The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTDeepBench Training: Convolutions
Moving on to DeepBench's convolutions training workloads, we should see tensor cores significantly accelerate performance once again. Given that convolutional layers are essentially standard for image recognition and classification, convolutions are one of the biggest potential beneficiaries of tensor core acceleration.
Taking the average of all tests, we again see Volta's mixed precision (FP16 with tensor cores enabled) taking the lead. Unlike with GEMM, enabling tensors on FP32 convolutions results in a tangible performance penalty.
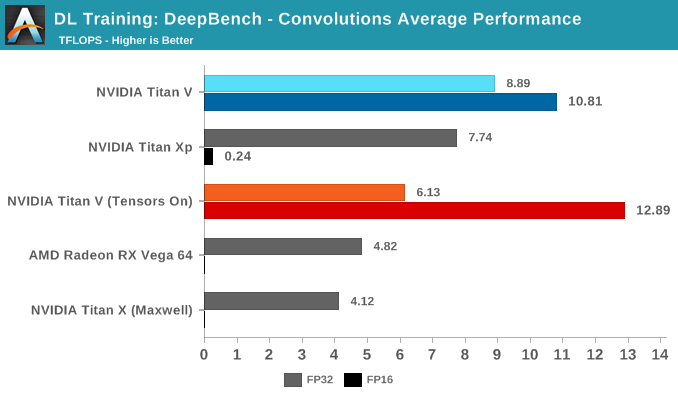
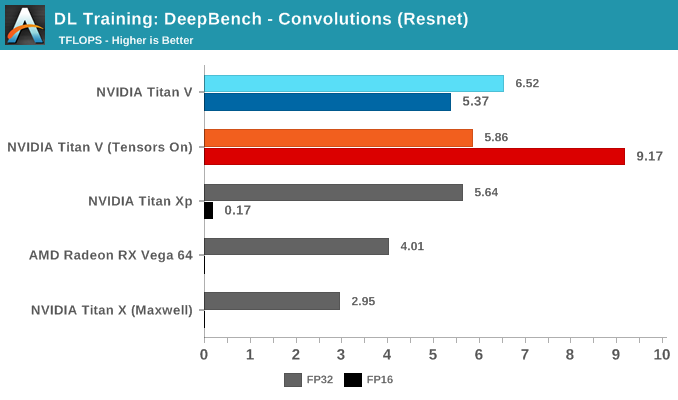
Breaking the tests out by application does not particularly clarify matters. It's only when we return to the DeepBench convolution kernels that we get a little more detail. Performance drops for both mixed precision modes when computations involve ill-matching tensor dimensions, and while standard precision modes follow a cuDNN-specified fastest forward algorithm, such as Winograd, the mixed precision modes are obliged to use implicit precomputed GEMM for all kernels.
To qualify for tensor core acceleration, both input and output channel dimensions must be a multiple of eight, and the input, filter, and output data-types must be half precision. Without going too deep into detail, the implementation of convolution acceleration with tensor cores requires tensors to be in a NHWC format (Number-Height-Width-Channel), but DeepBench, and most frameworks, expect NCHW formatted tensors. In this case, the input channels are not multiples of eight, but DeepBench does automatic padding to account for this.
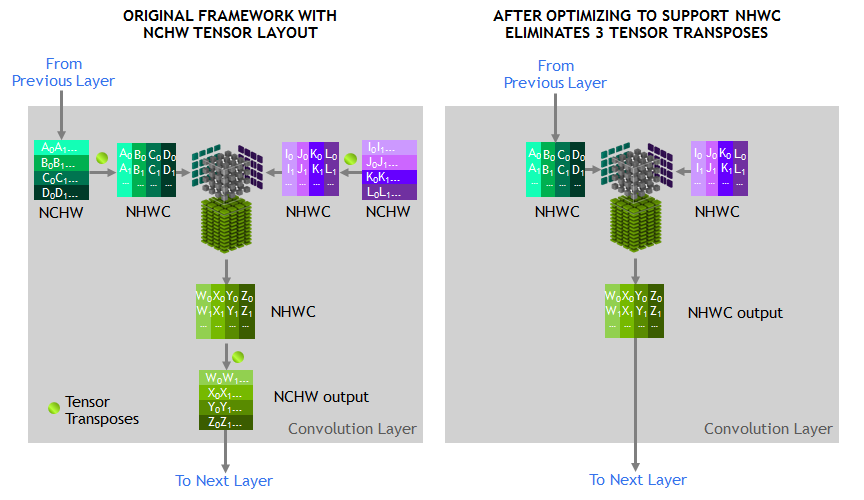
The other factor is that all these NCHW kernels would require transposition to NHWC, which NVIDIA has noted takes up appreciable runtime once convolutions are accelerated. This would affect both FP32 and FP16 mixed precision modes.
