Intel's Process Roadmap to 2025: with 4nm, 3nm, 20A and 18A?!
by Dr. Ian Cutress on July 26, 2021 5:00 PM ESTIntel’s Next Generation Packaging: EMIB and Foveros
Alongside the process node advancements, Intel also has to march forward with next-generation packaging technology. The demand for high performance silicon coupled with increasingly difficult process node development has created an environment where processors are no longer a single piece of silicon, relying on multiple smaller (and potentially optimized) chiplets or tiles to be packaged together in a way that benefits performance, power, and the end product.
Single large chips are no longer the smart business decision – they can end up too difficult to make without defects, or the technology to create them isn’t optimized for any one particular feature on the chip. However, dividing a processor up into separate silicon pieces creates additional barriers to moving data around between those pieces – if the data has to transition from being in silicon to being in something else (such as a package or an interposer) then there is a power cost and latency cost to consider. The tradeoff is optimized silicon built for purpose, such as a logic chip made on a logic process, a memory chip made on a memory process, and the smaller chips often have better voltage/frequency characteristics when binning than their larger counterparts. But underpinning all of this is how the chips are put together, and that requires packaging.
Intel’s two main specialist packaging technologies are EMIB and Foveros. Intel explained the future of both in relation to its future node development.
EMIB: Embedded Multi-Die Interconnect Bridge
Intel’s EMIB technology is designed for chip-to-chip connections when laid out on a 2D plane.
The easiest way for two chips on the same substrate to talk to each other is by taking a datapath through the substrate. The substrate is a printed circuit board made of layers of insulated material interspersed with metal layers etched into tracks and traces. Depending on the quality of the substrate, the physical protocol, and the standard being used, it costs a lot of power to transmit data through the substrate, and bandwidth is reduced. But, this is the cheapest option.
The alternative to a substrate is to put both chips onto an interposer. An interposer is a large piece of silicon, big enough for both chips to wholly fit on to, and the chips are bonded directly to the interposer. Similarly there are data paths put into the interposer, but because the data is being moved from silicon to silicon, the loss of power is not as much as a substrate, and the bandwidth can be higher. The downside to this is that the interposer also has to be manufactured (usually on 65nm), the chips involved have to be small enough to fit, and it can be rather expensive. But, the interposer is a good solution, and active interposers (with built in logic for networking) have yet to be fully exploited).
Intel’s EMIB solution is a combination of both interposer and substrate. Rather than taking a large interposer, Intel uses a small slither of silicon and embeds that directly into the substrate, and Intel calls this a bridge. The bridge is effectively two halves with hundreds or thousands of connections each side, and the chips are built to connect to one half of the bridge. Now both chips are connected to that bridge, having the benefit of transferring data through silicon without the restrictions that a large interposer might bring. Intel can embed multiple bridges between two chips if more bandwidth is needed, or multiple bridges for designs using more than two chips. Also, the cost of that bridge is much less than a large interposer.

First Generation EMIB
With those explanations, it sounds like Intel’s EMIB is a win-win. There have been a few limitations to the technology – actually embedding a bridge into a substrate is kind of hard. Intel has spent several years and lots of money trying to perfect the technology for low power operation. On top of this, whenever you are adding multiple elements together, there is an associated yield with that process – even if connecting a chip to a bridge has a 99% yield, doing it with a dozen chips on a single design reduces the overall yield down to 87%, even when starting with known good chips (that have their own yield). When you hear that Intel has been working on bringing this technology to volume, it is these numbers they are trying to improve.
Intel currently has EMIB in the market on several of its products, most noticeably its Stratix FPGA and Agilex FPGA families, but it was also part of its Kaby G line of mobile processors, connecting a Radeon GPU to high-bandwidth memory. Intel has already stated that it is coming to several future products, such as Ponte Vecchio (supercomputer-class graphics), Sapphire Rapids (next generation Xeon enterprise processor), Meteor Lake (2023 consumer processor), and others related to graphics.

