The Intel Lakefield Deep Dive: Everything To Know About the First x86 Hybrid CPU
by Dr. Ian Cutress on July 2, 2020 9:00 AM ESTHow To Treat a 1+4 Hybrid CPU
At the top of the article, I explained that the reason for using two different types of processor core, one big on performance and the other big on efficiency, was that users could get the best of both worlds depending on if a workload could be run efficiently in the background, or needed the high performance for a user experience interaction. You may have caught onto the fact that I also stated that because Intel is using a 1+4 design, it actually makes more sense for multi-threaded workloads to run on the four Atom cores.
Using a similar power/performance graphs, the effect of having a 1+4 design is quite substantial. On the left is the single core power/performance graphs, but on the right is when we compare 1 Sunny Cove to all 4 Tremont cores working together.
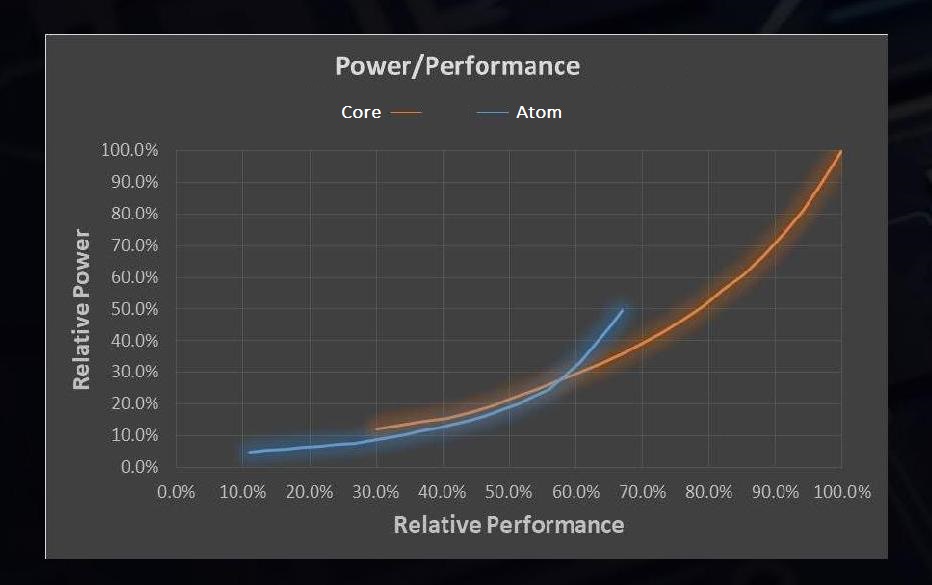
Where the previous graph considered a 1+1 design, which is more relevant in those user experience scenarios listed above, on the right is the 1+4 design for when the user demands a heavier workload that might not be latency critical. Because there are four Atom cores, the blue line multiplies by four in both directions.
Now obviously the real world scenario is somewhere between the two, as it is possible to use only one, two, or three of the smaller cores at any given time. The CPU and the OS is expected to know this, so it can govern when workloads that can be split across multiple cores end up on either the big core or the small core.

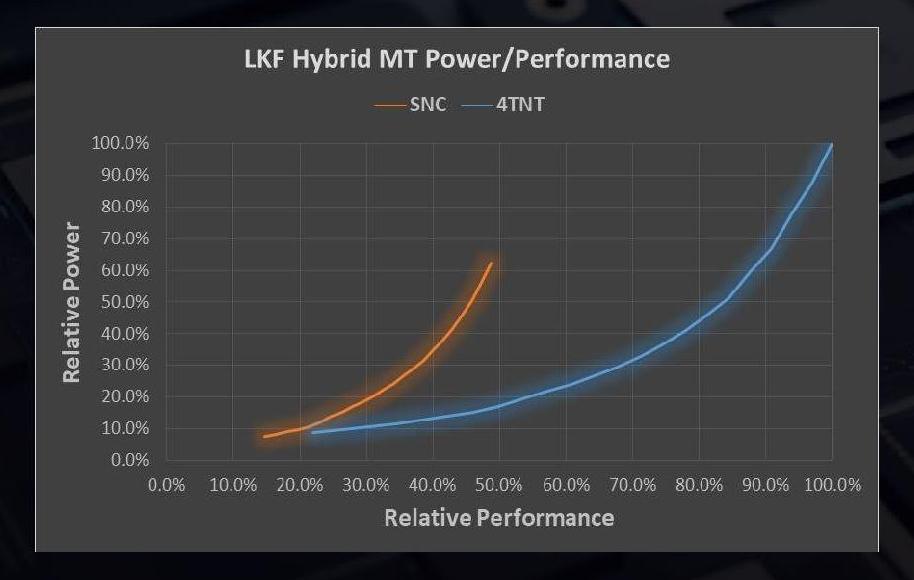
In this graph from Intel, we have three distinct modes on which threads can operate.
