AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
Decode
For the decode stage, the main uptick here is the micro-op cache. By doubling in size from 2K entry to 4K entry, it will hold more decoded operations than before, which means it should experience a lot of reuse. In order to facilitate that use, AMD has increased the dispatch rate from the micro-op cache into the buffers up to 8 fused instructions. Assuming that AMD can bypass its decoders often, this should be a very efficient block of silicon.
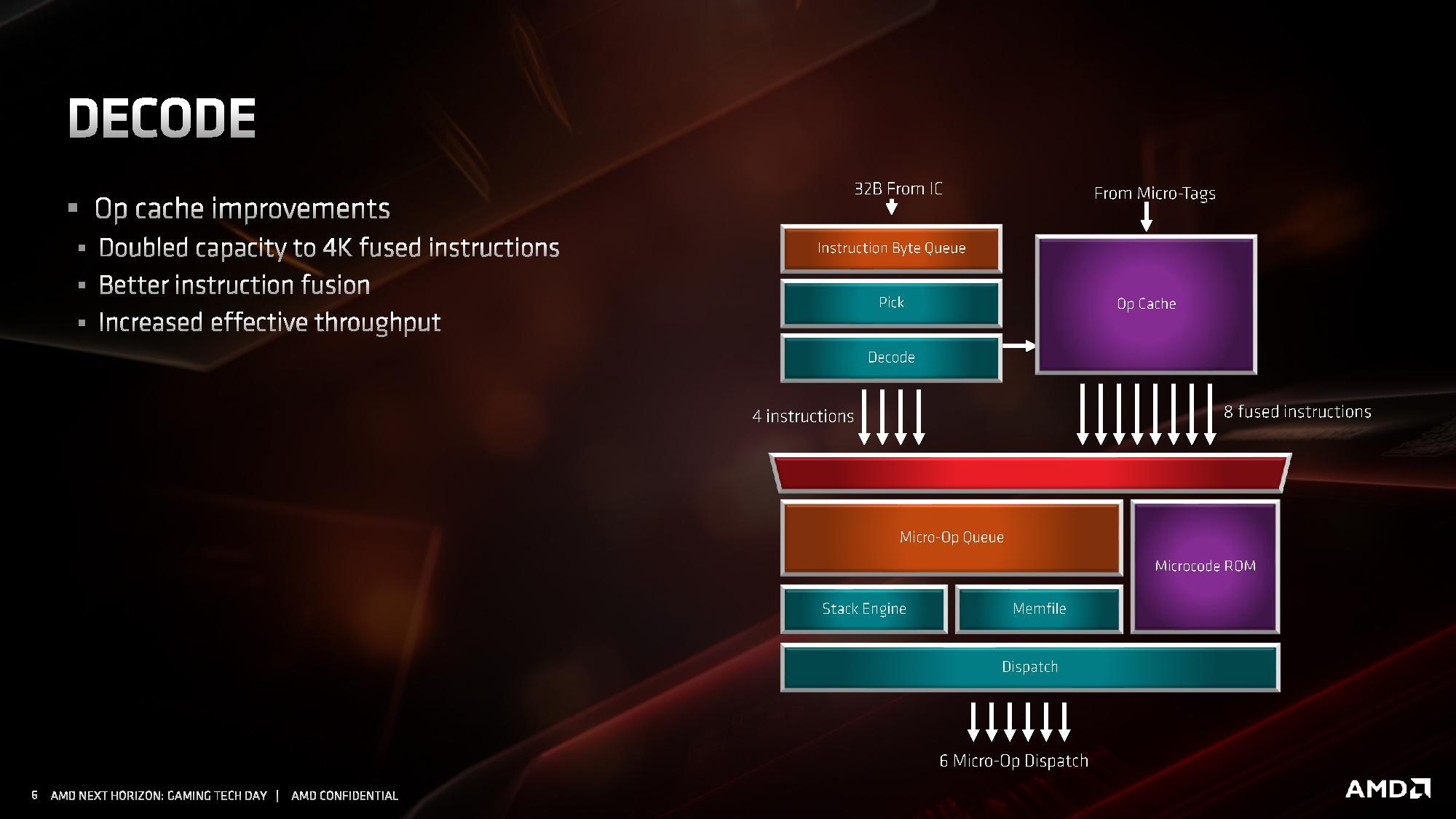
What makes the 4K entry more impressive is when we compare it to the competition. In Intel’s Skylake family, the micro-op cache in those cores are only 1.5K entry. Intel increased the size by 50% for Ice Lake to 2.25K, but that core is coming to mobile platforms later this year and perhaps to servers next year. By comparison AMD’s Zen 2 core will cover the gamut from consumer to enterprise. Also at this time we can compare it to Arm’s A77 CPU micro-op cache, which is 1.5K entry, however that cache is Arm’s first micro-op cache design for a core.
