Hot Chips 2018: NEC Vector Processor Live Blog
by Ian Cutress on August 21, 2018 8:55 PM EST
08:59PM EDT - We saw this at Supercomputing last year: NEC's new Vector PCIe co-processor. I've wanted to write about it for a while, so I'm glad it's being presented here at Hot Chips. The talk is set to start at 6pm PT / 1am UTC.

09:00PM EDT - SX-Aurora TSUBASA
09:00PM EDT - NEC is a vector processor supercomputer
09:01PM EDT - based company


09:01PM EDT - SX-ACE in 2013 was 28 nm, 1.0 GHz, 256 GFLOPs, 256GB/sec per processor
09:01PM EDT - Do a lot of compiler work
09:02PM EDT - Vector computing for HPC
09:02PM EDT - Focused on large scale supercomputer before, so developed new supercomputer with a vector technology based on the engine

09:03PM EDT - Each node is x86 CPU + Vector Engine with high memory bandwidth and flexible configuration
09:03PM EDT - x86 and Linux, Fortran/C/C++
09:03PM EDT - Automatic vectorization and parallelization by proven vector compiler
09:04PM EDT - Vector Engine is TRANSPARENT to code
09:05PM EDT - Scales from Desktop Tower up to supercomputer

09:05PM EDT - Air cooled and liquid cooled cards

09:06PM EDT - Only one 8-pin connector

09:06PM EDT - PCIe 3.0 x16
09:06PM EDT - Dual slot, sub-300W
09:06PM EDT - only one 8-pin and 300W?

09:07PM EDT - 6 x HBM2

09:07PM EDT - TSMC and Broadcom assist
09:07PM EDT - 1.2 TB/s bandwidth
09:08PM EDT - 2.5D Interposer
09:08PM EDT - VE processor is 15x33mm
09:09PM EDT - 16MB LCC, 2D Mesh
09:09PM EDT - 1.6 GHz, 4.95 TFLOP single precision
09:09PM EDT - Up to 48GB HBM2

09:09PM EDT - 16nm FF
09:09PM EDT - 307GF in DP per core
09:09PM EDT - 8 vector cores inside

09:10PM EDT - Vector processing unit and scalar processing unit
09:10PM EDT - Scalar Processing Unit provides basic functionality - fetch, decode, branch, add, exceptions
09:10PM EDT - Controls the status of the core
09:11PM EDT - Address translation and data forwarding crossbar
09:11PM EDT - 16 elements/cycle vector address generation and translation, 17 requests/cycle issuing
09:11PM EDT - 409.6 GB/sec load and store data forwwarding
09:12PM EDT - Four pipelines, each 32-way parallel

09:12PM EDT - Total 96 FMAs per core
09:12PM EDT - Doubled SP perf by 32-bit x 2 packed vector data
09:12PM EDT - Vector register renaming with 256 physical VRs
09:13PM EDT - 7 VR banks per Vector Pipeline

