Cadence Announces The Tensilica DNA 100 IP: Bigger Artificial Intelligence
by Andrei Frumusanu on September 19, 2018 9:00 AM EST
Cadence is an industry player we don’t mention nearly enough as much as we should - they make a lot of IP and specialises in accelerator blocks which augment camera and vision capabilities. The company’s Tensilica IP offerings are still quite notable and are present in popular SoCs such as HiSilicon’s Kirin lineup or MediaTek’s chipsets. This week they have announced more “AI” centric product offerings which promise to accelerate neural network inferencing on edge devices.
The markets for on-device neural network (NN) inferencing are very much exploding as the industry is trying to offload expensive and cumbersome cloud-based inferencing to the connected device itself, resulting is magnitudes of lower power, and most importantly, much lower latency.


Here Cadence showcases that here’s a wide range of performance needs across different sectors from IoT, Mobile, AR/VR to more performance hungry applications such as smart surveillance and automotive applications.
Today Cadence is announcing a new dedicated “AI” IP that focuses on performance and scaling across this wide variety of needs, scaling up much higher than before, promising up to 100’s of TMACs (Trillions matrix accumulate operations).
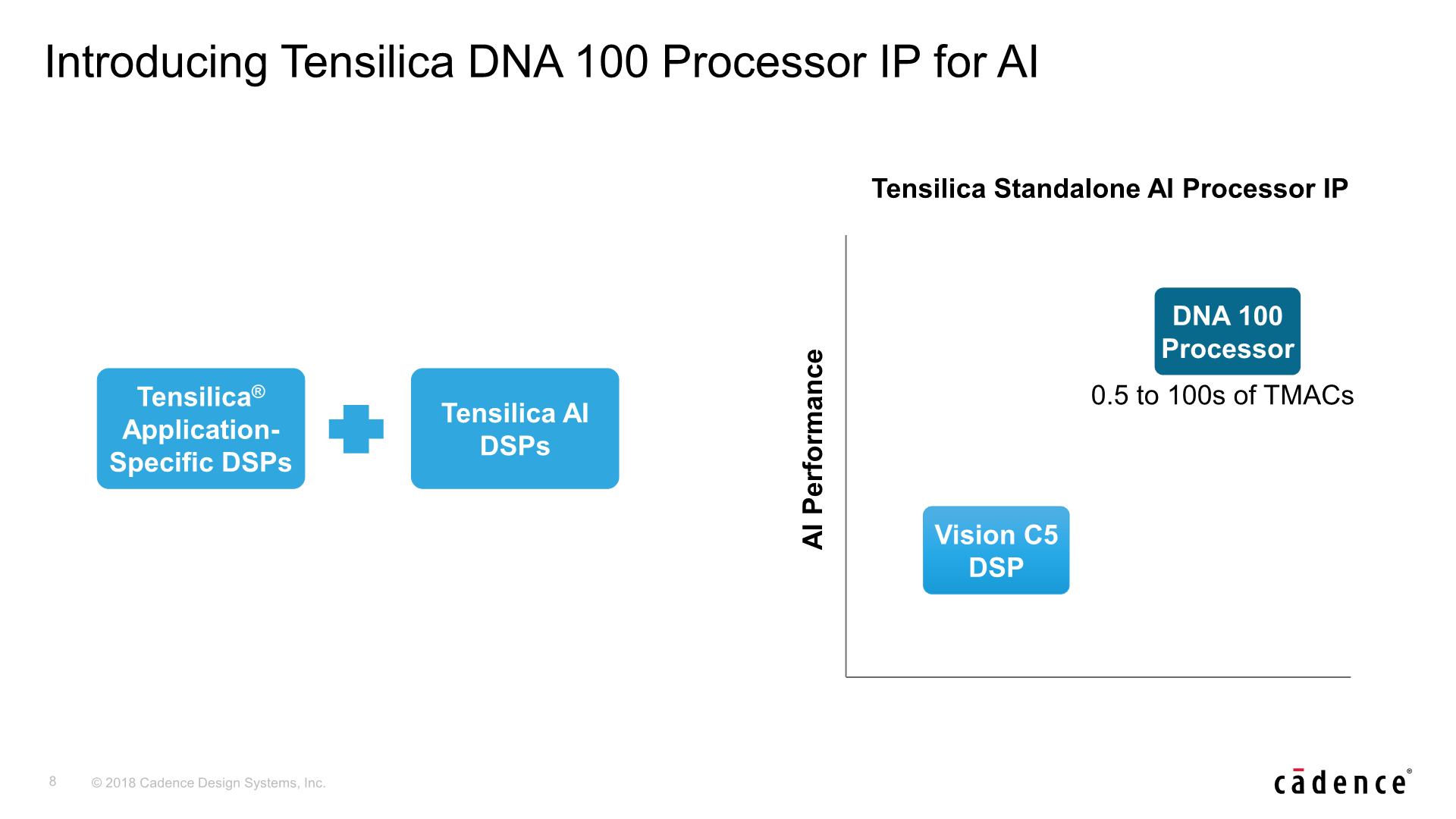

Cadence explains that such high inferencing performance is needed in use-cases such as auto-motive, where a car for example will have a large swath of sensors, including radar, camera, lidar and ultrasound. Standard DSPs will handle the brunt of the signal processing, but then the tasks of actually making sense of the data would be handed over to neural network accelerators such as the DNA 100 which handle perception and decision making tasks.
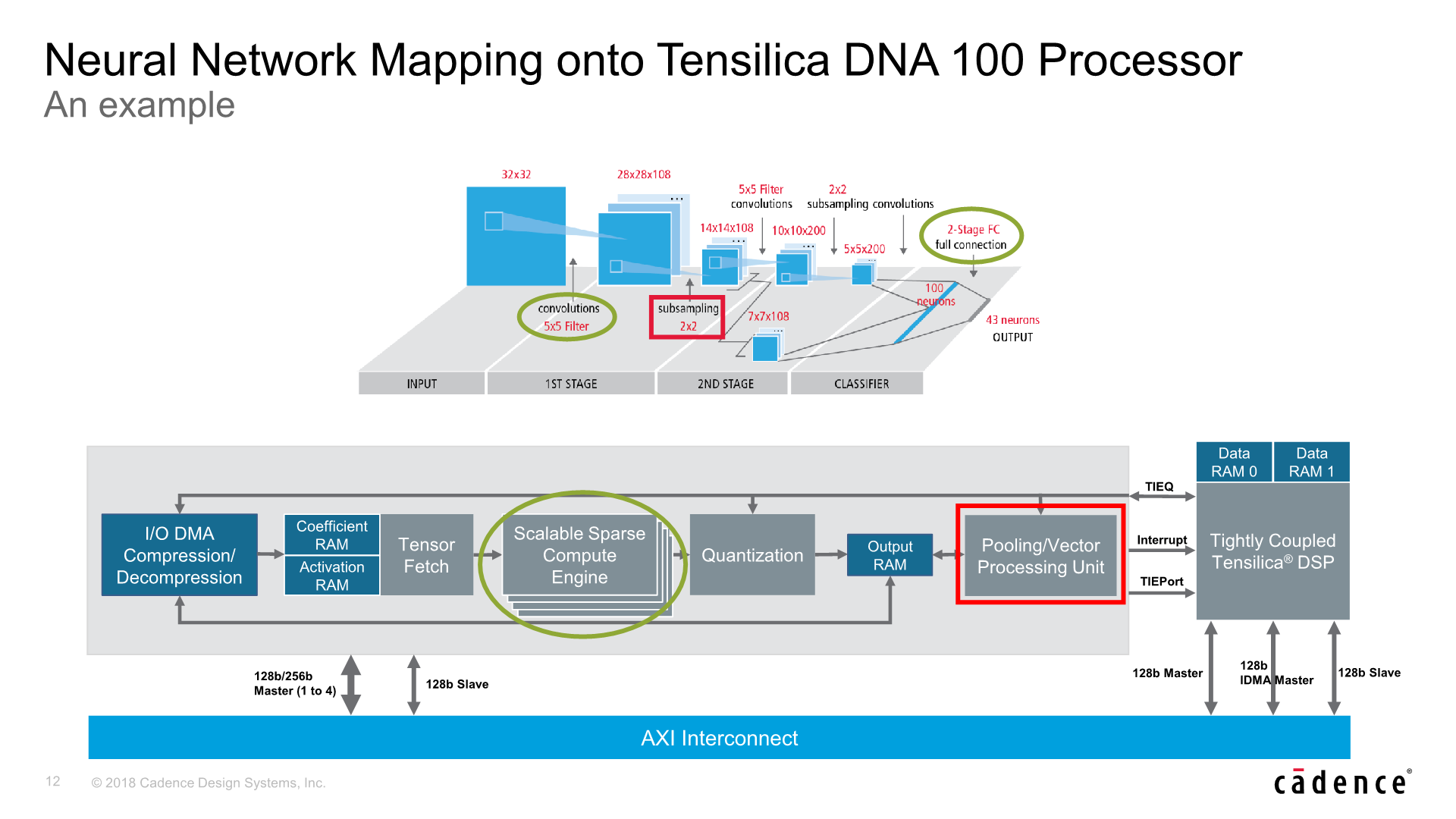
Dwelling more deeply into the new DNA 100 processor, Cadence makes big claims such as up to 4.7x performance advantages over competing solutions with similar sized MAC engines. Here Cadence achieves this though its sparse compute architecture, which means that it only computes non-zero activations and weights, and claiming to achieve significantly higher hardware MAC utilisation than the competition.
"Neural networks are characterized by inherent sparsity for both weights and activations, causing MACs in other processors to be consumed unnecessarily through loading and multiplying zeros. The DNA 100 processor’s specialized hardware compute engine eliminates both tasks, allowing this sparsity to be leveraged for power efficiency and compute reduction. Retraining of neural networks helps increase the sparsity in the networks and achieve maximum performance from the DNA 100 processor’s sparse compute engine."
In terms of architecture, at the very high level the DNA 100 looks similar to other inference accelerators. The brunt processing power lies in the MAC engines which Cadence calls the “Scalable Sparse Compute Engines” – these handle the tasks of convolution stages as well as the fully connected classification layers.
The a single MAC engine / sparse compute engine is scalable in either 256, 512 or 1024 MACs – after which the IP scales by adding more engines – up to 4 in total. This means that a single DNA 100 hardware block at its maximum configuration contains up to 4096 MACs.
The MACs are native 8-bit integer able to operate on quantized models at full throughput, but it also offers 16-bit integer at half-rate as well as 16-bit floating point operation at one quarter rate throughput.
Cadence still very much knows that there are use-cases or neural network models that might possibly not be handled by the fixed-function IP, and still offers the possibility of coupling the DNA 100 with existing Tensilica DSP IP. The two products are tightly coupled and the DSP would be able to handle more exotic NN layers efficiently and passing the kernel back to the DNA 100, making the solution future-proof and extensible to custom layers if a customer so wishes.