Intel's Ponte Vecchio uses EMIB and Foveros
On the roadmap side of EMIB, Intel is reducing the bump pitch over the next few years. When the chips are connected to the bridges embedded in the substrate, they connect across bumps, and the distance between the bumps is known as the pitch – the smaller the bump pitch, the more connections can be made in the same area. This allows the chip to either increase bandwidth, or reduce the bridge size. The first generation EMIB technologies in 2017 were using 55 micron bump pitches, and that still appears to be the case with upcoming Sapphire Rapids (see my comment about the time it has taken Intel to get it right), however Intel is aligning itself with a 45 micron EMIB beyond Sapphire Rapids, leading to a 36 micron EMIB in its third generation. The timescales for these were not disclosed, however post Sapphire Rapids would be Granite Rapids, so that might be where the 45 micron design comes to market.
Foveros: Die to Die Stacking
Intel introduced its die-to-die stacking technology in 2019 with Lakefield, a mobile processor designed for low idle power designs. That processor has since been put on End of Life proceedings, but the idea is still integral to the future of Intel’s future product portfolio and foundry offerings.
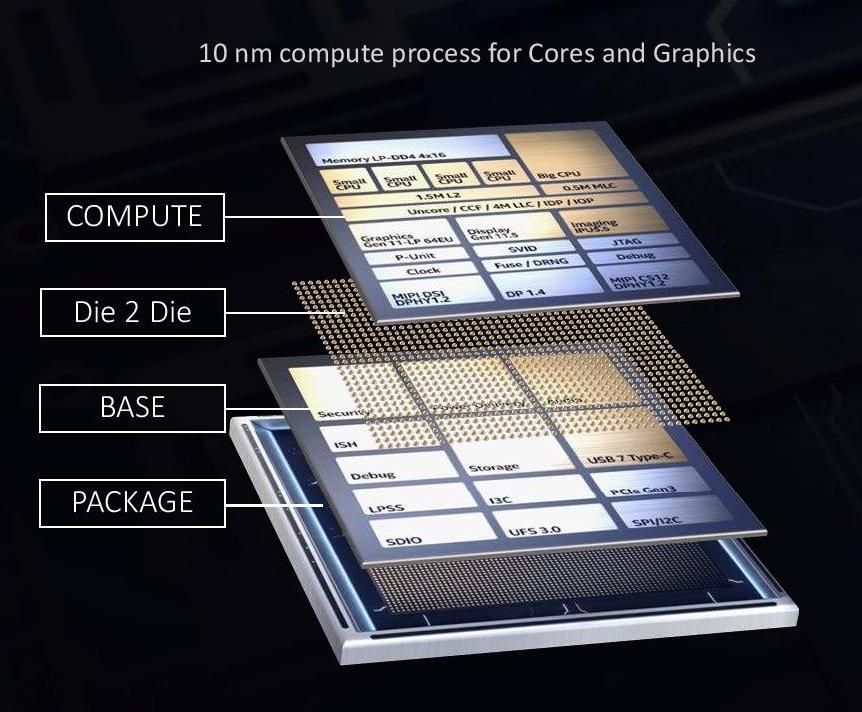
Intel’s die-to-die stacking is to a large extent very similar to the interposer technology mentioned in the EMIB section. We have one piece of silicon (or more) on top of another. In this instance however, the interposer, or base die, has active circuitry relevant for the full operation of the main compute processors found in the top piece of silicon. While the cores and graphics were on the top die in Lakefield, built on Intel’s 10nm process node, the base die had all the PCIe lanes, USB ports, security, and everything low power related to IO, and was built on a 22FFL low power process node.

So while EMIB technology splitting the silicon to work alongside each other is known as 2D scaling, by placing the silicon on top of each other we have entered a full 3D stacking regime. This comes with some good benefits, especially at scale – data paths are a lot shorter, leading to less power loss due to shorter wires but also better latency. The die-to-die connections are still bonded connections, with the first generation at a 50 micron pitch.
But there are two key limitations here: thermals and power. To avoid problems with thermals, Intel made the base die have very little logic and used a low power process. With power, the issue is enabling the top compute die to have power for its logic – this involves large power through-silicon-vias (TSVs) from the package up through the base die into the top die, and those TSVs carrying power become an issue for localized data signaling due to interference caused by high currents. There is also a desire to scale to smaller bump pitches in future processes, allowing for higher bandwidth connections, requiring more attention to be paid by the power delivery.
The first announcement related to Foveros today is regarding a second generation product. Intel’s 2023 consumer processor, Meteor Lake, has already been described above as using an Intel 4nm compute tile, taking advantage of EUV. Intel is also stating today that it will be using its second generation Foveros technology on the platform, implementing a bump pitch of 36 micron, effectively doubling the connection density over the first generation. The other tile in Meteor Lake has not been disclosed yet (either what it has or what node it is on), however Intel is also stating that Meteor Lake will scale from 5 W to 125 W.
Foveros Omni: Third Generation Foveros
For those that have been following Intel’s packaging technologies closely, then the name ‘ODI’ might be familiar. It stands for Omni-Directional Interconnect, and it was the moniker being floated in previous Intel roadmaps regarding a packaging technology that allows for cantilevered silicon. That is now going to be marketed as Foveros Omni.
This means that the limit of the first generation Foveros which needed a top die smaller than the base die is now removed. The top die can be larger than the base die, or if there are multiple die on each of the levels, they can be connected to any number of other silicon. The goal of Foveros Omni is really to solve the power problem as discussed in the initial section on Foveros – because power carrying TSVs cause a lot of localized interference in signaling, the ideal place to put them would be on the outside of the base die. Foveros Omni is a technology that allows for the top die to overhang from the base die and copper pillars are built from the substrate up to the top die to provide power.

