AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM ESTJava Performance
The SPECjbb 2015 benchmark has 'a usage model based on a world-wide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations'. It uses the latest Java 7 features and makes use of XML, compressed communication, and messaging with security.
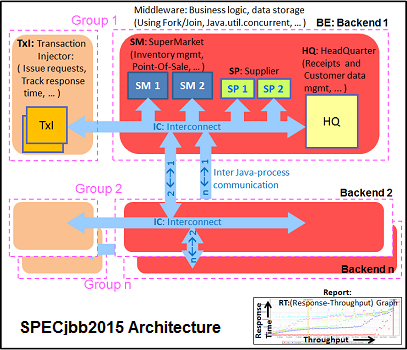
We test SPECjbb with four groups of transaction injectors and backends. The reason why we use the "Multi JVM" test is that it is more realistic: multiple VMs on a server is a very common practice.
The Java version was OpenJDK 1.8.0_222. We used the older JDK 8 as the most recent JDK 11 has removed some deprecated JAVA EE modules that SPECJBB 1.01 needs. We applied relatively basic tuning to mimic real-world use, while aiming to fit everything inside a server with 128 GB of RAM:
We tested with huge pages on and off.
The graph below shows the maximum throughput numbers for our MultiJVM SPECJbb test. Since the test is almost identical to the one that we have used in our ThunderX2 review (JDK8 1.8.0_166), we also include Cavium's server CPU.
Ultimately we publish these numbers with a caveat: you should not compare this with the official published SPECJBB2015 numbers, because we run our test slightly differently to the official run specifications. We believe our numbers make as much sense (and maybe more) as most professionals users will not go for the last drop of performance. Using these ultra optimized settings can result in unrepeateable and hard to debug inconsistent errors - at best they will result in subpar performance as they are so very specific to SPECJBB. It is simply not worth it, a professional will stick with basic and reliable optimization in the real non-HPC world. In the HPC world, you simply rerun your job in case of an error. But in the rest of the enterprise world you just made a lot users very unhappy and created a lot of work for (hopefully) well paid employees.
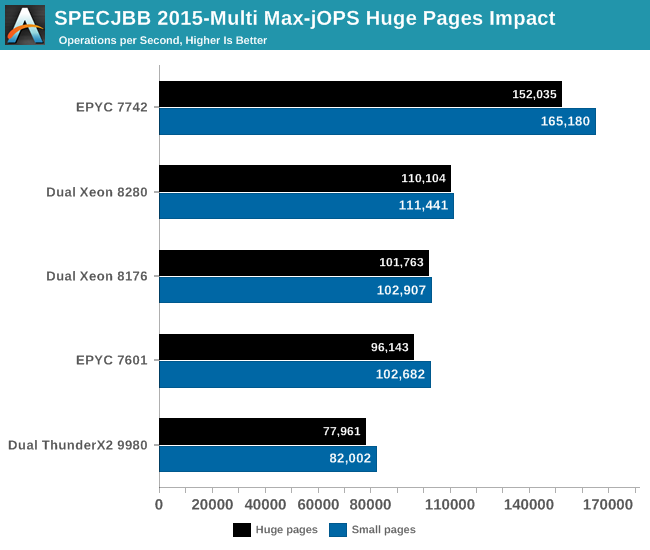
The EPYC 7742 performance is excellent, outperforming the best available Intel Xeon by 48%.
Notice that the EPYC CPU performs better with small pages (4 KB) than with large ones (2 MB). AMD's small pages TLB are massive and as result page table walks (PTW) are seldom with large pages. If the number of PTW is already very low, you can not get much benefit from increasing the page size.
What about Cavium? Well, the 32-core ThunderX2 was baked with a 16 nm process technology. So do not discount them - Cavium has a unique opportunity as they move the the ThunderX3 to 7 nm FFN TSMC too.