09:13PM EDT - 32 VPPs per core
09:13PM EDT - OoO scheduling
09:13PM EDT - Dedicated complex operation pipeline
09:14PM EDT - Scalar part of core is traditional front end
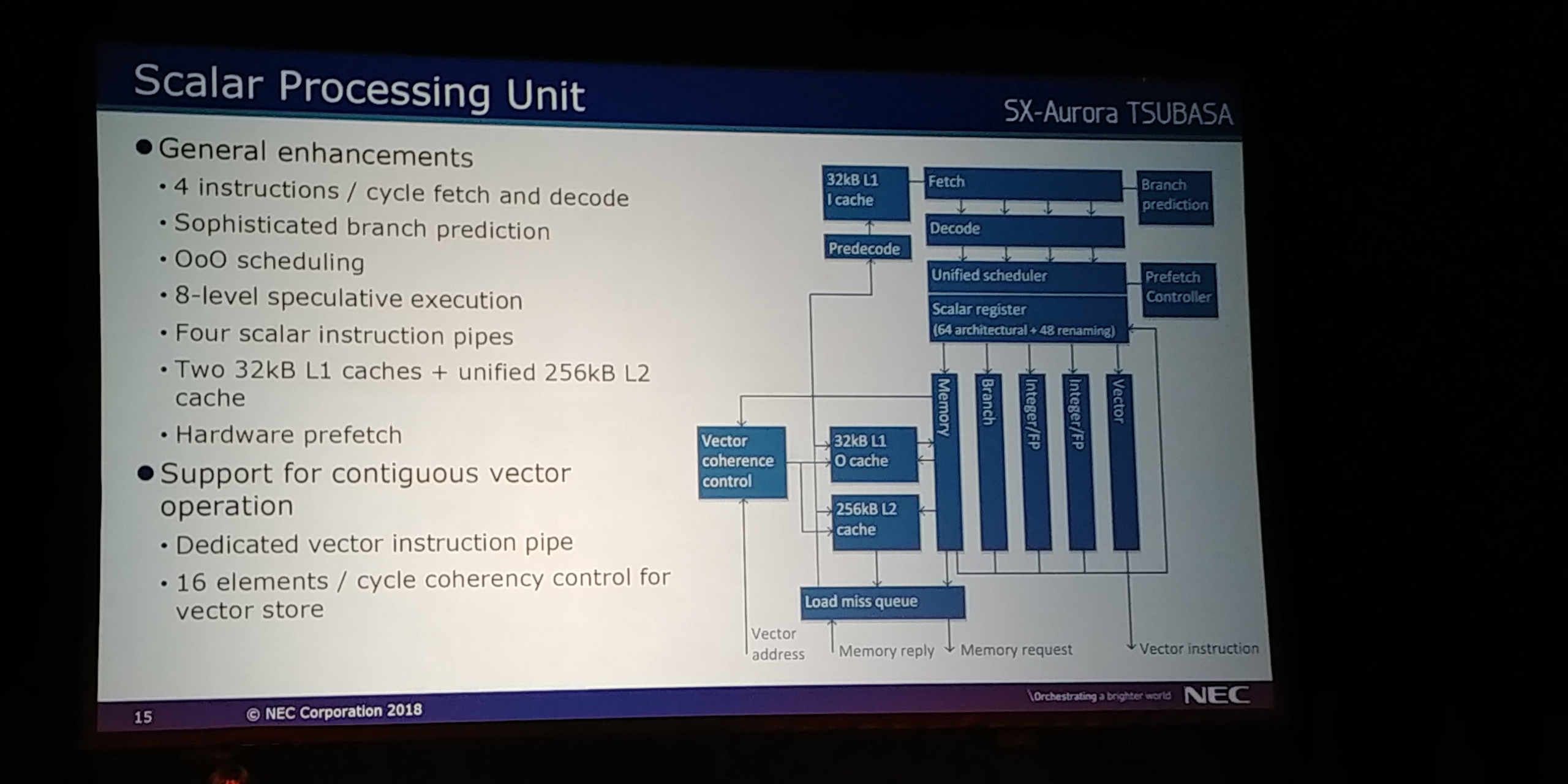
09:14PM EDT - 4 instruction fetch and decode
09:14PM EDT - branch predictor
