The AMD Threadripper 2990WX 32-Core and 2950X 16-Core Review
by Dr. Ian Cutress on August 13, 2018 9:00 AM ESTCore to Core to Core: Design Trade Offs
AMD’s approach to these big processors is to take a small repeating unit, such as the 4-core complex or 8-core silicon die (which has two complexes on it), and put several on a package to get the required number of cores and threads. The upside of this is that there are a lot of replicated units, such as memory channels and PCIe lanes. The downside is how cores and memory have to talk to each other.
In a standard monolithic (single) silicon design, each core is on an internal interconnect to the memory controller and can hop out to main memory with a low latency. The speed between the cores and the memory controller is usually low, and the routing mechanism (a ring or a mesh) can determine bandwidth or latency or scalability, and the final performance is usually a trade-off.
In a multiple silicon design, where each die has access to specific memory locally but also has access to other memory via a jump, we then come across a non-uniform memory architecture, known in the business as a NUMA design. Performance can be limited by this abnormal memory delay, and software has to be ‘NUMA-aware’ in order to maximize both the latency and the bandwidth. The extra jumps between silicon and memory controllers also burn some power.
We saw this before with the first generation Threadripper: having two active silicon dies on the package meant that there was a hop if the data required was in the memory attached to the other silicon. With the second generation Threadripper, it gets a lot more complex.
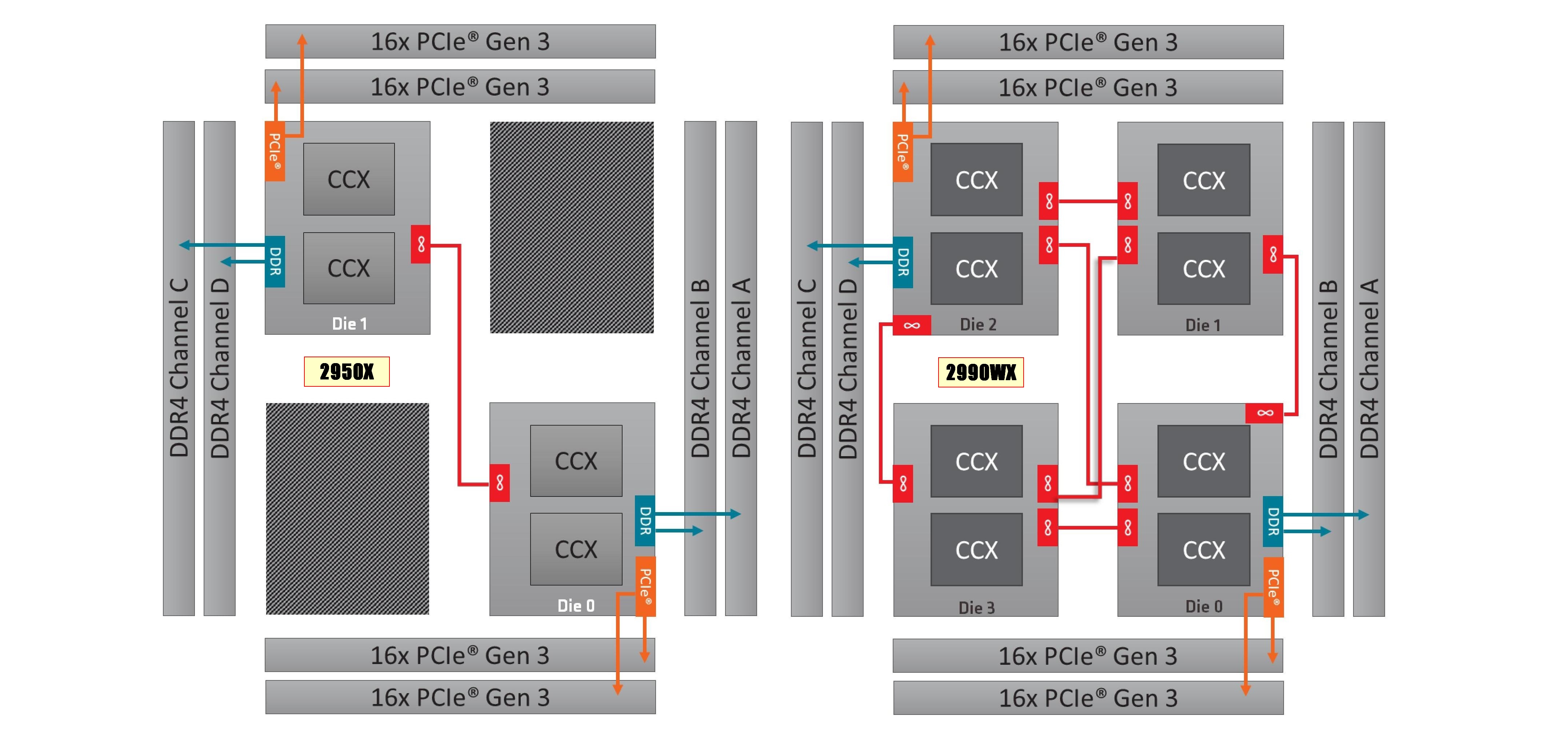
On the left is the 1950X/2950X design, with two active silicon dies. Each die has direct access to 32 PCIe lanes and two memory channels each, which when combined gives 60/64 PCIe lanes and four memory channels. The cores that have direct access to the memory/PCIe connected to the die are faster than going off-die.
For the 2990WX and 2970WX, the two ‘inactive’ dies are now enabled, but do not have extra access to memory or PCIe. For these cores, there is no ‘local’ memory or connectivity: every access to main memory requires an extra hop. There is also extra die-to-die interconnects using AMD’s Infinity Fabric (IF), which consumes power.
The reason that these extra cores do not have direct access is down to the platform: the TR4 platform for the Threadripper processors is set at quad-channel memory and 60 PCIe lanes. If the other two dies had their memory and PCIe enabled, it would require new motherboards and memory arrangements.
Users might ask, well can we not change it so each silicon die has one memory channel, and one set of 16 PCIe lanes? The answer is that yes, this change could occur. However the platform is somewhat locked in how the pins and traces are managed on the socket and motherboards. The firmware is expecting two memory channels per die, and also for electrical and power reasons, the current motherboards on the market are not set up in this way. This is going to be an important point when get into the performance in the review, so keep this in mind.
