AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
Cache and Infinity Fabric
If it hasn’t been hammered in already, the big change in the cache is the L1 instruction cache which has been reduced from 64 KB to 32 KB, but the associativity has increased from 4-way to 8-way. This change enabled AMD to increase the size of the micro-op cache from 2K entry to 4K entry, and AMD felt that this gave a better performance balance with how modern workloads are evolving.
The L1-D cache is still 32KB 8-way, while the L2 cache is still 512KB 8-way. The L3 cache, which is a non-inclusive cache (compared to the L2 inclusive cache), has now doubled in size to 16 MB per core complex, up from 8 MB. AMD manages its L3 by sharing a 16MB block per CCX, rather than enabling access to any L3 from any core.
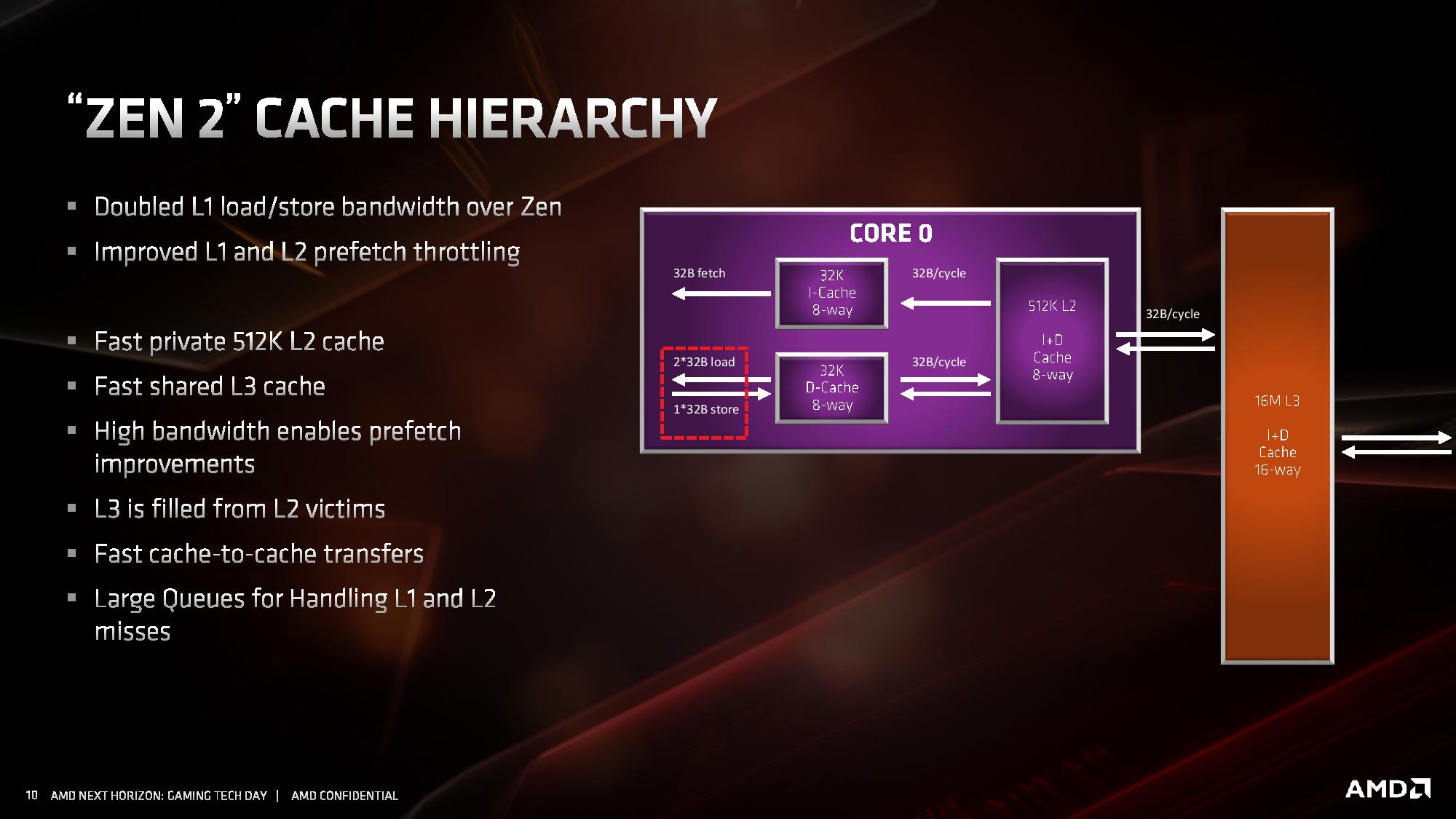
Because of the increase in size of the L3, latency has increased slightly. L1 is still 4-cycle, L2 is still 12-cycle, but L3 has increased from ~35 cycle to ~40 cycle (this is a characteristic of larger caches, they end up being slightly slower latency; it’s an interesting trade off to measure). AMD has stated that it has increased the size of the queues handling L1 and L2 misses, although hasn’t elaborated as to how big they now are.
