AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
Decode
For the decode stage, the main uptick here is the micro-op cache. By doubling in size from 2K entry to 4K entry, it will hold more decoded operations than before, which means it should experience a lot of reuse. In order to facilitate that use, AMD has increased the dispatch rate from the micro-op cache into the buffers up to 8 fused instructions. Assuming that AMD can bypass its decoders often, this should be a very efficient block of silicon.
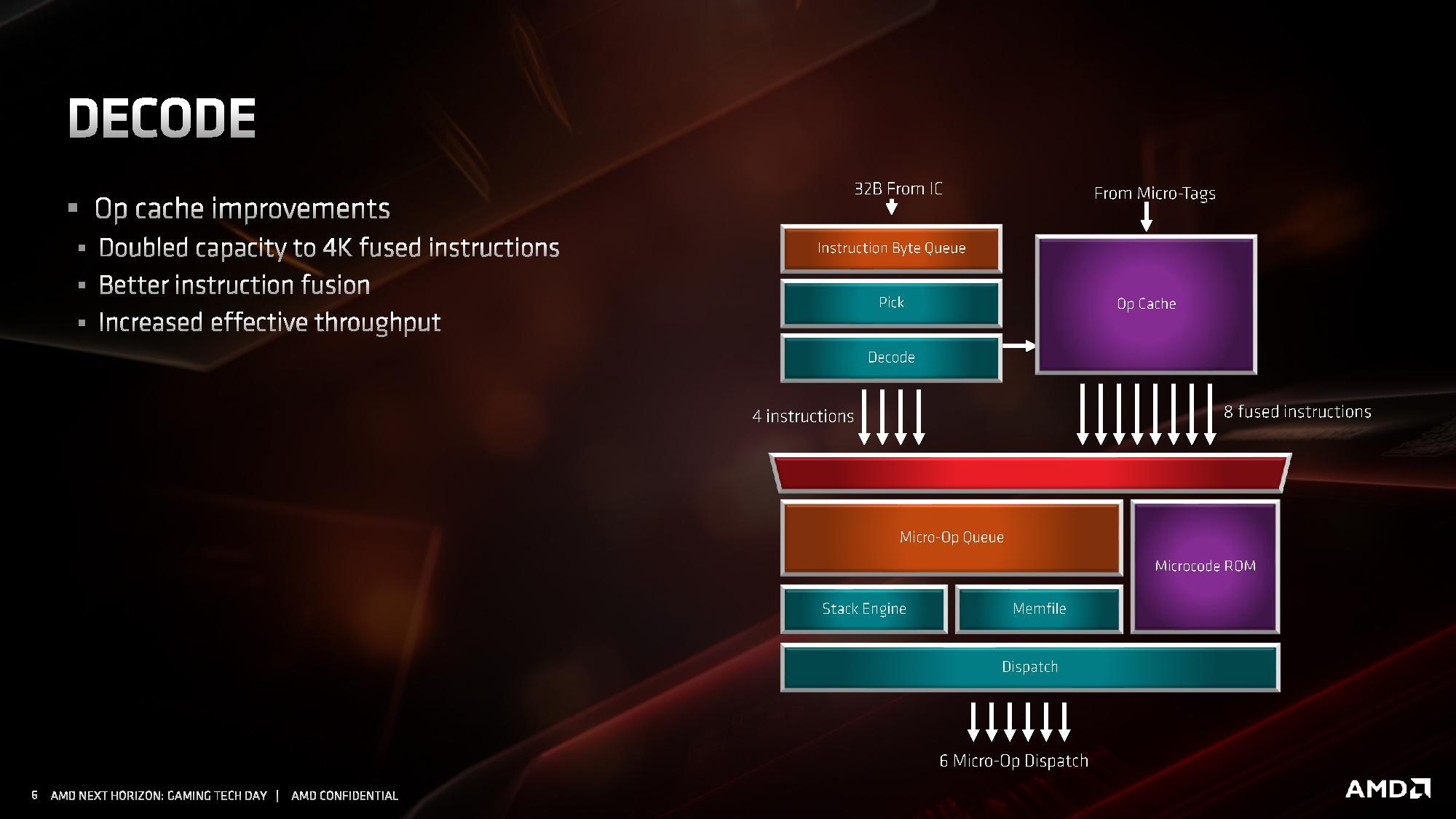
What makes the 4K entry more impressive is when we compare it to the competition. In Intel’s Skylake family, the micro-op cache in those cores are only 1.5K entry. Intel increased the size by 50% for Ice Lake to 2.25K, but that core is coming to mobile platforms later this year and perhaps to servers next year. By comparison AMD’s Zen 2 core will cover the gamut from consumer to enterprise. Also at this time we can compare it to Arm’s A77 CPU micro-op cache, which is 1.5K entry, however that cache is Arm’s first micro-op cache design for a core.