- ‘Sunny Cove/SNC’ is for responsiveness and user experience threads,
- ‘Tremont/TNT Foreground’, for user related tasks that require multiple threads that the user is waiting on.
- ‘Tremont/TNT Background’, for non-user related tasks run in efficiency mode
Even though the example here is web browsing, it might be best to consider something a bit beefier, like video encoding.
If we run video encoding, because it is a user related task that requires multiple threads, it will run on the four Tremont cores (TNT FG). Anything that Windows wants to do alongside that gets scheduled as TNT BG. If we then open up the start menu, because that is a responsiveness task, that gets scheduled on the SNC core.
Is 1+4 the Correct Configuration?
Intel here has implemented a 1+4 core design, however in the smartphone space, things are seen a little differently. The most popular configuration, by far, is a 4+4 design, simply because a lot of smartphone code is written to take advantage of multiple foreground or multiple background threads. There are a number of cost-down designs that reduce die area and power by going for a 2+4 implementation. Everyone seems adamant that 4 is a good number for the smaller cores, partly because they are small and cheap to add, but because Arm’s quad-core implementation is a base unit for its IP.
The smartphone space in recent quarters has also evolved from a two tier system of cores. In some of the more leading edge designs, we now have three types of core: a big, a middle, and a small. Because of the tendency to stay with eight core designs, we now get 1+3+4 or 2+2+4 designs, powered by complex schedulers that manage where to put the threads for the best user experience, the best battery life, or somewhere in the middle. Mediatek has been famously dabbling in 10 core designs, going for a 2+4+4 approach.
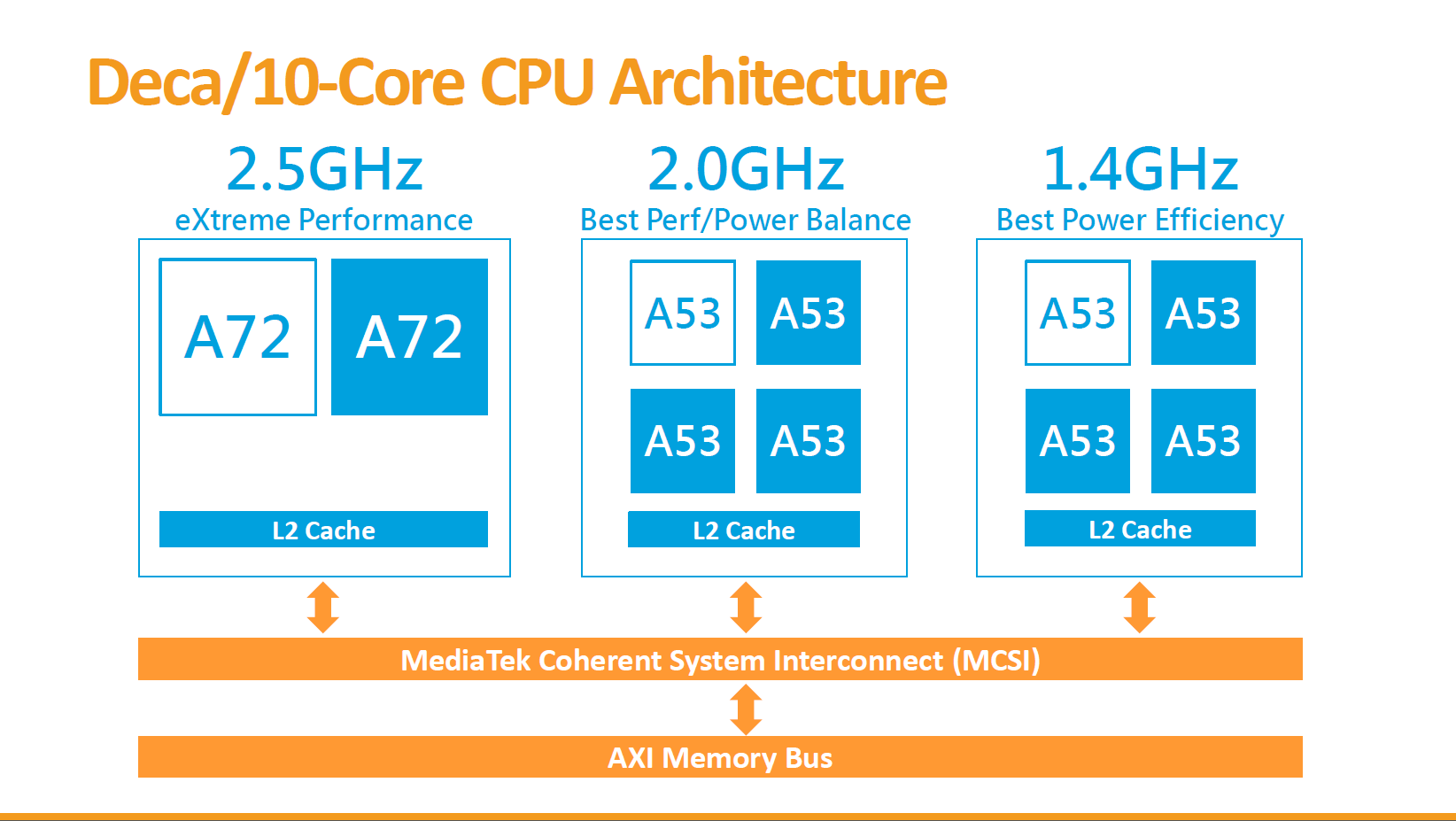
One thing missing from all of these implementations is an SoC with one big core and four small cores. Smartphone vendors don’t seem to be interested in 1+4 silicon, and yet Intel has decided on it for Lakefield. This is borne out of decisions made on both sides.
