CEVA Announces NeuPro Neural Network IP
by Andrei Frumusanu on January 5, 2018 10:45 AM EST- Posted in
- Mobile
- Neural Networks
- CEVA
- NeuPro
Ahead of CES CEVA today announced a new specialised neural network accelerator IP called NeuPro.
We’ve over the last few months seen an explosion of news related to “AI” and neural networks. Most notably Apple’s neural engine and HiSilicon’s neural processing unit lead the pack with already shipping silicon. These new IP blocks are hardware accelerators for convoluted neural network inferencing. As opposed to what we call “deep learning” which is the training aspect of CNNs, inferencing is the execution of already trained models.
Use-cases such as image classification are very latency and performance sensitive so the industry has evolved towards edge device inferencing, meaning a device such as a smartphone locally has a trained neural network model and does the inferencing and classification locally on the device without having to upload images or other content to the cloud. This is vastly improves latency and makes use-cases such as instantaneous camera scene recognition viable (As used on Huawei’s Mate 10 camera).
As with other IP blocks (image and video encoder/decoders) which accelerate and offload workloads from more general purpose blocks such as the CPU and GPU in a much more specialized and thus faster and more efficient way, neural network inference can also be offloaded. This is what we call neural network accelerators such as CEVA’s NeuPro.
The new NeuPro family comprises four solutions at different performance levels and target use-cases.
- NP500 is the smallest processor, including 512 MAC units and targeting IoT, wearables and cameras
- NP1000 includes 1024 MAC units and targets mid-range smartphones, ADAS, industrial applications and AR/VR headsets
- NP2000 includes 2048 MAC units and targets high-end smartphones, surveillance, robots and drones
- NP4000 includes 4096 MAC units for high-performance edge processing in enterprise surveillance and autonomous driving
CEVA quotes up to 2TOPS for the smallest implementation (NP500) up to 12.5 TeraOPS for the biggest (NP4000). 2 TOPS for a 512MAC engine would point out to a very high 2GHz core clock so it’s more likely CEVA, much like Huawei/HiSilicon are quoting sparse equivalent peak data figures instead of the actual raw TOPS of the MAC engines.
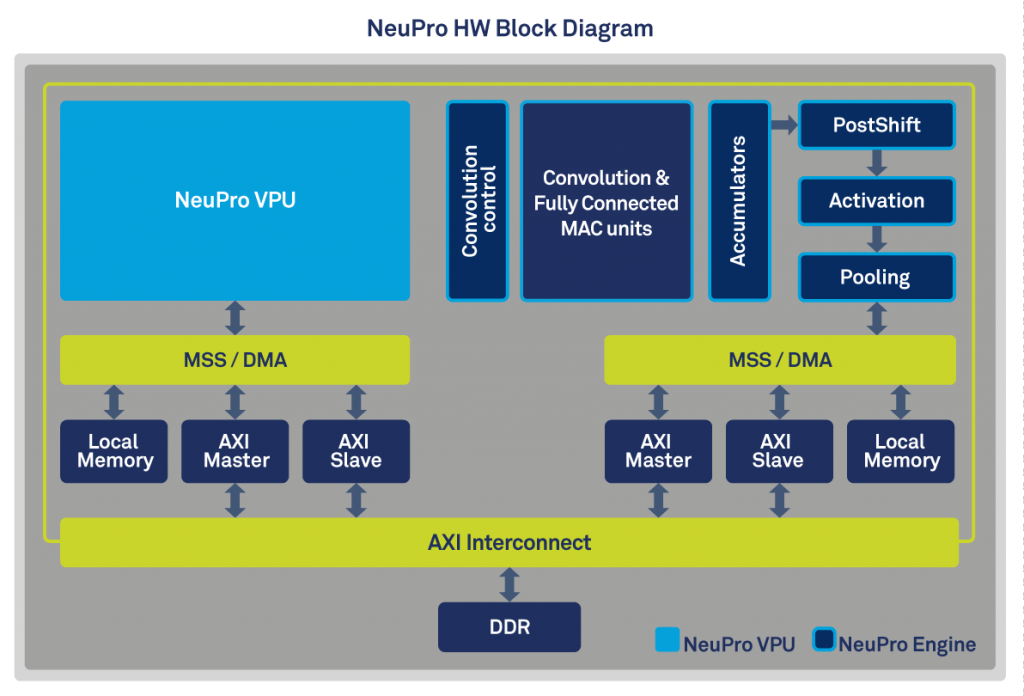
CEVA is a bit unclear here as to the composition and relation between the blocks, but describes a NeuPro block as being composed of a NeuPro VPU and a NeuPro Engine. The NeuPro engine is the fixed function hardware block in charge of executing the processing functions of CNN layers such as convolution, fully-connected layer, pooling and activation. The NPE supports both 8-bit and 16-bit activations with the MAC units being native 8bit, able to pair up to achieve 16b x 8b or 16b x 16b accumulations, allowing a trade-off between precision and bandwidth. We haven’t had a briefing with CEVA yet so it’s not clear if the higher performance tier IP offering duplicate the NeuPro Engines to widen the processing power (most likely) or if there’s scaling of the MAC units within a NeuPro Engine.
The NeuPro VPU is a small programmable vector DSP which is in charge of handling software tasks when running CNNs. Each NeuPro processor consists of a NeuPro VPU and the NPE. There’s some distinction in the industry as to what one calls a DSP with an added in NN accelerator and a more standalone (more integrated) NN acceleration block (Such as Imagination’s 2NX or Cadence’s Tensilica Vision C5). CEVA’s implementation seems to be something in-between leaning more towards the former as far as our immediate understanding goes, and this can be evidenced by the fact that the NeuPro Engine is also offered as an add-on to CEVA-XM4 and XM6 vision DSPs.
CEVA states the NeuPro family will be available for licensing in Q2 of 2018 for lead customers and Q3 for general availability, meaning we shouldn’t be expecting silicon till sometimes around 2020 at the earliest.
Source: CEVA Press Release








12 Comments
View All Comments
Pork@III - Friday, January 5, 2018 - link
Master...Slave...Local...MasterNP16000 will got equally with Zen: master control computer of the Liberator, responsible for the majority of ship operations in "Blake's 7".
SydneyBlue120d - Friday, January 5, 2018 - link
Do You think Apple will continue to use CEVA IP in 2018 too? So the NP2000 will end up in the 2018 iPhone? :)The Hardcard - Friday, January 5, 2018 - link
Where have you guys seen that Apple’s neural block uses CEVA IP? Every link I can find only mentions CEVA in the iPhone in relation to the Intel modem.I am very interested in info about it, if you can direct me to the info, that would be great.
Krysto - Friday, January 5, 2018 - link
I guess we know what Apple will use for its "proprietary Neural Engine" next then. But if it uses only the smallest implementation that will barely match Huawei, and Google's Pixel Core would still be 50% faster. So hopefully they push the industry forward with a 10+ TOPS implementation.Pork@III - Friday, January 5, 2018 - link
Tesla V100 for NVLink make 125 TOPS with tensor cores. 10X against NP4000Andrei Frumusanu - Friday, January 5, 2018 - link
300W vs <10W...Pork@III - Friday, January 5, 2018 - link
Just cut graphic cores of Tesla V100 and consumption will become significantly more equal...mode_13h - Friday, January 5, 2018 - link
No.Krysto - Friday, January 5, 2018 - link
Pegasus will be the "competitor" though, by the time this is out. Pegasus promises 320 TOPS at 500W.Anyways, they aren't actually competitors.
Pork@III - Friday, January 5, 2018 - link
320 TOPS! Mother, this autopilot is even will smarter than me!