Infinity Fabric
With the move to Zen 2, we also move to the second generation of Infinity Fabric. One of the major updates with IF2 is the support of PCIe 4.0, and thus the increase of the bus width from 256-bit to 512-bit.

Overall efficiency of IF2 has improved 27% according to AMD, leading to a lower power per bit. As we move to more IF links in EPYC, this will become very important as data is transferred from chiplet to IO die.
One of the features of IF2 is that the clock has been decoupled from the main DRAM clock. In Zen and Zen+, the IF frequency was coupled to the DRAM frequency, which led to some interesting scenarios where the memory could go a lot faster but the limitations in the IF meant that they were both limited by the lock-step nature of the clock. For Zen 2, AMD has introduced ratios to the IF2, enabling a 1:1 normal ratio or a 2:1 ratio that reduces the IF2 clock in half.
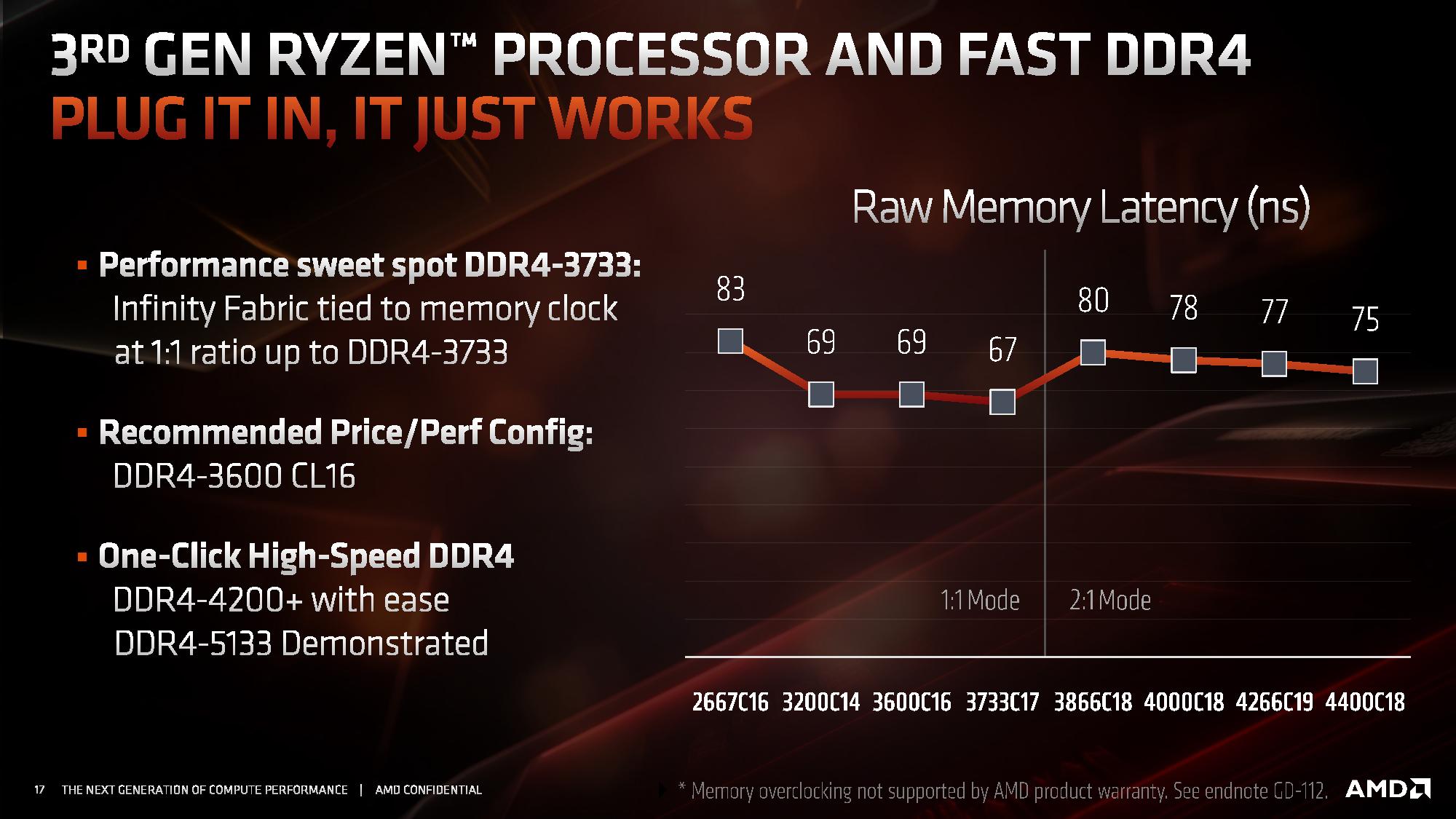
This ratio should automatically come into play around DDR4-3600 or DDR4-3800, but it does mean that IF2 clock does reduce in half, which has a knock on effect with respect to bandwidth. It should be noted that even if the DRAM frequency is high, having a slower IF frequency will likely limit the raw performance gain from that faster memory. AMD recommends keeping the ratio at a 1:1 around DDR4-3600, and instead optimizing sub-timings at that speed.








216 Comments
View All Comments
JohnLook - Monday, June 10, 2019 - link
@Ian Cutress Are you sure the Io dies are on TSMC's 14 & 12 nm processes ?all info so far was that they were on GloFo's 14 nm ...
Ian Cutress - Monday, June 10, 2019 - link
Sorry, glofo 14 and 12. Matisse IO die is Glofo 12nm. We triple confirmed.JohnLook - Monday, June 10, 2019 - link
Thanks :-)scineram - Tuesday, June 11, 2019 - link
It still says Epyc is TSMC.John_M - Tuesday, June 11, 2019 - link
It would be nice if the article was updated as not everyone reads the comments section and AnandTech articles do often get cited in Wikipedia articles.Smell This - Wednesday, June 12, 2019 - link
