworks to support it - hopefully they'll get merged in, once ROCm support exists in the mainline Linux kernel.Of course, until AMD can answer the V100 on at least power-effeciency grounds, they're going to remain an also-ran, in the market for training. I think they're a bit more competitive for inferencing workloads, however.
CiccioB - Thursday, December 21, 2017 - link
What are you suggesting?GPU are a very customized piece of silicon and you have to code for them with optimization for each single architecture if you want to exploit them at the maximum.
If you think that people buy $10.000 cards to be put in $100.000 racks for a multiple $1.000.000 server just to use open source not optimized not supported not guarantee code in order to make AMD fanboys happy, well, not, it's not like the industry works.
Grow up.