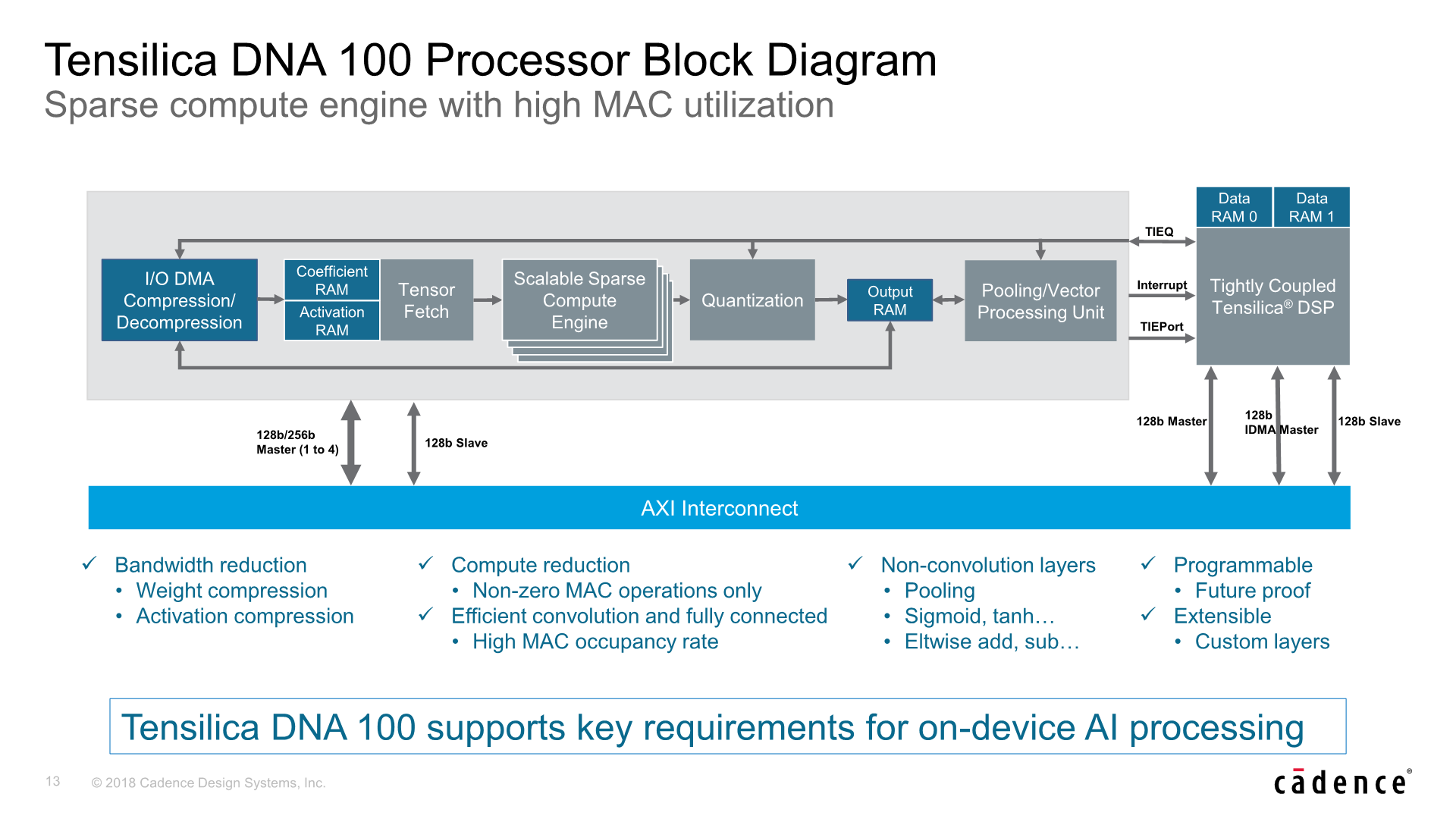
Bandwidth in neural network inferencing hardware is a critical bottleneck, so compression is a very much a must-have in order to achieve the best performance and to not be limited by the platform. Here the DNA 100 offers bandwidth reduction capabilities though compression of weights and activations. In terms of raw bandwidth, the IP also offers the option of very wide interfaces from 1 to 4 AXI 128 or 256bit interfaces, meaning up to a 1024-bit bus width in the widest configuration.