The decoders in Zen 2 stay the same, we still have access to four complex decoders (compared to Intel’s 1 complex + 4 simple decoders), and decoded instructions are cached into the micro-op cache as well as dispatched into the micro-op queue.
AMD has also stated that it has improved its micro-op fusion algorithm, although did not go into detail as to how this affects performance. Current micro-op fusion conversion is already pretty good, so it would be interesting to see what AMD have done here. Compared to Zen and Zen+, based on the support for AVX2, it does mean that the decoder doesn’t need to crack an AVX2 instruction into two micro-ops: AVX2 is now a single micro-op through the pipeline.
Going beyond the decoders, the micro-op queue and dispatch can feed six micro-ops per cycle into the schedulers. This is slightly imbalanced however, as AMD has independent integer and floating point schedulers: the integer scheduler can accept six micro-ops per cycle, whereas the floating point scheduler can only accept four. The dispatch can simultaneously send micro-ops to both at the same time however.








216 Comments
View All Comments
Thunder 57 - Sunday, June 16, 2019 - link
It appears they traded half the L1 instruction cache to double the uop cache. They doubled the associativity to keep the same hit rate but it will hold fewer instructions. However, the micro-op cache holds already decoded instructions and if there is a hit there it saves a few stages in the pipeline for decoding, which saves power and increases performance.phoenix_rizzen - Tuesday, June 11, 2019 - link
From the article:"Zen 2 will offer greater than a >1.25x performance gain at the same power,"
I don't think that means what you meant. :) 1.25x gain would be 225% or over 2x the performance. I think you meant either:
"Zen 2 will offer greater than a 25% performance gain at the same power,"
or maybe:
"Zen 2 will offer greater than 125% performance at the same power,"
or possibly:
"Zen 2 will offer greater than 1.25x performance at the same power,"
phoenix_rizzen - Tuesday, June 11, 2019 - link
From the article:"With Matisse staying in the AM4 socket, and Rome in the EPYC socket,"
The server socket name is SP3, not EPYC, so this should read:
"With Matisse staying in the AM4 socket, and Rome in the SP3 socket,"
phoenix_rizzen - Tuesday, June 11, 2019 - link
From the article:"This also becomes somewhat complicated for single core chiplet and dual core chiplet processors,"
core is superfluous here. The chiplets are up to 8-core. You probably mean "single chiplet and dual chiplet processors".
scineram - Wednesday, June 12, 2019 - link
No, becausethere is no single chiplet. It is the core chiplet that is either 1 or 2 in number.phoenix_rizzen - Tuesday, June 11, 2019 - link
From the article:"all of this also needs to be taken into consideration as provide the optimal path for signaling"
"as" should be "to"
thesavvymage - Wednesday, June 12, 2019 - link
A 1.25x gain is the exact same as a 25% performance gain, it doesnt meant 225% as you stateddsplover - Tuesday, June 11, 2019 - link
So in other words Anadtech no longer receives engineering samples but tells us what everyone else is saying.Still love coming here as reviews are good, but boy oh boy yuze guys sure slipped down the ladder.
Bring back Anand Shimpli.
Korguz - Wednesday, June 12, 2019 - link
the do still get engineering samples... but usually cpus...not likely.. hes working for apple now....
coburn_c - Wednesday, June 12, 2019 - link
What the heck is UEFI CPPC2?