09:14PM EDT - 8-level speculative execution
09:15PM EDT - 32kB L1 cache and unified 256kb L2
09:15PM EDT - hardware prefetch
09:15PM EDT - Support for contiguous vector instruction pipes
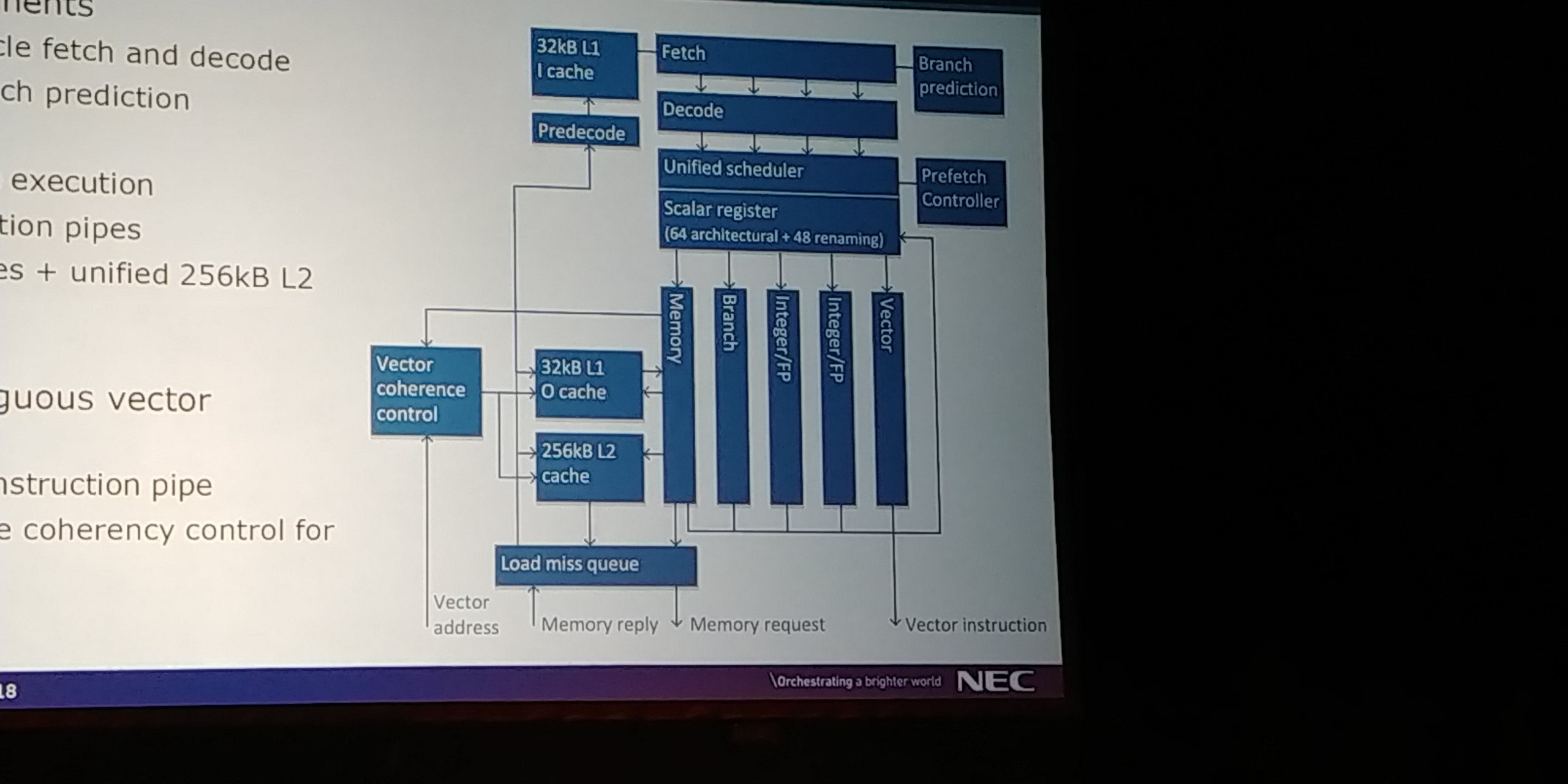
09:16PM EDT - Memory subsystem to support 3 TB/s LLC bandwidth