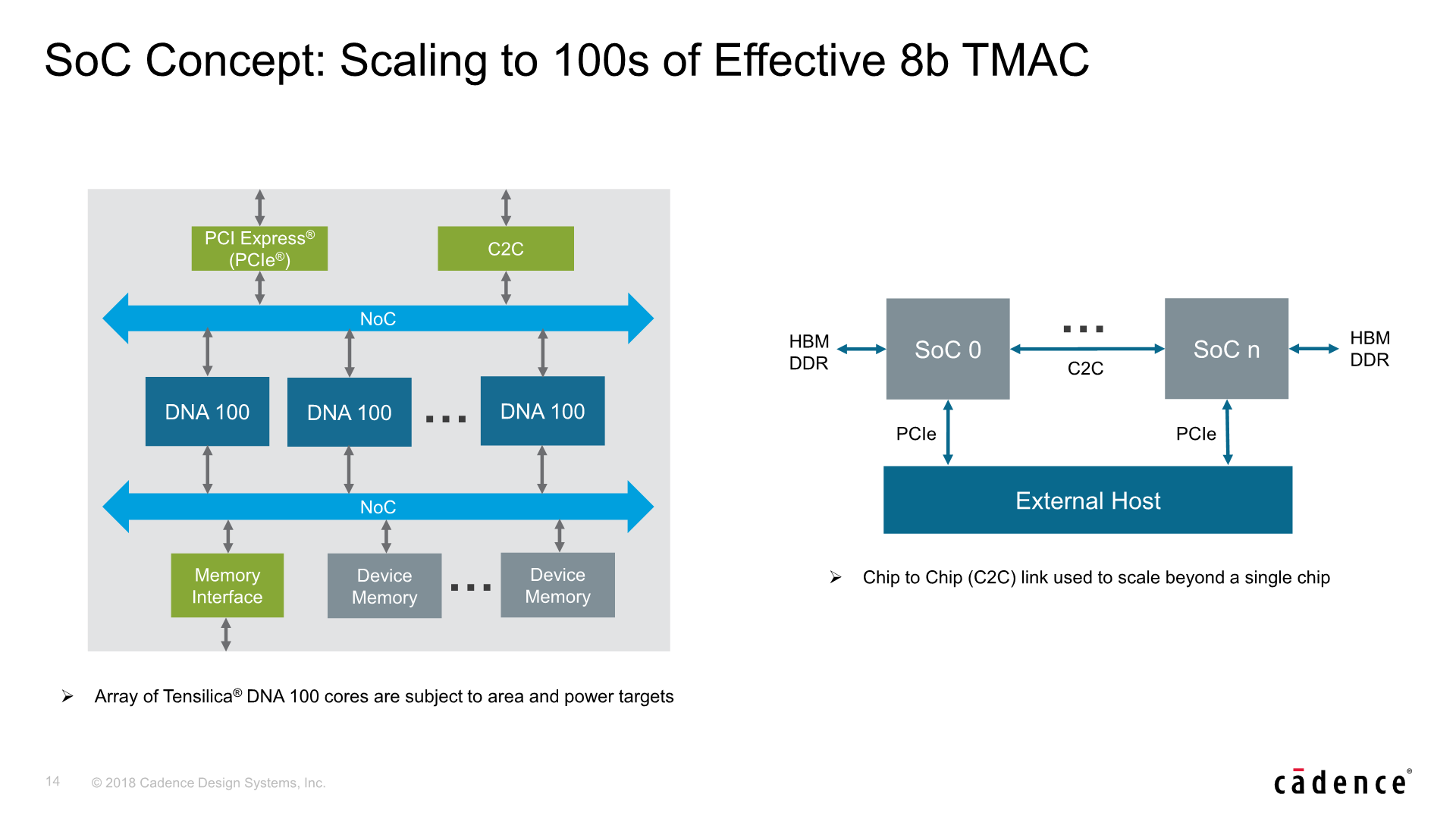
For scaling the IP beyond 4096MACs, you can simply put down multiple hardware blocks alongside each other onto the SoC, vastly increasing the theoretical compute capabilities. Here the software plays a key role as it’s able to properly dispatch the workload across the different blocks. Cadence explains that it’s still possible to accelerate a single kernel/inference in this manner. Beyond this, Cadence also envisions possible multi-chip scaling with chip-to-chip communication. While I’m not exactly expecting such solutions to come any time soon, it demonstrates the IP’s hardware and software capability to scale up in dramatic fashion.

In terms of the performance of the DNA 100 – Cadence again puts emphasis that the actual performance of its architecture is significantly higher than equivalent competing architectures with the same amount of MACs. Here the marketing material refers to “effective TMACs”, which is a bit of an odd metric. Nevertheless the effective performance is said to be also ranging from 2x to up to 3x, depending if the weight and activation data has gone through pruning by the compiler and training.

Possibly the better performance metric, and something that I’ve been hoping for that IP vendors would more often fall back to in their marketing materials, is actual inferencing performance on a given network model. Here Cadence showcases the performance on ResNet50 with a DNA 100 configured at its maximum 4K MAC configuration, with 4TMAC of raw hardware performance.