The decoders in Zen 2 stay the same, we still have access to four complex decoders (compared to Intel’s 1 complex + 4 simple decoders), and decoded instructions are cached into the micro-op cache as well as dispatched into the micro-op queue.
AMD has also stated that it has improved its micro-op fusion algorithm, although did not go into detail as to how this affects performance. Current micro-op fusion conversion is already pretty good, so it would be interesting to see what AMD have done here. Compared to Zen and Zen+, based on the support for AVX2, it does mean that the decoder doesn’t need to crack an AVX2 instruction into two micro-ops: AVX2 is now a single micro-op through the pipeline.
Going beyond the decoders, the micro-op queue and dispatch can feed six micro-ops per cycle into the schedulers. This is slightly imbalanced however, as AMD has independent integer and floating point schedulers: the integer scheduler can accept six micro-ops per cycle, whereas the floating point scheduler can only accept four. The dispatch can simultaneously send micro-ops to both at the same time however.








216 Comments
View All Comments
Targon - Thursday, June 13, 2019 - link
The TDP figures are always a bit vague, because it is about the heat generation, not about power draw. A higher TDP on a chip with the same number of cores on the same design could indicate that it will overclock higher. Intel always sets the TDP to the base clock speed, while AMD has been more about what can be expected in normal usage. The higher the clock speed, the more power will be required, and the higher the amount of heat will be that needs to be handled by the cooler.So, if a chip has a TDP of 105W, then in theory, you should be able to get away with a cooler that can handle 105W of heat output, but if that TDP is based only on the base clock speed, you will want a better cooler to allow for turbo/boost for sustained periods.
wilsonkf - Monday, June 10, 2019 - link
We want faster memory for Zen/Zen+ because we want higher IF clock, so cutting the IF clock by half to enable higher memory freq. does not make sense. However the improved IF could move the bottleneck somewhere else.AlexDaum - Tuesday, June 11, 2019 - link
It seems like IF2 can not hit frequencies higher than about 3733MHz DDR (so 1,8GHz real frequency) for some reason, so they added the ability to scale it down to have higher memory clocks. But it is probably only worth it if you can overclock memory a lot higher than 3733, so that the IF clock gets a bit higher againXyler94 - Tuesday, June 11, 2019 - link
If I recall, IF2's clock speed is decoupled from RAM speed.Cooe - Tuesday, June 11, 2019 - link
This is wrong Xyler. Still completely connected.Xyler94 - Thursday, June 13, 2019 - link
Per this exact Article:"One of the features of IF2 is that the clock has been decoupled from the main DRAM clock. In Zen and Zen+, the IF frequency was coupled to the DRAM frequency, which led to some interesting scenarios where the memory could go a lot faster but the limitations in the IF meant that they were both limited by the lock-step nature of the clock. For Zen 2, AMD has introduced ratios to the IF2, enabling a 1:1 normal ratio or a 2:1 ratio that reduces the IF2 clock in half."
It seems it has been, but it may still benefit from faster RAM still
extide - Monday, June 17, 2019 - link
It is completely connected -- you can just pick a 1:1 or 2:1 divider now but they are absolutely still tightly coupled. YOu can't just set them independently.Cooe - Tuesday, June 11, 2019 - link
You're missing the point for >3733MHz memory overclocked where the IF switches to a 2:1 divider. It's for workloads that highly prioritize memory bandwidth over latency, NOT to try and run your sticks 24/7 at like 5GHz+ for the absolute lowest latency possible (bc even then, 3733MHz will prolly still be lower).Targon - Thursday, June 13, 2019 - link
From what I remember, up to DDR4-3733, Infinity Fabric on Ryzen 3rd generation is now at a 1:1(where previously, Infinity Fabric would run at half the DDR4 speed. You can go above that, but then the improvements are not going to be as significant. For latency, your best bet is to get 3733 or 3600 with as low a CAS rating as you can get.zodiacfml - Tuesday, June 11, 2019 - link
that 105W TDP is a sign that the 8 core is efficient at 50W or a base clock of 3.5 GHz. The AMD 7nm 8-Core Zen 2 chip has a TDP equal or less than my i3-8100.😅