Intel Details Manufacturing through 2023: 7nm, 7+, 7++, with Next Gen Packaging
by Ian Cutress & Anton Shilov on May 8, 2019 4:35 PM EST
At Intel's Investor Day today, CEO Bob Swan and Murthy Renduchintala spoke to the ability of the company with respect to its manufacturing capabilities. Intel has historically been strong in its ability to execute on its process technology, however the delay of its 10nm process has obviously raised multiple question marks, and has done for several years. The two Intel executives went into a little detail about what Intel was doing in the interim, and how it has learned from the issues.

Back in 2013, Intel envisoned its 10nm to succeed the 14nm by providing 2.7x density, with new technologies such as Self-Aligned Quad Patterning (SAQP), Contact over Active Gate (COAG), Cobolt Interconnects, and new packaging technologies such as EMIB and Foveros. Intel admits that this was an ambitious plan, and the goals were not clearly defined with the teams and it was ultimately overly complex and not managed in an ideal way.
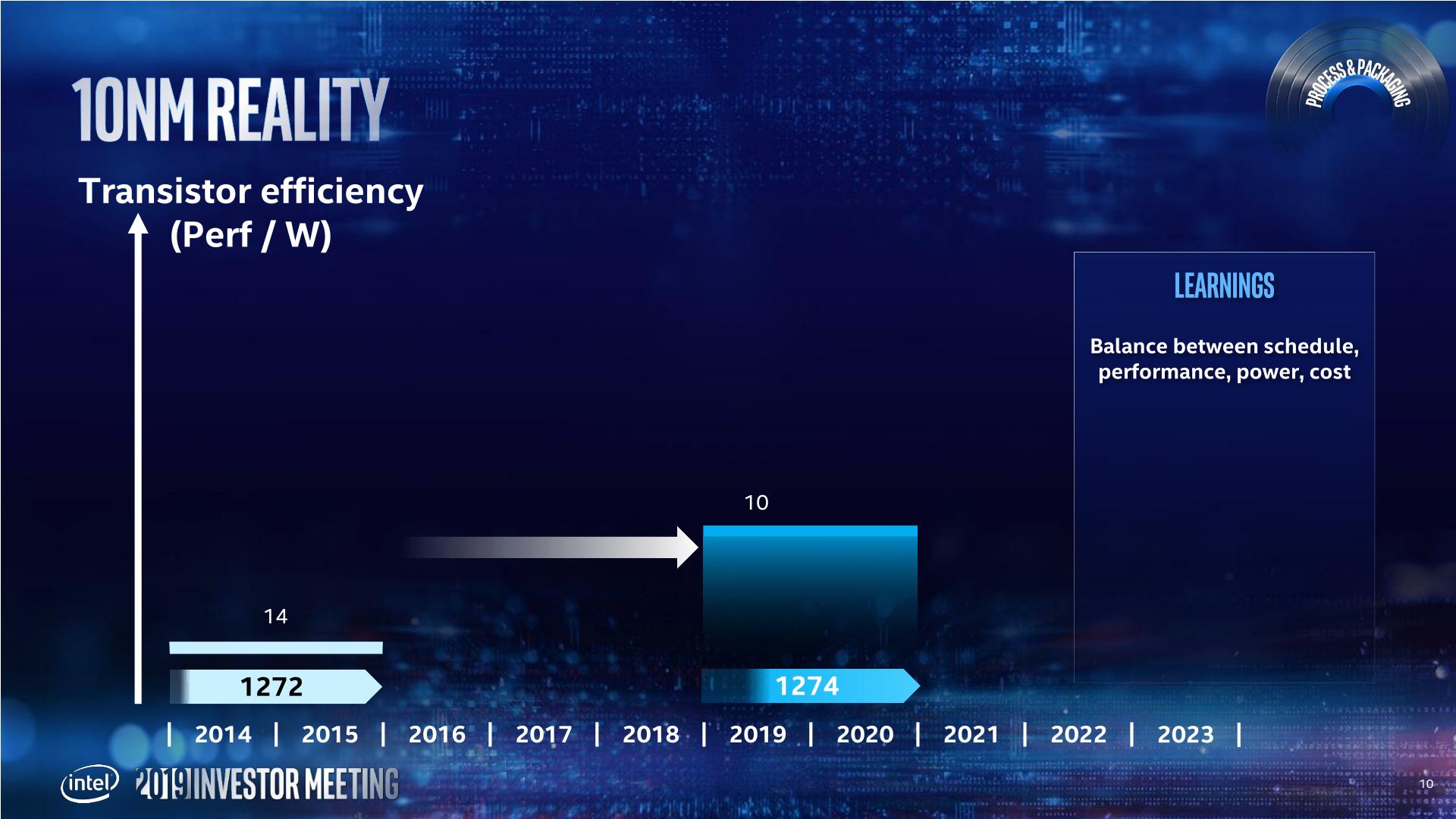
This ended up pushing 10nm out into a later time frame. In this case, Intel pushed 10nm out to 2019 (technically they shipped Cannon Lake in small quantities on 10nm in 2017, however that is nothing more than a curio in the timeline of semiconductors), and filled the gap with 14+ and 14++.