From the smartphone perspective, when hybrid designs came about, the big cores just weren’t powerful enough on their own. In order to offer something more than simply basic, at least two cores were needed, but because of how Arm architected the big and little designs, it almost became standard to look into 4+4 implementations of big and small cores. It was only until this configuration was popularized over a couple of years, and Arm big cores got more powerful, that chip designs started looking at 2+4, or 1+3+4 designs.
On Intel’s side of the fence, the biggest problem it has is the size of the Sunny Cove core. By comparison, it’s really, really big. Because the graphics core is the same as Ice Lake and reuses its design, there simply isn’t enough room within the 82 mm2 compute die to add another core. Not only that, but there is a question of power. Sunny Cove wasn’t built for sub-1W operation, even in the Tremont design. We see big smartphone silicon pulling 4-5W when all eight cores are active – there is no way, based on our understanding of Intel’s designs, that we could see four (or even two) Sunny Cove cores being in the optimal performance per watt range while being that low. Intel’s Lakefield graphics, with 64 EUs, is running at only 500 MHz – a lot lower than the Ice Lake designs. Even if Intel moved that down to a 32 EU design to make space for another Sunny Cove core, I reckon that it would eat the power budget for breakfast and then some.
Intel has made the 1+4 design to act as a 0+4 design that sometimes has access to a higher performance mode. Whereas smartphone chips are designed for all eight cores to power on for sustained periods, Lakefield is built only for 0+4 sustained workloads. And that might ultimately be its downfall. This leads onto a deep discussion about Lakefield’s performance, and what we should expect from it.








221 Comments
View All Comments
ichaya - Sunday, July 12, 2020 - link
You've claimed ARM64 has a code density advantage without any evidence for a few posts now. Being byte-aligned has advantages too, which are clear in the paper with the real world program! You're welcome to provide more real world evidence!We're changing the goal posts now with new numbers, you can't estimate IPC based on one specific INTrate2006 test, and assume it's similar across other workloads as well. If we just stick to INTrate2006, IPC seems within 5% where Graviton 2 has twice the cache of AMD Epyc 7742.
Comparing a top-line power number like you were doing is irrelevant when features like AVX can easily blow past any power envelope you might have, and one chip lacks the feature.
Wilco1 - Sunday, July 12, 2020 - link
No, I am stating that AArch64 has better code density as a fact. Maybe 5 years ago you could argue about it as AArch64 was still relatively new, but today that's not even disputable. So check it out if you'd like to see it for yourself.I used the overall intrate result to get an accurate IPC comparison. If you do the math correctly you'll see that Graviton 2 has 12% higher IPC than EPYC 7742.
At the end of the day what matters is performance, perf/W and cost. Whether you have AVX or not is not relevant in this comparison - EPYC 7742 uses the same amount of power whether it executes AVX code or not.
ichaya - Tuesday, July 14, 2020 - link
This is not the first time I've seen someone look at single thread performance and disregard everything else. All Graviton 2 and A13 single thread gains can be attributed to large (100~200% more) shared L2/L3 caches, and when compared with x86, 5% or even 75% IPC gains turn out to be ~10% less real world performance or ~10% more with marginal power use difference on 7nm. AMD has everything from a 15W to 280W chip.For multi-threaded, the Graviton 2 looks better, but the 64 vcpu EPYC 2 c5a.16xlarge (144MB L2+L3) AWS instance costs the same as the 64 core Graviton 2 m6g.16xlarge (96MB L2+L3) instance and delvers equivalent performance on real world tasks while having 1/2 the real cores, 1/2 the system RAM and 50% more L2+L3.
perf/W/$ is important, and since ARM has always been on the lower end of W and $, it can be hard to see past it. If you can compare cache sizes, power and real world performance, the only thing revolutionary is the fact that Amazon, Apple and the ARM ecosystem have come this far in a few years. The overall features (AVX2+SMT among others) and openness still leaves a lot to be desired.
