The Intel Lakefield Deep Dive: Everything To Know About the First x86 Hybrid CPU
by Dr. Ian Cutress on July 2, 2020 9:00 AM ESTThermal Management on Stacked Silicon
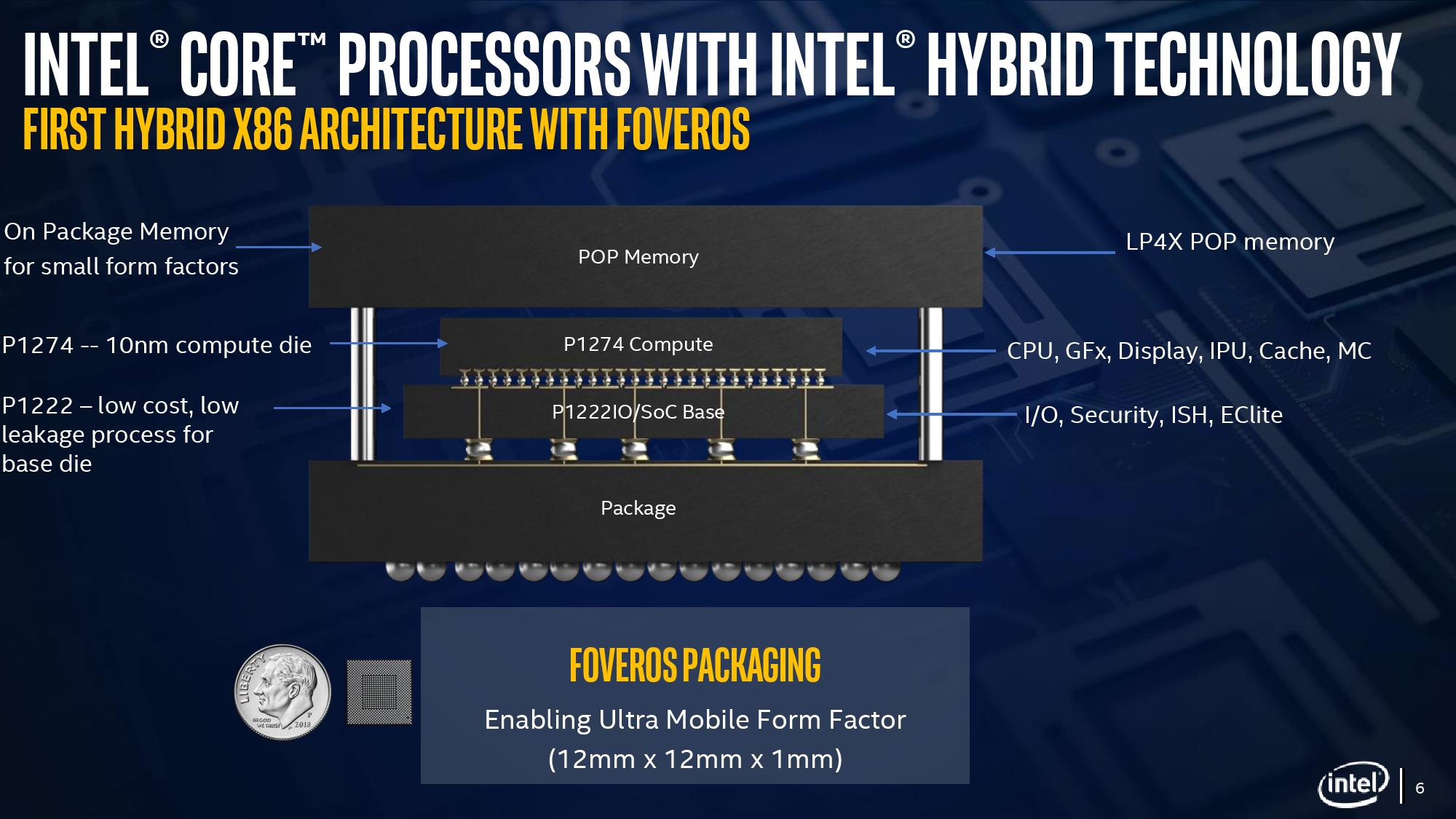
With a standard processor design, there is a single piece of silicon doing all the work and generating the heat – it’s bonded to the package (which doesn’t do any work) and then depending on the implementation, there’s some adhesive to either a cooler or a headspreader then a cooler. When moving to a stacked chiplet design, it gets a bit more complicated.
Having two bits of silicon that ‘do work’, even if one is the heavy compute die and the other is an active interposer taking care of USB and audio and things, does mean that there’s a thermal gradient between the silicon, and depending on the bonding, potential for thermal hotspots and build-up. Lakefield makes it even more complex, by having an additional DRAM package placed on top but not directly bonded.