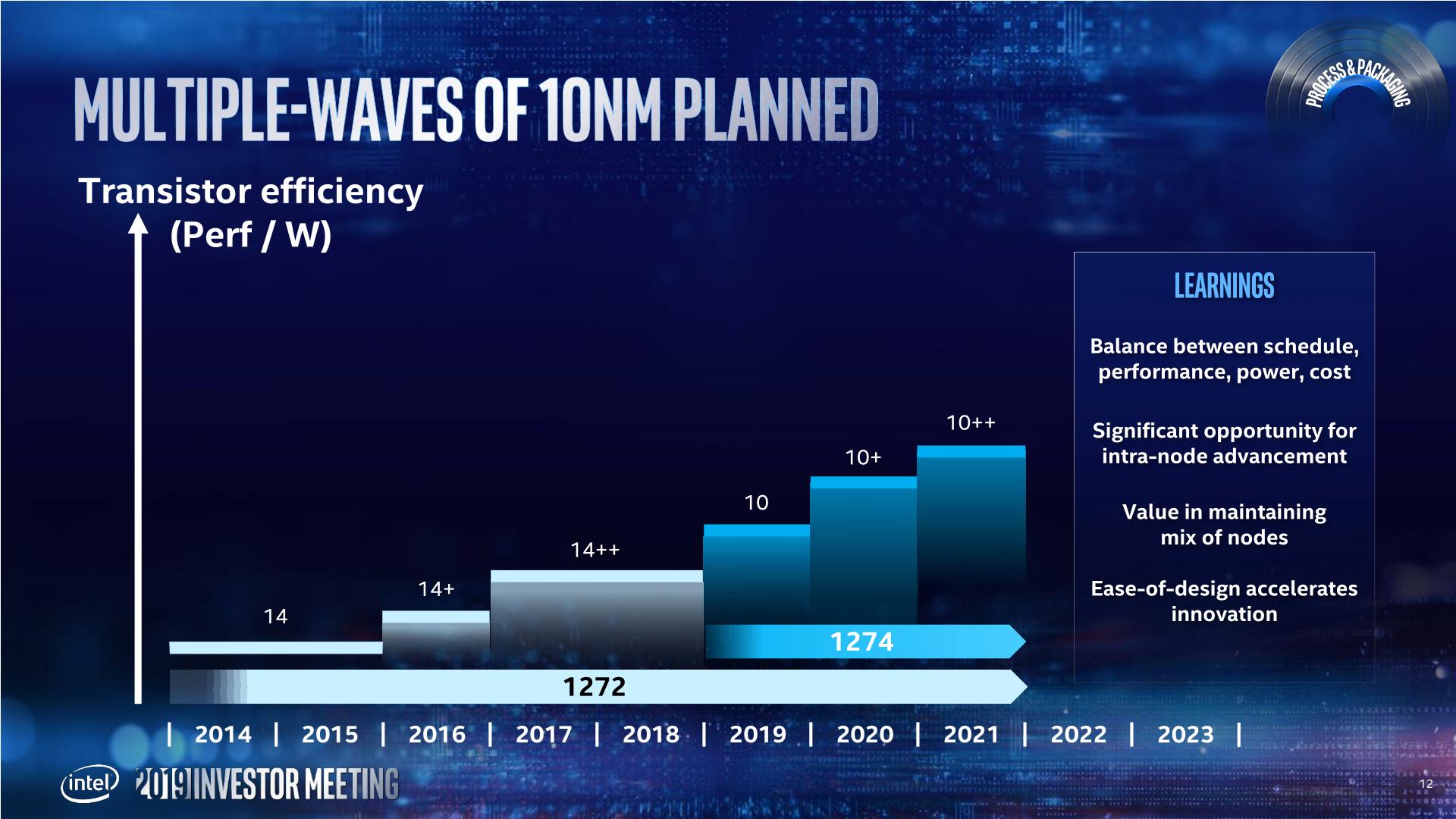
Intels 14+ and 14++ processes extracted more than 20% more performance (from Broadwell to Whiskey Lake) from the process since its inception. As a result, Intel is prepared to not only get ready for future intra-node optimizations, but actually adjust the roadmap to compensate for it. Murthy made it clear that Intel wants to introduce a Moore's Law-like gain at the beginning of a new process, and another similar gain by the end of the process.
Intel has stated that its 10nm product family (beyond Cannon Lake) will start to be available from the middle of this year (2019), with Ice Lake on client platforms (notebooks).

