AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
Decode
For the decode stage, the main uptick here is the micro-op cache. By doubling in size from 2K entry to 4K entry, it will hold more decoded operations than before, which means it should experience a lot of reuse. In order to facilitate that use, AMD has increased the dispatch rate from the micro-op cache into the buffers up to 8 fused instructions. Assuming that AMD can bypass its decoders often, this should be a very efficient block of silicon.
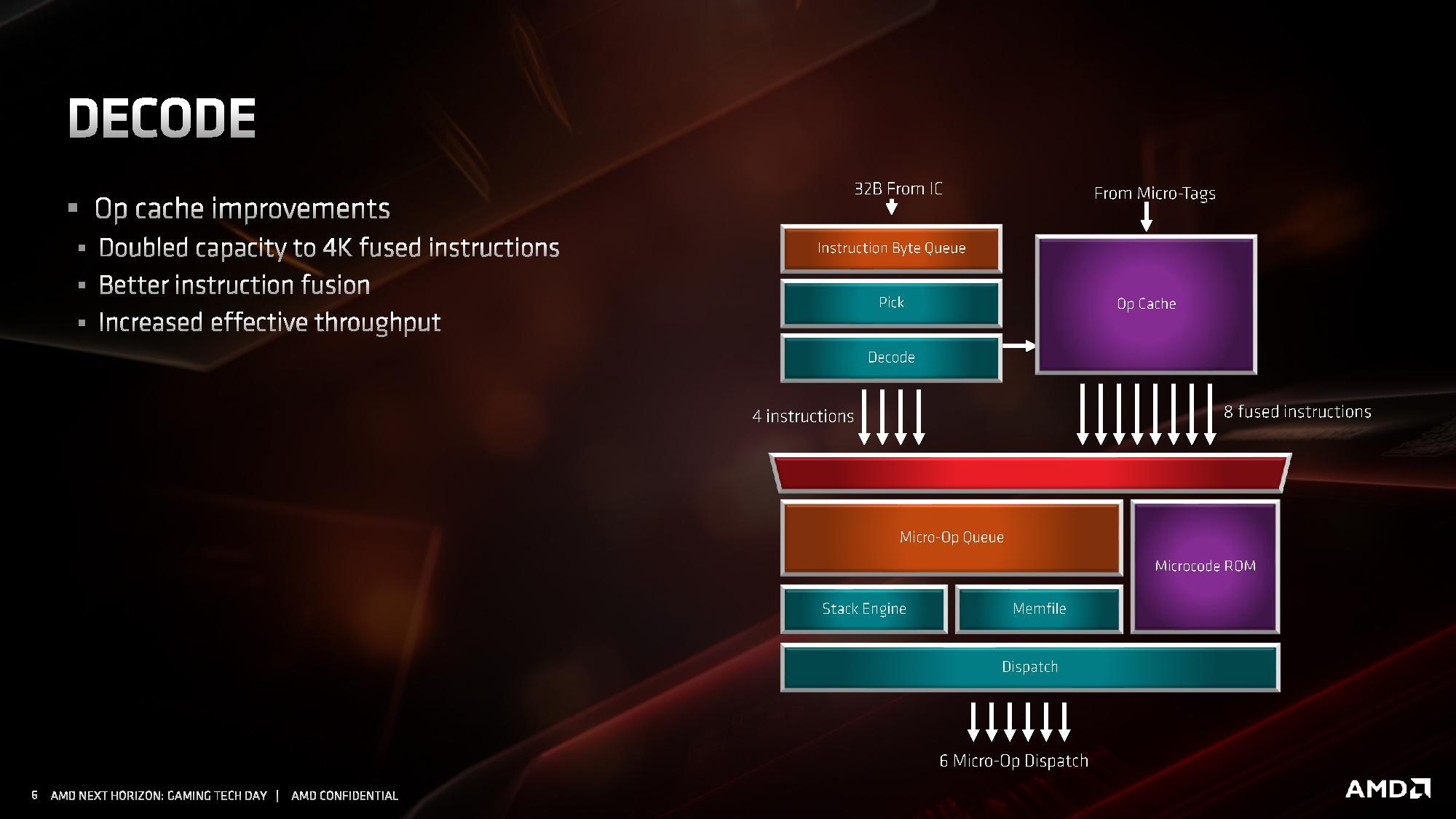
What makes the 4K entry more impressive is when we compare it to the competition. In Intel’s Skylake family, the micro-op cache in those cores are only 1.5K entry. Intel increased the size by 50% for Ice Lake to 2.25K, but that core is coming to mobile platforms later this year and perhaps to servers next year. By comparison AMD’s Zen 2 core will cover the gamut from consumer to enterprise. Also at this time we can compare it to Arm’s A77 CPU micro-op cache, which is 1.5K entry, however that cache is Arm’s first micro-op cache design for a core.