We can take each of these issues independently. For the case of die-on-die interaction, there is a lot of research going into this area. Discussions and development about fluidic channels between two hot silicon dies have been going on for a decade or longer in academia, and Intel has mentioned it a number of times, especially when relating to a potential solution of its new die-to-die stacking technology.
They key here is hot dies, with thermal hotspots. As with a standard silicon design, ideally it is best to keep two high-powered areas separate, as it gives a number of benefits with power delivery, cooling, and signal integrity. With a stacked die, it is best to not have hotspots directly on top of each other, for similar reasons. Despite Intel using its leading edge 10+ process node for the compute die, the base die is using 22FFL, which is Intel’s low power implementation of its 14nm process. Not only that, but the base die is only dealing with IO, such as USB and PCIe 3.0, which is essentially fixed bandwidth and energy costs. What we have here is a high-powered die on top of a low powered die, and as such thermal issues between the two silicon die, especially in a low TDP device like Lakefield (7W TDP), are not an issue.
What is an issue is how the compute die gets rid of the heat. On the bottom it can do convection by being bonded to more silicon, but the top is ultimately blocked by that DRAM die. As you can see in the image above, there’s a big air gap between the two.
As part of the Lakefield design, Intel had to add in a number of design changes in order to make the thermals work. A lot of work can be done with the silicon design itself, such as matching up hotspots in the right area, using suitable thickness of metals in various layers, and rearranging the floorplan to reduce localized power density. Ultimately both increasing the thermal mass and the potential dissipation becomes high priorities.
Lakefield CPUs have a sustained power limit of 7 watts – this is defined in the specifications. Intel also has another limit, known as the turbo power limit. At Intel’s Architecture Day, the company stated that the turbo power limit was 27 watts, however in the recent product briefing, we were told is set at 9.5 W. Historically Intel will let its OEM partners (Samsung, Lenovo, Microsoft) choose its own values for these based on how well the design implements its cooling – passive vs active and heatsink mass and things like this. Intel also has another factor of turbo time, essentially a measure of how long the turbo power can be sustained for.
When we initially asked Intel for this value, they refused to tell us, stating that it is proprietary information. After I asked again after a group call on the product, I got the same answer, despite the fact that I informed the Lakefield team that Intel has historically given this information out. Later on, I found out through my European peers that in a separate briefing, they gave the value of 28 seconds, to which Intel emailed me this several hours afterwards. This value can also be set by OEMs.
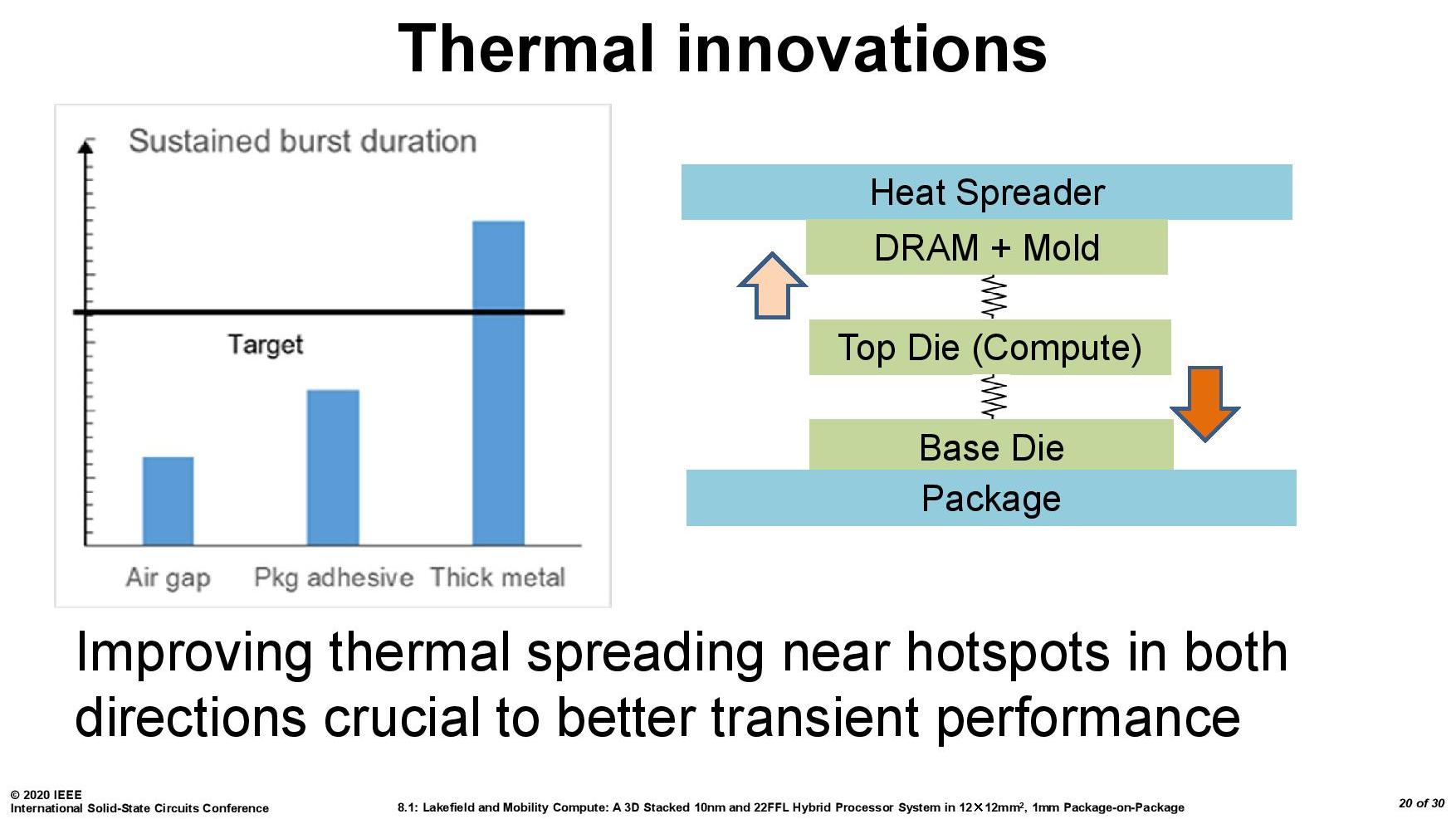
Then I subsequently found one of Intel’s ISSCC slides.