The DNA 100 is said to achieve 4.7x better performance than a competing solution which also showcases the characteristic of 4TMAC, achieving 2550fps versus the competitor’s 538fps. Here of course the network is configured to achieve the best results on the DNA 100, having gone through pruning.
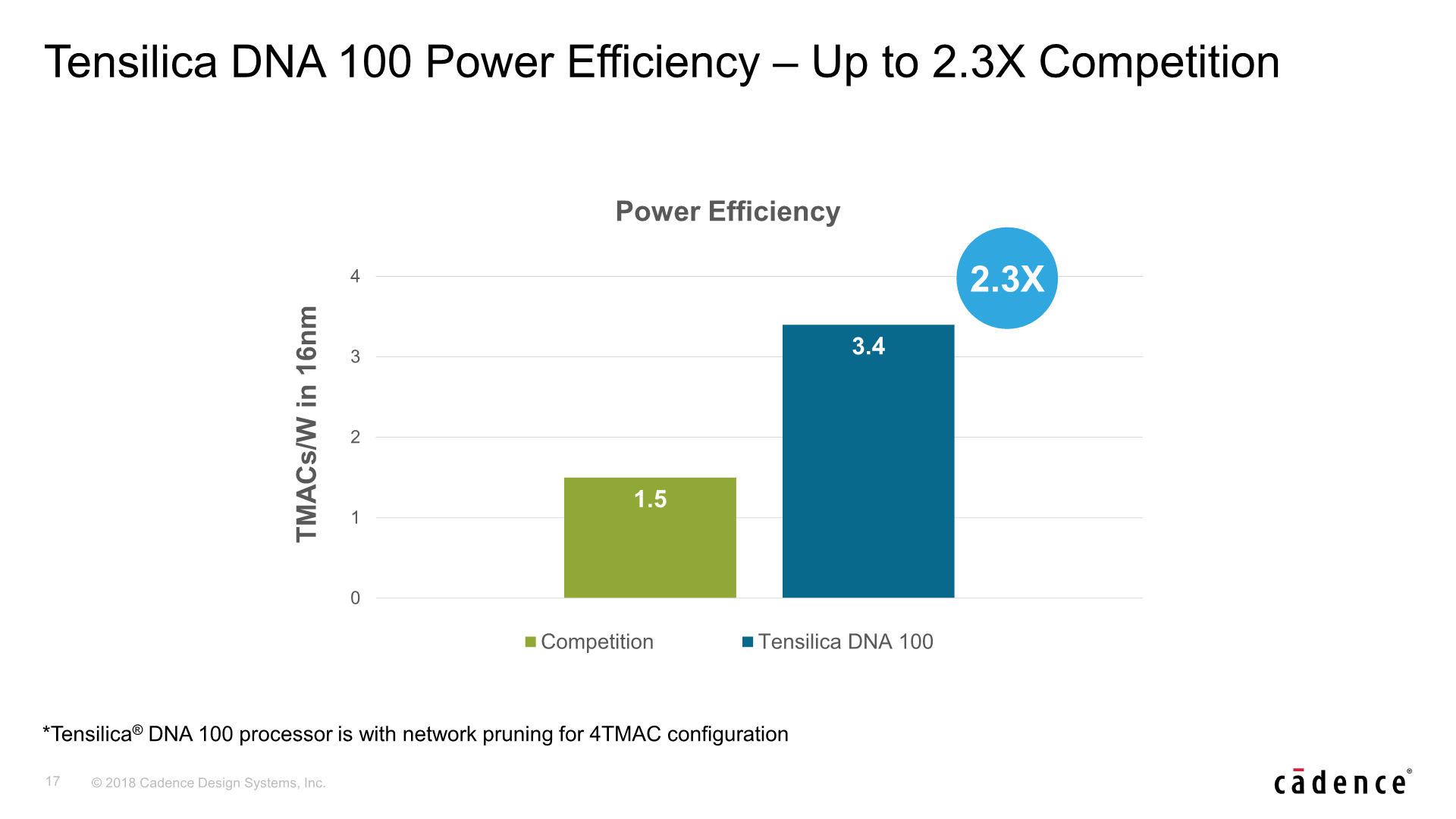
In terms of power efficiency, the DNA 100 is also said to have a 2.3x advantage over the competing solution. At 3.4TMACs/W with a full 4K MAC array, this would result in an absolute power usage of around 850mW, in a 16nm manufacturing node.