Wilco1 - Wednesday, July 15, 2020 - link
Single threaded performance is important in showing that x86 does no longer have the big advantage it once used to have. Overall throughput is well correlated with single thread performance, you can see that clearly in the results we discussed. Do you believe 64 Graviton 1 cores would do equally well against 7742 if they had the same huge caches?I haven't seen serious benchmarks on c5a, do you have a link? With 32 cores at 3.3GHz it should burn well over 200W, not an improvement...
It's not that revolutionary if you followed the rapid increase of single thread performance over the last 5 years. Smartphones paid for the progress in microarchitecture and process technology that enabled competitive Arm servers (it helped AMD surpass Intel as well). I don't believe SMT or AVX are useful - 128 cores in Altra Max will beat 64 cores with SMT+AVX on performance and area at similar power.
As for AVX, this article discusses how Intel's latest CPU disables AVX... Linus had some interesting comments recently about the fragmentation of the many AVX variants. Then there are all the unresolved clocking and power issues. It's a mess.
ichaya - Thursday, July 16, 2020 - link
If there was a significant power difference between m6g.16xlarge and c5a.16xlarge, they would be priced differently. 128GB of RAM can't be more than ~15W.Single thread performance can help multi-thread performance up to a point, but SMT, non-boost clocks, and biasing towards TLP more than ILP (like an in-order GPU) can hurt single thread performance at the expense of more multi-threaded throughput.
AVX-512 is a mess, but AVX2 is worth having in most contexts now. Maybe some AVX512 instructions worth having will make it into a AVX2.1 which can completely supersede AVX2. For the price of Lakefield, there are certainly more attractive options, though compatibility, packaging and performance can trump battery life.
Wilco1 - Thursday, July 16, 2020 - link
Well there is a much better comparison, c6g.16xlarge has 128GB and is 12% cheaper than c5a.16xlarge. More than enough to pay for the electricity cost of the 280W TDP of c5a.Yes you can optimize for multithreaded throughput but SMT remains questionable, especially for large core counts. Why add SMT when you could just add some more cores?
Indeed AVX512 is worse, and could be removed without anyone missing it. Lakefield battery life comparisons are in, the Atom curse has struck yet again...
ichaya - Thursday, July 16, 2020 - link
12% is probably more the amount of subsidies these instances are getting. Amazon has a very very long history of putting any profit margins back into growth. Either that, or 128GB of RAM is 100W+!SMT is perhaps the lowest level at which TLP can be extracted, recent multi-core Atoms don't have it, but for server/workstation tasks like compilation, DB engine or even general multi-tasking, it's well worth it.
Wilco1 - Friday, July 17, 2020 - link
Graviton 2 is less than a third of the silicon area of EPYC so cheaper to make. 128GB server DRAM costs over $1000, which is why the 256GB/512GB versions are more expensive. The power cost of extra DRAM is a tiny fraction of that.There are tasks where SMT helps but equally there also tasks where it is slower. So it looks great on marketing slides where you just show the best cases, but overall it is a small gain.
ichaya - Saturday, July 18, 2020 - link
I wouldn't call a 64 vcpu (180W) system beating or equaling a 64 core (110W) system in web serving/DB and code compilation a small gain. The tasks where SMT hurts is basically single threaded JS, which is just such a shame. Shame! I don't think POWER, SPARC and others have been wrong in having added SMT years ago.For code compilation and DB the differences are 50%-100%+ making perf/W/$ very competitive.
https://www.phoronix.com/scan.php?page=article&...
This article also seems to mention SMT might make an appearance in the next Neoverse N* chips: https://www.nextplatform.com/2019/02/28/arm-sharpe...
Wilco1 - Sunday, July 19, 2020 - link
The Phoronix link has various benchmarks that aren't even running identical code between different ISAs (eg. Linux kernel compile). So it's not anywhere near a fair CPU comparison like SPEC. And this: https://openbenchmarking.org/result/1907314-AS-RYZ... shows SMT gives almost no gain on multithreaded benchmarks once you stop cherry picking the good results and ignore the bad ones...Even if we just consider the benchmarks with the largest SMT speedup, Coremark and 7-zip have good SMT gains of 41% and 32%, but m6g *still* outperforms c5a by 5% and 24%.
So the best SMT gain combined with a 32% frequency advantage and 4 times the L3 cache is still not enough to provide equal per-thread performance!