09:16PM EDT - 1.2 TB HBM2 bandwidth
09:16PM EDT - Scalar L1/L2 ineach core
09:16PM EDT - 2 memory networks - 2D Mesh NoC for cores, also ring bus for DMA
09:16PM EDT - DMA engine used by vector cores and x86 node
09:17PM EDT - DMA engine can be virtualized
09:17PM EDT - Can access VE Memory, VE Registers, and x86 memory
09:17PM EDT - mapped through PCIe

09:17PM EDT - 2D mesh maximuses bandwith with minimal wiring
09:17PM EDT - 16 layer mesh
09:18PM EDT - Age based QoS control
09:18PM EDT - Dimension ordered routing
09:19PM EDT - L3 is 16MB write back
09:19PM EDT - Inclusive of L1 and L2
09:19PM EDT - 128 banks, auto data scrubbing

09:19PM EDT - assignable data buffer feature
09:20PM EDT - Vector Engine is much cheaper than V100
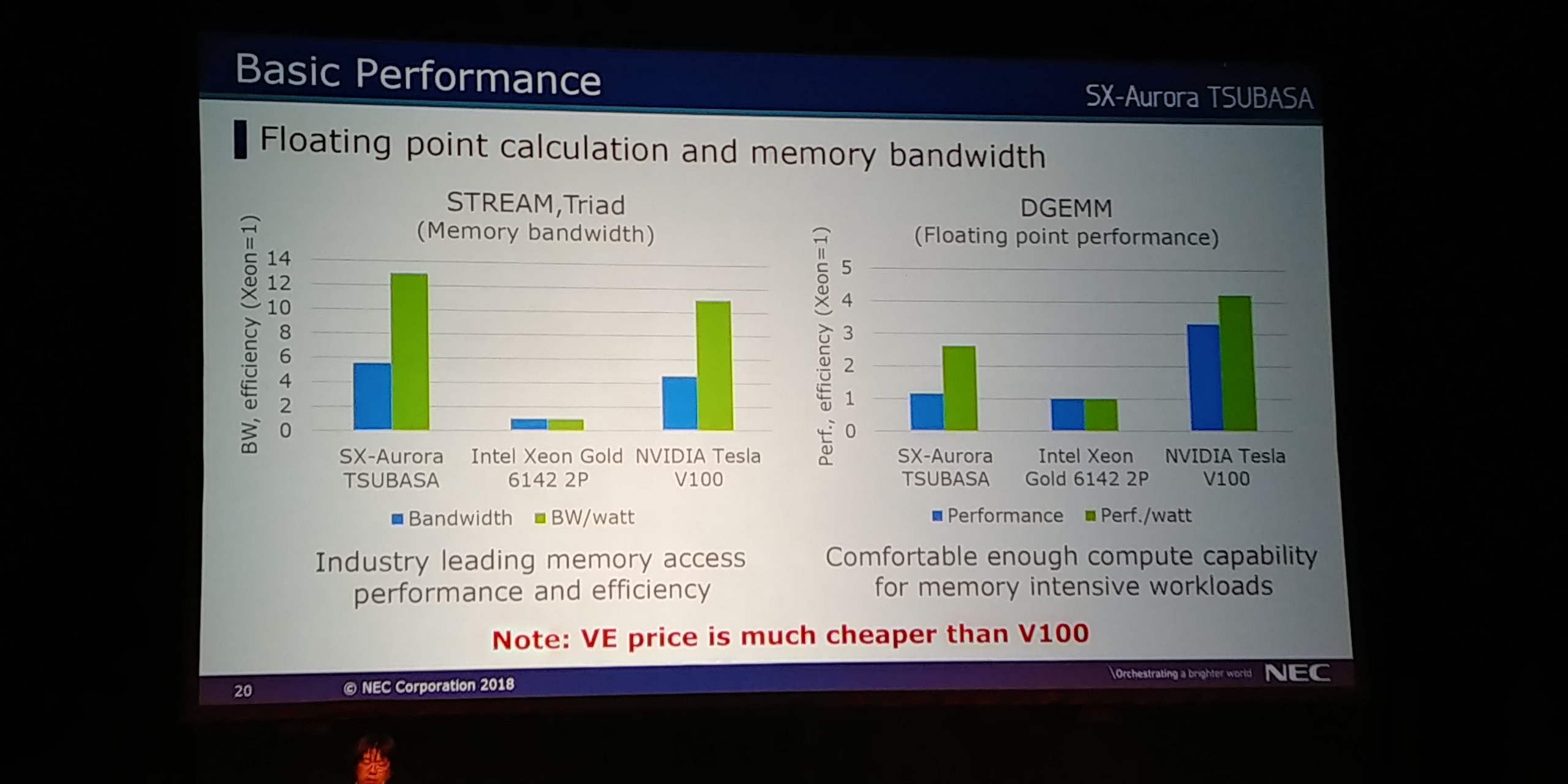
09:21PM EDT - Design target for VE not best Perf/Watt, but beat Xeon. Not optimized yet
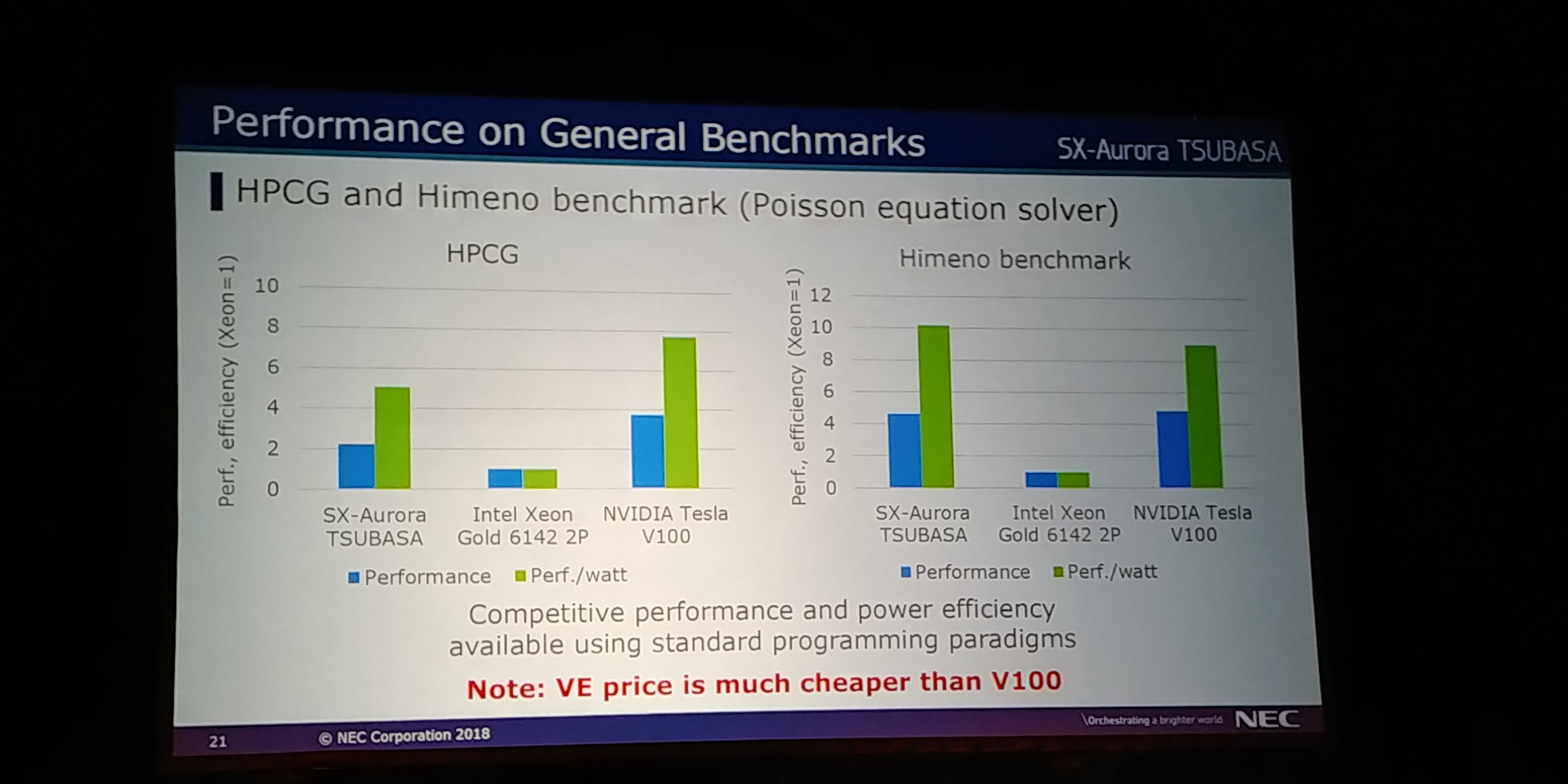
09:22PM EDT - Performance on machine learning up to 107x over Xeon