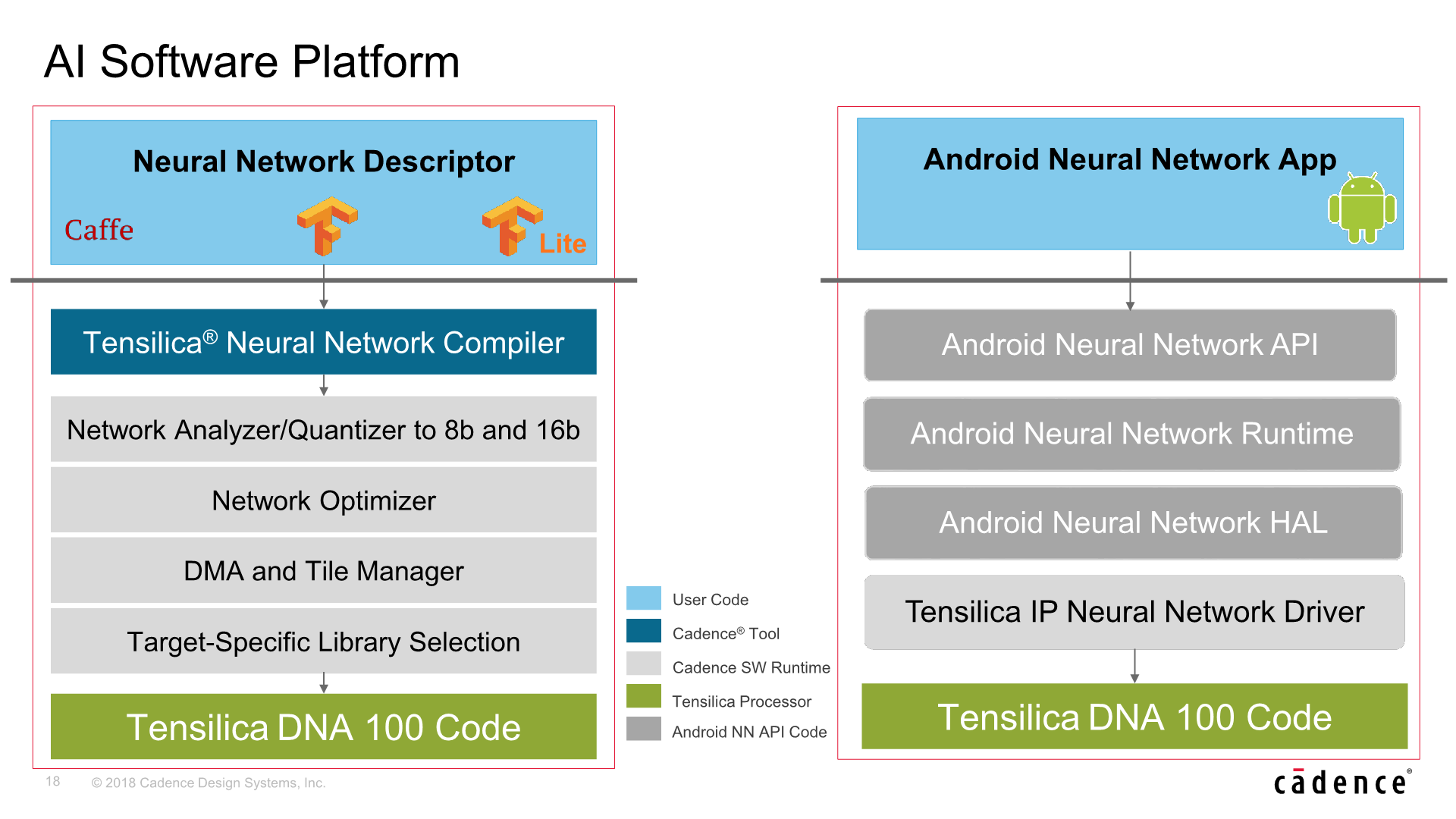
On the software side, Cadence offers a full software stack and Neural Network Compiler to take full advantage of the hardware, including network analysers and optimisers and required device drivers. Cadence also has recently announced that it will support Facebook’s Glow compiler – a cross hardware platform machine learning compiler.