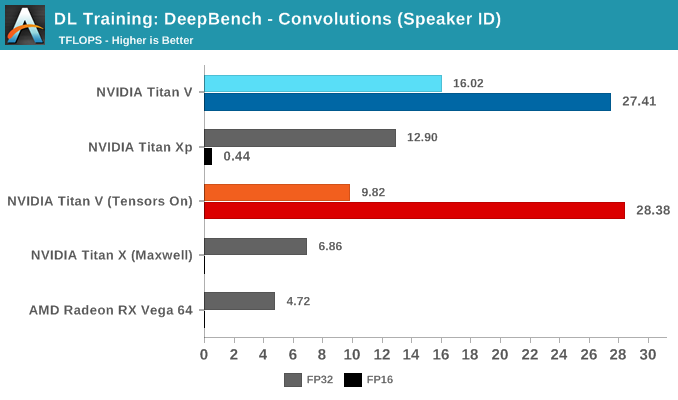
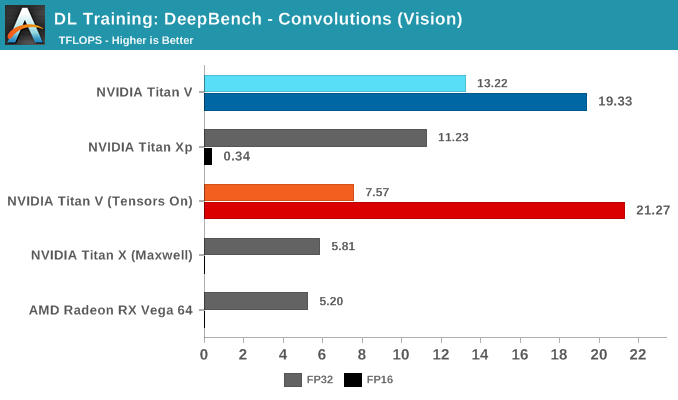
Convolutions still have to be adjusted correctly to benefit from tensor core acceleration. As DeepBench uses the NVIDIA-supplied libraries and makefiles, it's interesting that the standard behavior here would be to force tensor core use at all times.








65 Comments
View All Comments
SirCanealot - Tuesday, July 3, 2018 - link
No overclocking benchmarks. WAT. ¬_¬ (/s)Thanks for the awesome, interesting write up as usual!
Chaitanya - Tuesday, July 3, 2018 - link
This is more of an enterprise product for consumers so even if overclocking it enabled its something that targeted demographic is not going to use.Samus - Tuesday, July 3, 2018 - link
woooooooshMrSpadge - Tuesday, July 3, 2018 - link
He even put the "end sarcasm" tag (/s) to point out this was a joke.Ticotoo - Tuesday, July 3, 2018 - link
Where oh where are the MacOS drivers? It took 6 months to get the pascal Titan drivers.Hopefully soon
cwolf78 - Tuesday, July 3, 2018 - link
Nobody cares? I wouldn't be surprised if support gets dropped at some point. MacOS isn't exactly going anywhere.eek2121 - Tuesday, July 3, 2018 - link
Quite a few developers and professionals use Macs. Also college students. By manufacturer market share Apple probably has the biggest share, if not then definitely in the top 5.mode_13h - Tuesday, July 3, 2018 - link
I doubt it. Linux rules the cloud, and that's where all the real horsepower is at. Lately, anyone serious about deep learning is using Nvidia on Linux. It's only 2nd-teir players, like AMD and Intel, who really stand anything to gain by supporting niche platforms like Macs and maybe even Windows/Azure.Once upon a time, Apple actually made a rackmount OS X server. I think that line has long since died off.
Freakie - Wednesday, July 4, 2018 - link
Lol, those developers and professionals use their Macs to remote in to their compute servers, not to do any of the number crunching with.The idea of using a personal computer for anything except writing and debugging code is next to unheard of in an environment that requires the kind of power that these GPUs are meant to output. The machine they use for the actual computations are 99.5% of the time, a dedicated server used for nothing but to complete heavy compute tasks, usually with no graphical interface, just straight command-line.
philehidiot - Wednesday, July 4, 2018 - link
If it's just a command line why bother with a GPU like this? Surely integrated graphics would do?(Even though this is a joke, I'm not sure I can bear the humiliation of pressing "submit")