It is worth noting that this new second generation of Threadripper and AMD’s server platform, EPYC, are cousins. They are both built from the same package layout and socket, but EPYC has all the memory channels (eight) and all the PCIe lanes (128) enabled:
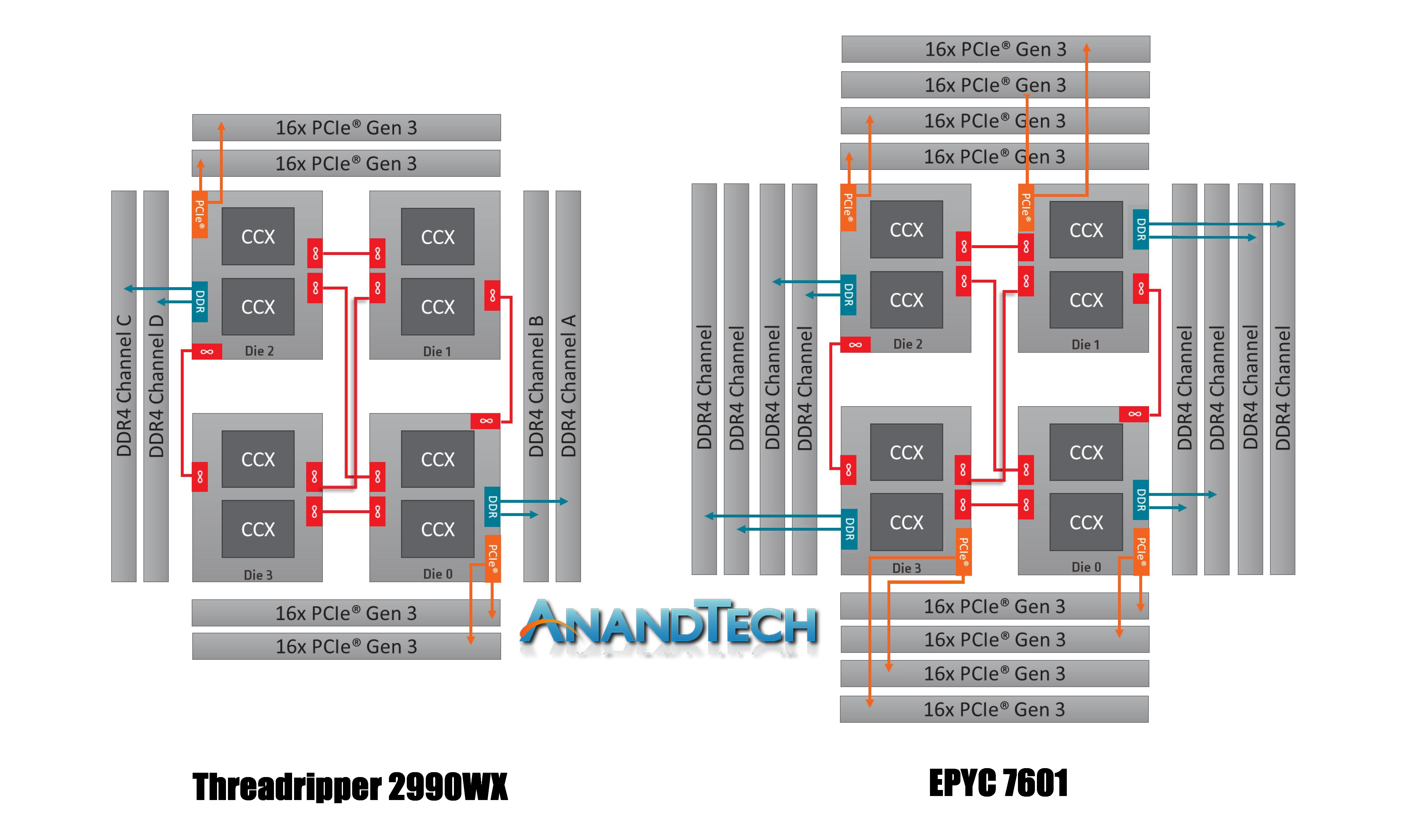
Where Threadripper 2 falls down on having some cores without direct access to memory, EPYC has direct memory available everywhere. This has the downside of requiring more power, but it offers a more homogenous core-to-core traffic layout.
Going back to Threadripper 2, it is important to understand how the chip is going to be loaded. We confirmed this with AMD, but for the most part the scheduler will load up the cores that are directly attached to memory first, before using the other cores. What happens is that each core has a priority weighting, based on performance, thermals, and power – the ones closest to memory get a higher priority, however as those fill up, the cores nearby get demoted due to thermal inefficiencies. This means that while the CPU will likely fill up the cores close to memory first, it will not be a simple case of filling up all of those cores first – the system may get to 12-14 cores loaded before going out to the two new bits of silicon.