With this technology, if power can be brought in from the edges of the top die, then this method can be used. I did wonder, however, that with large silicon if power would be better fed right up the middle – Intel has stated that Foveros Omni works with split base dies, such that power carrying copper pillars could be placed in the middle of the design if the base die is designed for substrate to be available on that lower layer.
By moving the power TSVs outside the base die, this also allows for a die-to-die bump pitch improvement. Intel is citing 25 microns for Omni, which would be another 50% increase in bump density over second generation Foveros. Intel is expecting Foveros Omni to be ready for volume manufacturing in 2023.
Foveros Direct: Fourth Generation Foveros
One of the issues with any die-to-die connectivity is the connection itself. In all of these technologies mentioned so far, we’re dealing with microbump bonded connections – small copper pillars with a tin solder cap, which are put together and ‘bonded’ to create the connection. As these technologies are growing copper and the depositing tin solder, it gets difficult to scale them down, plus there is also the power loss of the electronics transferring into the different metals. Foveros Direct gets around this problem, by doing direct copper-to-copper bonding.
Rather than rely on pillars and bumps coming together, the concept of direct silicon-to-silicon connectivity has been researched for a number of years. If one piece of silicon is lined up directly with another, then there is little-to-no need for extra steps to grow copper pillars and such. The issue comes with making sure that all the connections are made, ensuring that both the top die and bottom die are so incredibly flat that nothing can get in the way. Also, the two pieces of silicon have to become one, and are permanently bonded together without any way of coming apart.

Foveros Direct is a technology that helps Intel drive the bump pitch of its die-to-die connections down to 10 micron, a 6x increase in density over Foveros Omni. By enabling flat copper-to-copper connections, bump density is increased, and the use of an all-copper connection means a low resistance connection and power consumption is reduced. Intel has suggested that with Direct, functional die partitioning also becomes easier, and functional blocks could be split across multiple levels as needed.
Technically Foveros Direct as a die-to-die bonding could be considered complimentary to Foveros Omni with the power connections outside the base die – both could be used independently of each other. Direct bonding would make internal power connections easier, but there would still be the issue of interference perhaps, which Omni would take care of.
It should be noted that TSMC has a similar technology, known as Chip-on-Wafer (or Wafer-on-Wafer), with customer products set to come to the market in the coming months using 2-high stacks. TSMC has demonstrated a 12-high stack in mid-2020, however this was a test vehicle for signaling, rather than a product. The issue going up in stacks is still going to be thermals, and what goes into each layer.
Intel predicts that Foveros Direct, like Omni, will be ready for mass volume in 2023.








326 Comments
View All Comments
shabby - Monday, July 26, 2021 - link
Lol this guy is a great comedian 😂at_clucks - Tuesday, July 27, 2021 - link
They're also preparing the elusive 0nm process. Really tiny, great power consumption too.RealBeast - Tuesday, July 27, 2021 - link
Don't get sucked into those 0nm chips, wait for the negative nm the following year. ;)linuxgeex - Wednesday, July 28, 2021 - link
Intel's minds have come up with a new complex plane process. They measure their feature size by taking the square root of the height of the gate. By extending the gate downward, their measurements start at -1, leading to measurements in the scale of i, which tickles their marketing department no end. Sadly, i doesn't deliver on a real timeline.mode_13h - Thursday, July 29, 2021 - link
:DSantoval - Sunday, October 24, 2021 - link
Do not disregard complex timelines so casually. Intel can well deliver in a + bi, where a = Q (quarter), b = year and i is, you know, the imaginary thingy.Assuming a claimed Q1 2025 delivery in the real plane of Intel's RibbonFET 20A parts, in the complex plane where Intel lives the actual delivery would be in Q1 + 2025i.
Let's say Jan 2025i; right after the complex holiday season of 2024 / 2025, complete with an imaginary Santa and complex elves.
nandnandnand - Monday, July 26, 2021 - link
"Isn't Intel Just Trying To Pull The Wool Over Our Eyes?"Yes. Otherwise there's no need for the marketing dept to magically shrink the fake 10nm node to become a fake 7nm.
ianmills - Monday, July 26, 2021 - link
When everyone lies nobody is wrong...nandnandnand - Monday, July 26, 2021 - link
As long as they put out accurate transistors per square millimeter estimates, everything's fine.Who is the biggest liar now? Probably Samsung.
DigitalFreak - Monday, July 26, 2021 - link
Nope. Still Intel.