The Tensilica DNA 100 hardware IP will be available for licensing in early 2019, with lead partners being able to get on board a little bit earlier. In terms of time-frame, this would put the earliest silicon products sometime around the end of 2020 – with 2021 a more likely target for most vendors that aren’t on the bleeding edge.
Related Reading
- Cadence Announces Tensilica Vision Q6 DSP
- ARM Details "Project Trillium" Machine Learning Processor Architecture
- Imagination Announces First PowerVR Series2NX Neural Network Accelerator Cores: AX2185 and AX2145
- CEVA Announces NeuPro Neural Network IP
- CEVA Launches Fifth-Generation Machine Learning Image and Vision DSP Solution: CEVA-XM6
- HiSilicon Kirin 970 - Android SoC Power & Performance Overview
- Cambricon, Makers of Huawei's Kirin NPU IP, Build A Big AI Chip and PCIe Card
- MediaTek Announces New Premium Helio P60 SoC
- Qualcomm Details Hexagon 680 DSP in Snapdragon 820: Accelerated Imaging








9 Comments
View All Comments
eastcoast_pete - Wednesday, September 19, 2018 - link
Interesting article, thanks! One question: I was a bit struck by the "For scaling the IP beyond 4096MACs, you can simply put down multiple hardware blocks alongside each other onto the SoC..". Really? Is the interconnect fast enough (or the data flow slow enough) to allow for such unlimited upscaling? It might very well be all true, but I wonder if you had a chance to ask them about that. Interconnect fabric capabilities and speeds can become major hurdles, as we all know.Jaybus - Wednesday, September 19, 2018 - link
Each of the DNA100's and the DSP can act as memory-mapped master or slave on the AXI interconnect, so inter-DNA100 transfers are just as fast as DSP-DNA100 transfer, and the transfer from DSP would be at the same rate to any of the DNA100 slaves. AXI is very fast, so I would think it scales fairly linearly within its constraints. The fabric's power and area limitations probably allow only a very few DNA100 blocks on the same SoC.imaheadcase - Wednesday, September 19, 2018 - link
I really hate the misuse of the word AI in everything now. This is not AI, this is simply the same thing just did differently. Its still all If and then stuff in programming, its not like its going to be smart AI that predicts what you need.edzieba - Wednesday, September 19, 2018 - link
Ah, the ever receding bar of 'real AI'. As yesterday's AI techniques become widely adopted, they become "just heuristics" or "just procedural selection" or "just deep learning" and 'real AI' moves to the next big thing to chase.Fergy - Thursday, September 20, 2018 - link
AFAIK AI has been HAL2001 for a long time. So tricks to convert images to text, recognize street signs, remove noise from a photo, recognize speech, calculate at which times you use apps are not AI and I don't know when somebody would have said that.ZolaIII - Wednesday, September 19, 2018 - link
One day when categories are fully formed and well trained it will become equivalent to the formal logic (that we use) which by the way is the thing that we don't think about but all of our actions are based upon.PeachNCream - Thursday, September 20, 2018 - link
I love how the industry is using artificial intelligence to mean things other than the emulation of human-like intellect via a computer system because various companies are too inept to come up with relevant terminology that accurately describe stuff like optical character recognition.tuxRoller - Thursday, September 20, 2018 - link
Someone needs to tell https://www.journals.elsevier.com/artificial-intel... to stop publishing papers that just seek to improve existing systems.Iow, the term has shifted in meaning as we disentangle the components of an intelligent agent.
gurukiran0027 - Friday, April 19, 2019 - link
helio p60 is a great chipset by mediatek and powers some really high-tech features