171 Comments
View All Comments
Eastman - Tuesday, August 14, 2018 - link
Just a comment regarding studios and game developers. I work in the industry and 90% of these facilities do run with Xeon workstations and ECC memory. Either custom built or purchased from the likes of Dell or HP. So yes, there is a market place for workstations. No serious pro would do work on a mobile tablet or phone where there is a huge market growth. There is definitely a place for a single 32 core CPUs. But among say 100 workstations there might be a place for only 4-5 of the 2990WX. Those would serve particles/fluids dynamics simulation. Most of the workload would be sent to render farms sometimes offsite. Those render farms could use Epyc/Xeon chips. If I was a head of technology, I would seriously consider these CPUs for my artists workflow.ATC9001 - Wednesday, August 15, 2018 - link
Another big thing which people don't consider is...the true "price" of these systems is nearly neck and neck. Sure you can save a couple hundred with AMD CPU, but by the time you add in RAM, mobo, PSU, storage etc....you're talking a 5k+...Intel doesn't want AMD to go away (think anti-trust) but they are definitely stepping up efforts which is great for consumers!
LsRamAir - Thursday, August 16, 2018 - link
We've been patient! Looked at all the ads multiple times for support to. Please drop the rest of the knowledge, Sir! "Still writing" on the overclocking page is nibblin' at my patience and intrigue hemisphere.Relic74 - Wednesday, August 29, 2018 - link
Yes of course there is, I have one of the new 32 core systems and I use it with SmartOS. A VM management OS that could allow up to 8 game developers to use a single 32 Core workstation without a single bit of performance lost. That is as long as each VM has control over their own GPU. 4 Cores(most games dont new more than that in fact, no game needs more that), 32GB to 64GB of RAM (depending on server config) and an Nvidia 1080ti or higher, per VM. That is more than enough and would save the company thousands, in fact, that is exactly what most game developers use. Servers with 8 to 12 GPU's, dual CPUs, 32 to 64 cores, 512GB of RAM, standard config.You should watch Linus Tech Tips 12 node gaming system off of a single computer, it's the future and is amazing.
eek2121 - Saturday, August 18, 2018 - link
You are downplaying the gaming market. It's a multi-billion dollar industry. Nothing niche about it.HStewart - Monday, August 13, 2018 - link
I agree with you - so this mainly concerning "It's over, Intel is finished"Normally I don't care much to discuss AMD related threads - but when people already bad mouth Intel, it all fair game in my opinion.
But what is important and why I agree is that it not even close. Because the like it or not, PC Game industry which primary reason for desktop now is a minimal part of industry now - computers are mostly going to mobile - and just go into local BestBuy and you see why it not even close.
Plus as in a famous WW II saying, "The Sleeper has been Awaken". One is got to be blind, if you think "Intel is finished" I think the real reason that 10nm is not coming out, is that Intel wants to shut down AMD for once and for always. I see this coming in two areas - in the CPU area and also with GPU - I believe the i870xG is precursor to it - with AMD GPU being replace with Artic Sound.
But AMD does have a good side to this. That it keep Intel's prices down and Intel improving products.
ishould - Monday, August 13, 2018 - link
"I think the real reason that 10nm is not coming out, is that Intel wants to shut down AMD for once and for always." This is actually not true, Intel is having *major* yield issues with 10nm, hence 14nm being a 4-year-node (possibly 5 years if it slips from the expected Holiday 2019), and is a contributing factor for the decline of Intel/rise of AMD.HStewart - Monday, August 13, 2018 - link
I not stating that Intel didn't have yield issues - but there is 2 things that should be taking in account - and of course Intel only really knows1. (Intel has stated this) That all 10nm are not equal - and then Intel's 10nm is closer to competition's 7nm - and this is likely the reason why it taking long.
2. Intel realizes the process issues - and if you think they are not aware of competition in market - not just AMD but also ARM then one is a fool
ishould - Monday, August 13, 2018 - link
I agree they were probably being too ambitious with their scaling (2.4x) for 10nm. Rumor is that they've had to sacrifice some scaling to get better yields. EUV cannot come soon enough!MonkeyPaw - Monday, August 13, 2018 - link
I highly highly doubt that Intel would postpone 10nm just to “shut down AMD.” Intel has shareholders to look out for, and Intel needs 10nm out the door yesterday. Their 10nm struggles are real, and it is costing them investor confidence. No way would they wait around to win a pissing match with AMD while their stock value goes down.