I feel safe in saying that Wiki-Dom will be right on it . . .;-)
So __ those little white lines are the Infinity Scalable Data Fabric (SDF) and the Infinity Scalable Control Fabric (SCF), connecting "Core" chiplets to the I/O core.
"The SDF might have dozens of connecting points hooking together things such as PCIe PHYs, memory controllers, USB hub, and the various computing and execution units."
"The SDF is a superset of what was previously HyperTransport. The SCF is a complementary plane that handles the transmission ..."
https://en.wikichip.org/wiki/amd/infinity_fabric
Of course, I counted them (rolling eyes at myself), and determined there were 32 connecting a single core chiplet to the I/O core. I'm smelling a rational relationship between those 32, and other such stuff. Are the number of IF links a proprietary secret to AMD?
Yah know? It would be a nice 'get' if a tech writer interviewed someone in that former Sea Micro bunch, and spilled a few beans . . .
Smell This - Wednesday, June 12, 2019 - link
Might be 36 ... LOL
Smell This - Wednesday, June 12, 2019 - link
Could be 42- or 46 IF links on the right(I'll stop obsessing)
sweetca - Thursday, June 13, 2019 - link
I don't understand anything you said 🙂Smell This - Sunday, June 16, 2019 - link
I was (am) trolling Ian/AT for a **Deep(er) Dive** on the Infinity Fabric -- its past, and its future. The EPYC Rome processors have 8 "Core" chiplets connecting to the I/O core. Right? Those 'little white lines' (32- to 46?) from each chiplet, presumably, scale to ... infinity?AMD purchased SeaMicro 7 years ago as the "Freedom Fabric" platform was developed. Initially the SM15000 'stitched' together 512 compute cores, 160 gigabits of I/O networking and 5+ petabytes of storage to form a 'very-high-density server.'
And then . . . they went dark.
https://www.anandtech.com/show/9170/amd-exits-dens...
(see the last comment on that link)