AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM ESTMemory Subsystem: TinyMemBench
We doublechecked our LMBench numbers with Andrei's custom memory latency test.
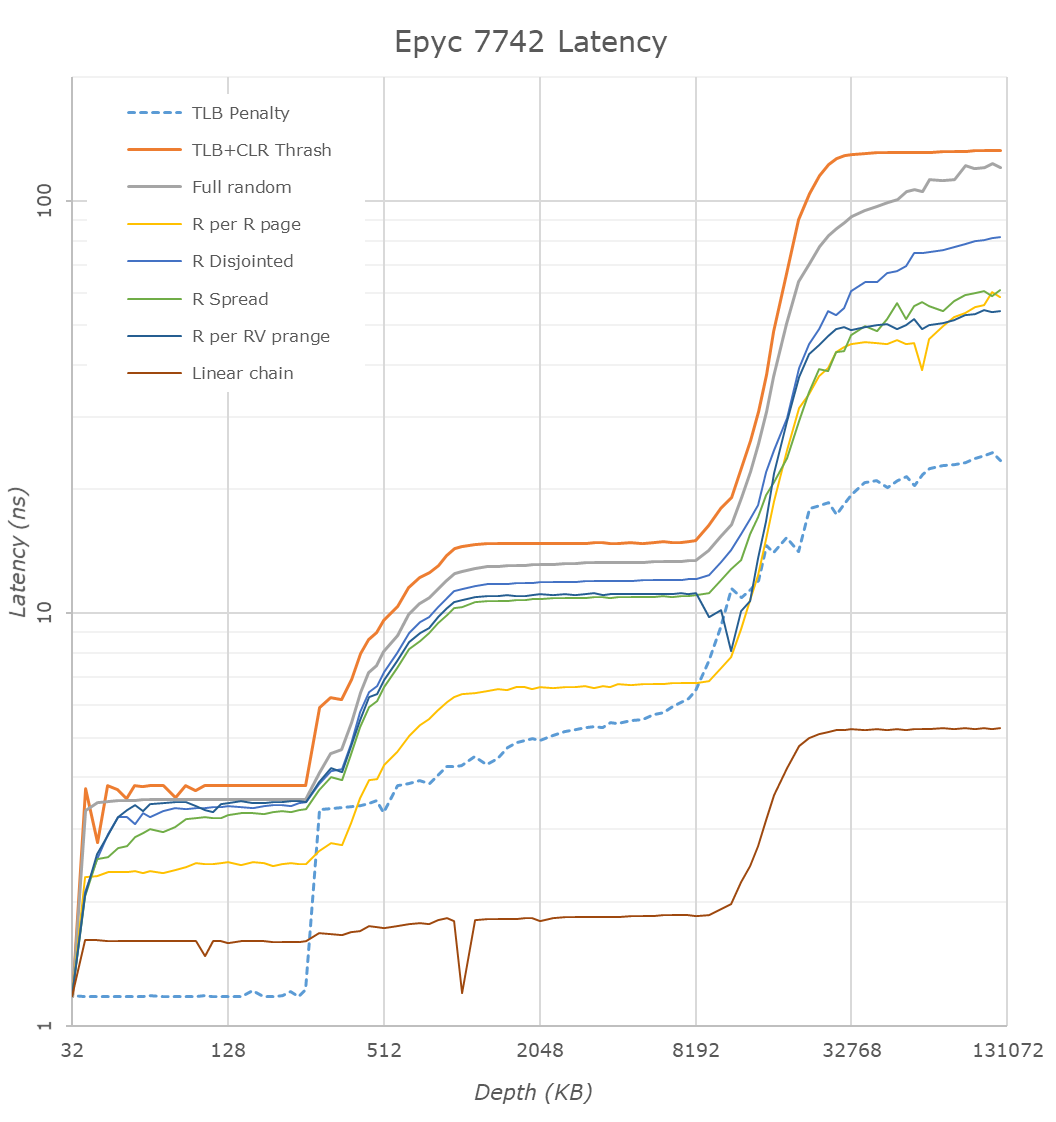
The latency tool also measures bandwidth and it became clear than once we move beyond 16 MB, DRAM is accessed. When Andrei compared with our Ryzen 9 3900x numbers, he noted:
The prefetchers on the Rome platform don't look nearly as aggressive as on the Ryzen unit on the L2 and L3
It would appear that parts of the prefetchers are adjusted for Rome compared to Ryzen 3000. In effect, the prefetchers are less aggressive than on the consumer parts, and we believe that AMD has made this choice by the fact that quite a few applications (Java and HPC) suffer a bit if the prefetchers take up too much bandwidth. By making the prefetchers less aggressive in Rome, it could aid performance in those tests.
While we could not retest all our servers with Andrei's memory latency test by the deadline (see the "Murphy's Law" section on page 5), we turned to our open source TinyMemBench benchmark results. The source was compiled for x86 with GCC and the optimization level was set to "-O3". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
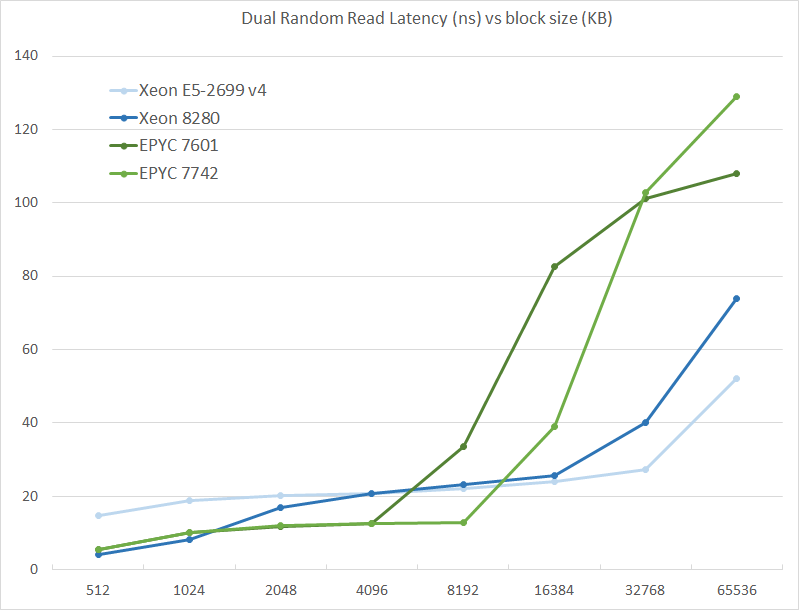
The graph shows how the larger L3 cache of the EPYC 7742 resulting in a much lower latency between 4 and 16 MB, compared to the EPYC 7601. The L3 cache inside the CCX is also very fast (2-8 MB) compared to Intel's Mesh (8280) and Ring topologies (E5).
However, once we access more than 16 MB, Intel has a clear advantage due to the slower but much larger shared L3 cache. When we tested the new EPYC CPUs in a more advanced NUMA setting (with NPS = 4 setting, meaning 4 nodes per socket), latency at 64 MB lowered from 129 to 119. We quote AMD's engineering:
In NPS4, the NUMA domains are reported to software in such a way as it chiplets always access the near (2 channels) DRAM. In NPS1 the 8ch are hardware-interleaved and there is more latency to get to further ones. It varies by pairs of DRAM channels, with the furthest one being ~20-25ns (depending on the various speeds) further away than the nearest. Generally, the latencies are +~6-8ns, +~8-10ns, +~20-25ns in pairs of channels vs the physically nearest ones."
So that also explains why AMD states that select workloads achieve better performance with NPS = 4.








180 Comments
View All Comments