Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Apache Spark 2.1 Benchmarking
Apache Spark is the poster child of Big Data processing. Speeding up Big Data applications is the top priority project at the university lab I work for (Sizing Servers Lab of the University College of West-Flanders), so we produced a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large amount of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
In previous articles, we tested with Spark 1.5 in standalone mode (non-clustered). That worked out well enough, but we saw diminishing returns as core counts went up. In hindsight, just dumping 300 GB of compressed data in one JVM was not optimal for 30+ core systems. The high core counts of the Xeon 8176 and EPYC 7601 caused serious performance issues when we first continued to test this way. The 64 core EPYC 7601 performed like a 16-core Xeon, the Skylake-SP system with 56 cores was hardly better than a 24-core Xeon E5 v4.
So we decided to turn our newest servers into virtual clusters. Our first attempt is to run with 4 executors. Researcher Esli Heyvaert also upgraded our Spark benchmark so it could run on the latest and greatest version: Apache Spark 2.1.1.
Here are the results:
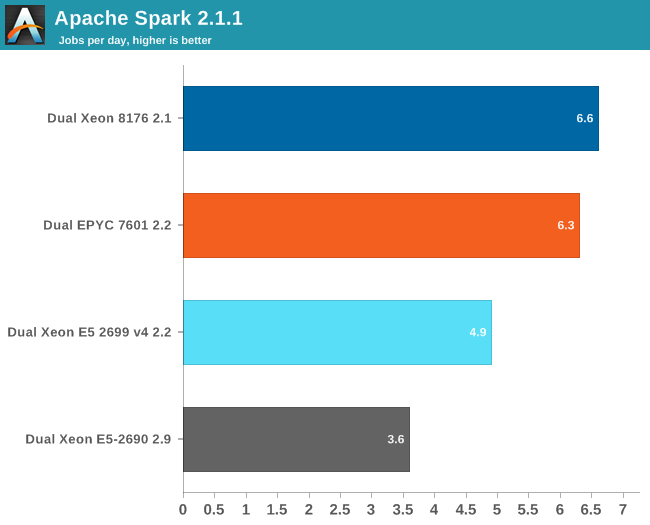
If you wonder who needs such server behemoths besides the people who virtualize a few dozen virtual machines, the answer is Big Data. Big Data crunching has an unsatisfiable hunger for – mostly integer – processing power. Even on our fastest machine, this test needs about 4 hours to finish. It is nothing less than a killer app.
Our Spark benchmark needs about 120 GB of RAM to run. The time spent on storage I/O is negligible. Data processing is very parallel, but the shuffle phases require a lot of memory interaction. The ALS phase does not scale well over many threads, but is less than 4% of the total testing time.
Given the higher clockspeed in lightly threaded and single threaded parts, the faster shuffle phase probably gives the Intel chip an edge of only about 5%.








219 Comments
View All Comments
JKflipflop98 - Wednesday, July 12, 2017 - link
For years I thought you were just really committed to playing the "dumb AMD fanbot" schtick for laughs. It's infinitely more funny now that I know you've actually been *serious* this entire time.ddriver - Wednesday, July 12, 2017 - link
Whatever helps you feel better about yourself ;) I bet it is funny now, that AT have to carefully devise intel biased benches and lie in its reviews in hopes intel at least saves face. BTW I don't have a single amd CPU running ATM.WinterCharm - Thursday, July 13, 2017 - link
Uh, what are you smoking? this is a pretty even piece.boozed - Tuesday, July 11, 2017 - link
You haven't done your job properly unless you've annoyed the fanboys (and perhaps even fangirls) for both sides!JohanAnandtech - Wednesday, July 12, 2017 - link
Wise words. Indeed :-)Ranger1065 - Wednesday, July 12, 2017 - link
If you are referring to ddriver, I agree, wise words indeed.ddriver - Wednesday, July 12, 2017 - link
Well, that assumption rests on the presumption that the point of reviews is to upsed fanboys.I'd say that a "review done right" would include different workload scenarios, there is nothing wrong with having one that will show the benefits of intel's approach to doing server chips, but that should be properly denoted, and should be just one of several database tests and should be accompanied by gigabytes of databases which is what we use in real world scenarios.
CoachAub - Wednesday, July 12, 2017 - link
It was mentioned more than once that this review was rushed to make a deadline and that the suite of benchmarks were not everything they wanted to run and without optimizations or even the usual tweaks an end-user would make to their system. So, keep that in mind as you argue over the tests and different scenarios, etc.ddriver - Thursday, July 13, 2017 - link
It doesn't take a lot of time to populate a larger database so that you can make a benchmark that involves an actual real world usage scenario. It wasn't the "rushing" that prompted the choice of database size...mpbello - Friday, July 14, 2017 - link
If you are rushing, you reduce scope and deliver fewer pieces with high quality instead of insisting on delivering a full set of benchmarks that you are not sure about its quality.The article came to a very strong conclusion: Intel is better for database scenarios. Whatever you do, whether you are rushing or not, you cannot state something like that if the benchmarks supporting your conclusion are not well designed.
So I agree that the design of the DB benchmark was incredibly weak to sustain such an important conclusion that Intel is the best choice for DB applications.