Intel will be launching multiple 10nm products through 2019 and 2020, including server based 10nm in the first half of 2020:

In the above slide, Intel states that it will have 7nm in production and launching a product in 2021. That sounds very aggressive for a company that has had issues with 10nm. It even shows in Intels radmap, with 10nm (and 10+ and 10++) having a much shorter life cycle than the 14nm family of processes.
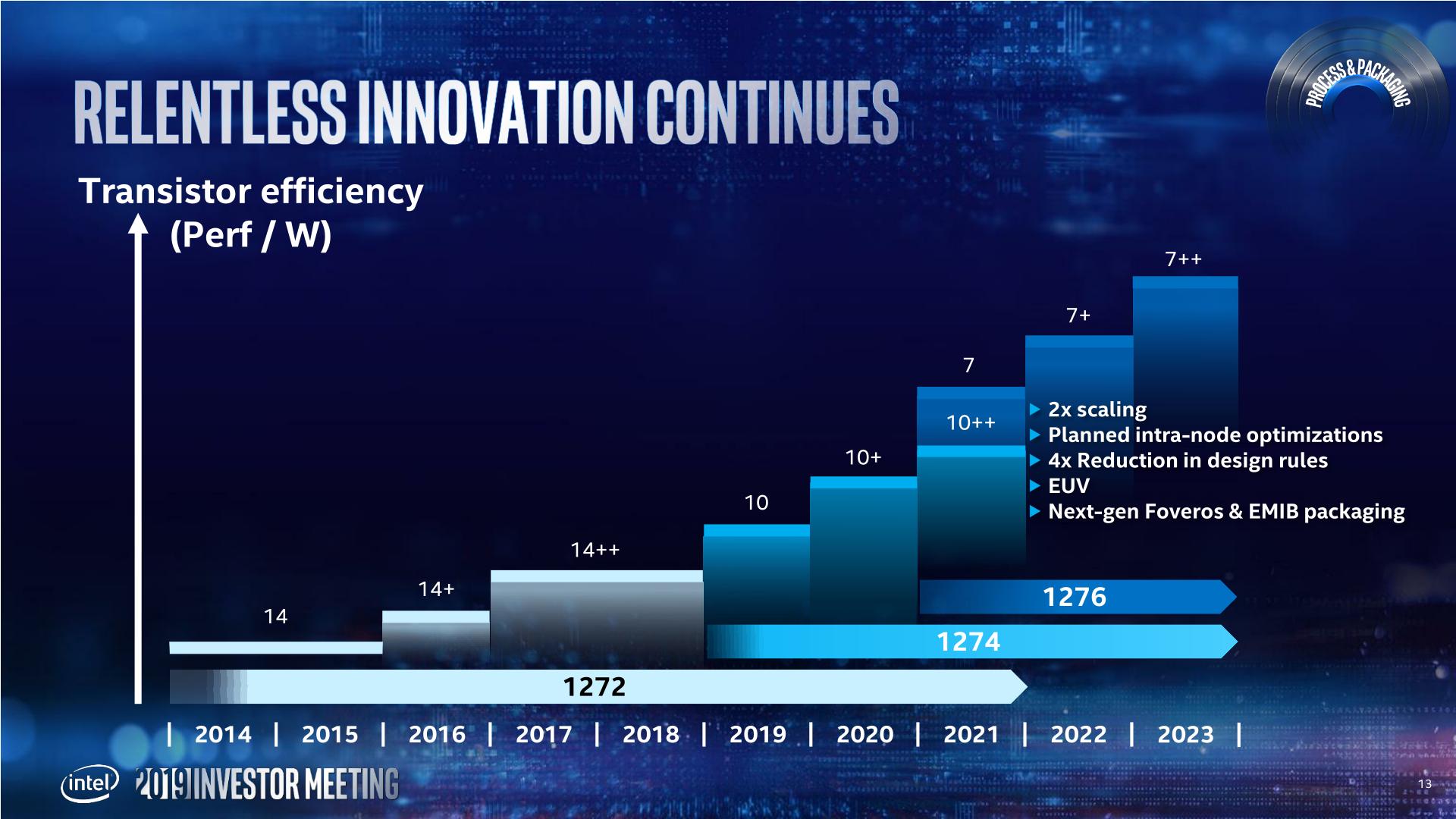
With this in mind, Intel's 7nm is going to be the combination of what Intel has learned from the 14nm and 10nm family of products. Intel wants that 2x scaling (Moores Law), but with intra-node optimations planned as part of the roadmap. Intel is also reducing its number of design rules, which should help with execution. 7nm will also be where Intel intersects with EUV, and also introduce next-gen Foveros and EMIB packainging.