To be fair to AMD, we can improve performance even higher by using numactl and binding the JVM to certain CPUs. However, you rarely want to that, and happily trade that extra performance for the flexibility of being able to start new JVMs when you need them and let the server deal with it. That is why you buy those servers with massive core counts. We are in the world of micro services, docker containers, not in the early years of 21st century.
Ok, what if you do that anyway? AMD offered some numbers, while comparing them to the officialy published SPEJBB numbers of Lenovo ThinkSystem SR650 (Dual Intel 8280).

AMD achieves 335600 by using 4 JVM per node, binding them to "virtual NUMA nodes".
Just like Intel, AMD uses the Oracle JDK, but there is more to these record breaking numbers. A few tricks that only benchmarking people can use to boost SPECJBB:
- Disabling p-states and setting the OS to maximum performance (instead of balanced)
- Disabling memory protection (patrol scrub)
- Using older garbage collector because they happen to better at Specjbb
- Non-default kernel settings
- Aggressive java optimizations
- Disabling JVM statistics and monitoring
- ...
In summary, we don't think that it is wise to mimic these settings, but let us say that AMD's new EPYC 7742 is anywhere between 48 and 72% faster. And in both cases, that is significant!








180 Comments
View All Comments
schujj07 - Friday, August 9, 2019 - link
The problem is Microsoft went to the Oracle model of licensing for Server 2016/19. That means that you have to license EVERY CPU core it can be run on. Even if you create a VM with only 8 cores, those 8 cores won't always be running on the same cores of the CPU. That is where Rome hurts the pockets of people. You would pay $10k/instance of Server Standard on a single dual 64 core host or $65k/host for Server DataCenter on a dual 64 core host.browned - Saturday, August 10, 2019 - link
We are currently a small MS shop, VMWare with 8 sockets licensed, Windows Datacenter License. 4 Hosts, 2 x 8 core due to Windows Licensing limits. But we are running 120+ majority Windows systems on those hosts.I see our future with 4 x 16 core systems, unless our CPU requirements grow, in which case we could look at 3 x 48 or 2 x 64 core or 4 x 24 core and buy another lot of datacenter licenses. Because we already have 64 cores licensed the uplift to 96 or 128 is not something we would worry about.
We would also get a benefit from only using 2, 3, or 4 of our 8 VMWare socket licenses. We could them implement a better DR system, or use those licenses at another site that currently use Robo licenses.
jgraham11 - Thursday, August 8, 2019 - link
so how does it work with hyper threaded CPUs? And what if the server owner decides to not run Intel Hyperthreading because it is so prone to CPU exploits (most 10 yrs+ old). Does Google still pay for those cores??ianisiam - Thursday, August 8, 2019 - link
You only pay for physical cores, not logical.twotwotwo - Thursday, August 8, 2019 - link
Sort of a fun thing there is that in the past you've had to buy more cores than you need sometimes: lower-end parts that had enough CPU oomph may not support all the RAM or I/O you want, or maybe some feature you wanted was absent or disabled. These seem to let you load up on RAM and I/O at even 8C or 16C (min. 1P or 2P configs).Of course, some CPU-bound apps can't take advantage of that, but in the right situation being able to build as lopsided a machine as you want might even help out the folks who pay by the core.
azfacea - Wednesday, August 7, 2019 - link
FNikosD - Wednesday, August 7, 2019 - link
Ok guys...The Anandtech's team had a "bad luck and timming issues" to offer a true and decent review of the Greatest x86 CPU of all time, so for a proper review of EPYC Rome coming from the most objective and capable site for servers, take a look here:https://www.servethehome.com/amd-epyc-7002-series-...
anactoraaron - Thursday, August 8, 2019 - link
Fphoenix_rizzen - Saturday, August 10, 2019 - link
Review article for new CPU devolves into Windows vs Linux pissing match, completely obscuring any interesting discussion about said hardware. We really haven't reached peak stupid on the internet yet. :(The Benjamins - Wednesday, August 7, 2019 - link
Can we get a C20 benchmark for the lulz?