This slide shows that a basic implementation would only allow sustained power for 2.5 seconds. Adding in an adhesive between the top die and the DRAM moves up to 12.4 seconds, and then improving the system cooling goes up to 20 seconds. The rest of the improvements work below the compute die: a sizeable improvement comes from increasing the die-to-die metal density, and then an optimized power floor plan which in total gives sustained power support for 150+ seconds.








221 Comments
View All Comments
extide - Thursday, July 2, 2020 - link
It's 22FFL, which is a derivative of the 14nm process.ProDigit - Friday, July 3, 2020 - link
All chip manufacturers make CPUs at variable lithography. Even AMD. When it says their Ryzens are built on a 7nm node, it means 7nm is the smallest, but other parts still use 10, 12, 14 or 22 nm.Ryzen 2000 CPUs had parts still running on 28nm.
FunBunny2 - Friday, July 3, 2020 - link
"other parts still use 10, 12, 14 or 22 nm. Ryzen 2000 CPUs had parts still running on 28nm."which raises a question, which I suppose is answered somewhere in the hardware engineering space: I suppose having multiple 'node' sizes on the same line is possible due to the fact that the native 'node' is way larger than, in this case, 7nm by multi-masking, and backing off on masks to print the larger 'node' segments. so, if we should ever get to some Xnm, say 7nm, as native resolution, would the machinations to print up, say 28nm, be more work than the current process of printing down?
bji - Thursday, July 2, 2020 - link
Very likely you meant 0.2 PICOjoules of energy consumed per bit, not 0.2 PETAjoules.JayNor - Thursday, July 2, 2020 - link
Someone from Intel mentioned that they have a chiplet version of their LTE modem that can go in the stacked design. I don't recall where the interview is, though...Deicidium369 - Thursday, July 2, 2020 - link
https://tech.hindustantimes.com/tech/news/intel-s-... makes mention of Lakefield and an LTE modem."chiplet" is a marketing term.
Ian Cutress - Monday, July 20, 2020 - link
We asked that with our interview with Ramune Nagisetty from Intel. They say they can do it, but it's not done here.brucethemoose - Thursday, July 2, 2020 - link
Theres potential for another Micron partnership here, as Intel needs custom stackable DRAM dies with TSVs that they can stick below a compute die. Going through the package and back up to memory with a long, narrow interface seems like a tremendous waste of power.And That 4-atom cluster takes up as much space as a AVX-less sunny cove die... a bunch of those would be interesting in a reticle size or EPYC-style Xeon. Cloud providers subdivide giant Xeons into smaller instances anyway, and I imagine that many customers would prefer 4 full cores for the same cost as a single hyperthreaded one. Thats more or less what AWS is pitching with their Graviton chips.
nandnandnand - Thursday, July 2, 2020 - link
Just imagine a 256-core Gracemont or later Atom CPU using chiplets. That could be great for servers.That's basically a return to Xeon Phi, except those cores were modified to do AVX-512.
brucethemoose - Thursday, July 2, 2020 - link
Indeed. In hindsight, Intel designed and pushed Phi towards the wrong market.