Intel provided this slide, which shows a monolithic PC-Centric die with a multi-die Data-Centric chip built on both Foveros and EMIB. This corroborates our discussion with Intel's chiplet and packaging team, who also stated that we would see Foveros and EMIB on a combined product - specifically the GPU.

Intel announced that its lead 7nm product (lead = top, or lead = first?) would be its new GPGPU, built on the Xe graphics architecture. Intel has stated that its Xe product stack will feature two different microarchitectures from mobile client up to GPGPU, with one of those architectures called Arctic Sound - technically Intel will launch its first discrete GPU in 2020 according to its press release, however the 7nm GPGPU will be launched in 2021.
More information is coming out of Intel's Event, more to follow.
Related Reading
- Intel: EUV-Enabled 7nm Process Tech is on Track
- Intel Starts Qualification of Ice Lake CPUs, Raises 10nm Volume Expectation for 2019
- Intel Agilex: 10nm FPGAs with PCIe 5.0, DDR5, and CXL
- Intel to Equip Fab 42 for 7 nm
- Intel Discloses Plans to Spend $5 Billion on Fab 28 Expansion in Israel
- Intel Submits Ireland Fab Expansion Plan: $8 Billion Price Tag, With a 4 Year Lead Time
- Intel Details Plans for Its Oregon Fab Expansion: D1X Phase 3
- Intel to Expand Production Capacities at Multiple Fabs
Source: Intel








237 Comments
View All Comments
levizx - Friday, May 10, 2019 - link
Nope, you are wrong. Those measures listed are ONE specific method - Intel's. That's the transistor density for a standard 2-input NAND cell and a scan flip-flop logic cell.ats - Friday, May 10, 2019 - link
For the moment, I'll ignore the fact that your reply is incongruent with the discussion... What drive strength for the 2-input nand, what power level for the 2 input nand, etc?To the large actual point of the chain, I am entirely correct. There are effectively infinite ways to structure the actual transistors of a circuit and myriad methods to count the resultant structure as far as number of transistors. Do you just pick the smallest single cell/circuit that will work or do you use multiple parallel devices? Do you finger a device (effectively multiple transistors) or just make a bigger device? etc.
ZolaIII - Wednesday, May 8, 2019 - link
I agree with your rugh estimate that TSMC 7 nm is even with T9 lib 3x denser then intels 14 nm with high performance lib. That brings it down to 1.5x per gate which actually means if Intel can pool 2.2x (projected while achieved is always smaller gain) increase per gate it would be in (small) leed but TSMC rushed it's first gen 7 nm. Samsung with its 7nm is comparable to Intels 10 nm (they all really are 10 nm) while TSMC 7nm+ is also. TSMC 5 nm (which is completely new node) will have a 25~30% size advantage over the competition until Intel launches 7 nm but in the mean time Samsung will be developing & probably have it ready until Q2 2021 the 5 nm GAA. FinFET reached it's maximum, we are seeing more by force extension with EUV than also ain't mature enough...Wilco1 - Wednesday, May 8, 2019 - link
TSMC 7nm, Samsung 7LPP, and Intel 10nm are all close to 100 MT/mm^2 theoretical density. TSMC 7+/6nm are about 20% denser at 114 MT/mm^2. TSMC 5nm does 175 MT/mm^2, while Samsung 5LPE gets 126 MT/mm^2. See https://www.semiwiki.com/forum/content/8157-tsmc-s... . So TSMC 5nm is far ahead both in density and timescales.levizx - Thursday, May 9, 2019 - link
Only because TSMC uses 6T lib and Samsung uses 6.75T. 7LPP and 7FF+ has otherwise the same size.Maxiking - Thursday, May 9, 2019 - link
You literally have no clue you talk about.Intel 10 nm - 100M per mm2
TSMC "7"nm -66M per mm2
Go troll elsewhere.
Wilco1 - Thursday, May 9, 2019 - link
Really? Go and check the density of real 7nm chips on https://en.wikipedia.org/wiki/Transistor_countKirin 980 does 93 MT/mm^2. Now shut up and get back into your cave.
Maxiking - Friday, May 10, 2019 - link
Yes, really, you have no cluea what you are talking about. Every node has several versions of it, like high density, high performance, ultra high performance etc and their aim for different products, like x86 cpu, ARM cpus and so on. And because you are an uneducated internet figher, you just cross compare different versions of the nodes. So go back to your cave, you wiki fighter with no education, bye. Comparing ARM with x86, gg. You knowledge so stronk.Maxiking - Friday, May 10, 2019 - link
they* Excuse other typos, written on smartphone.Wilco1 - Friday, May 10, 2019 - link
Nobody cares how many special secret transistor libraries exist, if they aren't used in actual chips they don't count. Get back to me when Intel releases a chip that achieves their promised 100 MT/mm^2, until then you simply have no point.