09:23PM EDT - Very competitive with GPGPU using standard programming paradigms
09:23PM EDT - Q&A
09:31PM EDT - Sorry, left to ask a question about power. That's a wrap, hope you enjoyed our Hot Chips coverage!








9 Comments
View All Comments
SarahKerrigan - Tuesday, August 21, 2018 - link
So, went from effectively two FMA pipes (2xMUL and 2xADD, for chained ops) to three, plus doubling SP throughput and significantly increasing ADB size. Not too shabby!Yojimbo - Wednesday, August 22, 2018 - link
Maybe an American company can come up with something like this so that the DOE can have the second architecture they are looking for while Intel are mucking about.As far as the Vector Engine being much cheaper than a V100. I'm betting they are comparing the cost to build a Vector Engine with the cost to buy a V100. If so, that's a bad comparison. They aren't making their money by selling Vector Engines they are making their money on the supercomputer. And the V100s that go into a supercomputer aren't bought at the price an enterprise customer would pay. The real comparison is the price/performance of a supercomputer that uses Vector Engines and a supercomputer that uses V100s. I doubt implementing the Vector Engines is much cheaper than implementing the V100s for comparable performance.
iwod - Wednesday, August 22, 2018 - link
Why is it not widely used if it was that good?Yojimbo - Wednesday, August 22, 2018 - link
It's a specialty card for an HPC supercomputer. I guess it could be used in other HPC supercomputers if it's successful. The thing is, I think it's designed to run a pre-existing code base that developed around its predecessor chips. Most HPC labs would need to do a lot of work on their code base to optimize it for the architecture.Yojimbo - Wednesday, August 22, 2018 - link
Oh, and of course you have the fact that its Japanese. The big government labs in the US want to use US technology, the big government-funded labs in Europe want to use European technology, etc... And it's those big government labs that are probably in the best position to reformulate their code bases. It's probably not a great option for a smaller university lab.eastcoast_pete - Wednesday, August 22, 2018 - link
Yes, and that's one reason why I found it interesting that the second author's affiliation was listed as "NEC Germany". Certainly not an accident. Might help NEC getting over the NIH (not invented here) problem.Yojimbo - Wednesday, August 22, 2018 - link
It does seem like they are selling servers based on it on the open market. We'll have to see how much uptake there is of it. I dunno if there is a big system planned to use it or not.SarahKerrigan - Wednesday, August 22, 2018 - link
It is pretty widely used. If you look at the HPCG results list, you'll see quite a few Japanese supercomputer sites with SX, and performance (at least on the SX-ACE) is absolutely superb on that benchmark.HStewart - Wednesday, August 22, 2018 - link
Not to say it bad thing to have specialize chips - but I would like to see more details on Intel testing, I found the code for the test - but I see no mention that it compile to used AVX-512.Not even sure if the tests use multi threads and multiple CPU.
http://accc.riken.jp/en/supercom/himenobmt/downloa...