The decoders in Zen 2 stay the same, we still have access to four complex decoders (compared to Intel’s 1 complex + 4 simple decoders), and decoded instructions are cached into the micro-op cache as well as dispatched into the micro-op queue.
AMD has also stated that it has improved its micro-op fusion algorithm, although did not go into detail as to how this affects performance. Current micro-op fusion conversion is already pretty good, so it would be interesting to see what AMD have done here. Compared to Zen and Zen+, based on the support for AVX2, it does mean that the decoder doesn’t need to crack an AVX2 instruction into two micro-ops: AVX2 is now a single micro-op through the pipeline.
Going beyond the decoders, the micro-op queue and dispatch can feed six micro-ops per cycle into the schedulers. This is slightly imbalanced however, as AMD has independent integer and floating point schedulers: the integer scheduler can accept six micro-ops per cycle, whereas the floating point scheduler can only accept four. The dispatch can simultaneously send micro-ops to both at the same time however.








216 Comments
View All Comments
scineram - Wednesday, June 12, 2019 - link
No.Xyler94 - Thursday, June 13, 2019 - link
YesXyler94 - Thursday, June 13, 2019 - link
If he meant 2700x, of course. Darn misreading :Pnevcairiel - Monday, June 10, 2019 - link
A quick note. AVX2 is actually primarily Integer. AVX1 (or just AVX) is 256-bit floating point. The article often refers to "full AVX2 support", which isn't necessarily wrong, but Zen2 also adds full AVX support equally.NikosD - Saturday, June 15, 2019 - link
AVX256 is both integer and floating point because it includes AVX2 FMA which doubles floating point capability compared to AVX1NikosD - Saturday, June 15, 2019 - link
AVX256 was a typo, I meant AVX2 obviously.eastcoast_pete - Monday, June 10, 2019 - link
Thanks Ian? Two questions: what is the official memory bandwidth for the consumer chips? (Sounds like they remain dual channel) and: Any words on relative performance of AMD's AVX 2 implementation vs. Intel's AVX 512 with software that can use either?emn13 - Tuesday, June 11, 2019 - link
AVX-512 is a really misleading name; the interesting... bits... aren't the 512-bit width, but the dramatically increased flexibility. All kinds of operations are now maskable and better reshufflable, and where specific sub-segements of the vector were used, they're now sometimes usable at 1bit granularity (whereas previously that was greater).Assuming x86 sticks around for high-perf computing long enough for compilers to be able to automatically leverage it and then for most software to use it, AVX-512 is likely to be quite the game changer - but given intel's super-slow rollout so far, and AFAIK no AMD support... that's going to take a while.
Which is all a long-winded way to say that you might well expect AMDs AVX2 implementation to be not all that much slower than intel's 512 when executing code that's essentially AVX2-esque (because intel drops the frequency, so won't get the full factor 2 speedup), but AVX-512 has the potential to be *much* faster than that, because the win isn't actually in vector-width.
GreenReaper - Tuesday, June 11, 2019 - link
Intel's own product segmentation has caused it to lose its first-mover advantage here. System software aside, there's little point in most developers seeking to use instructions that most of their users will not have (and which they themselves may not have). By the time software does support it, AMD is likely to have it. And of course an increasing number of developers will be pouncing on Zen 2 thanks to fast, cheap cores that they can use to compile on...HStewart - Tuesday, June 11, 2019 - link
Intel only had AVX 512 versions in Xeon and Xeon derive chips, but the with Ice Lake ( don't really count Canon Lake test run ) AVX 512 will hit main stream starting with in a month and 2020 should be fully roll out.As for AMD AVX 2 is true 256 bit, the last I heard is that it actually like dual 128 bit unless they change it in Zen 2. I serious doubt AMD AVX 2 implement is going to any much different that Intel AVX 2 and AVX 512 is a total different beast.
It funny years ago we heard the same thing about 64 bit in x86 instructions, and now we here in 512 bit AVX.
As for as AMD support for AVX 512, that does not matter much since Intel is coming out with AVX 512 in full line over next year or so.
But keep in mind unlike normal x86 instruction, AVX is kind of specialize with vectorize processing, I know with Video processing like Power Director this was a deciding factor earlier for it.,