The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTHPE DLBS, Caffe2: ResNet50 and ImageNet
On that relevant note, we'll take a look at HPE Deep Learning Benchmark Suite, part of their Deep Learning Cookbook. With a different angle than usual DL benchmark suites, its wide-ranging test-running modularity lends itself to quickly diagnose issues or bottlenecks on hardware platforms, which would be useful for an organization like HPE. Focused mostly on NVIDIA GPUs running computer vision CNNs, the DLBS setup is Volta-aware and is essentially outputs throughput and time metrics only, with some advanced monitoring and visualization tools that are only somewhat user-friendly.
For our purposes, it allows us to corroborate the NVIDIA Caffe2 Docker benchmark, so we train and inference with a ResNet50 model on ImageNet. But as the models and implementations are different, these throughput numbers shouldn't be directly compared to NVIDIA's Caffe2 Docker test.
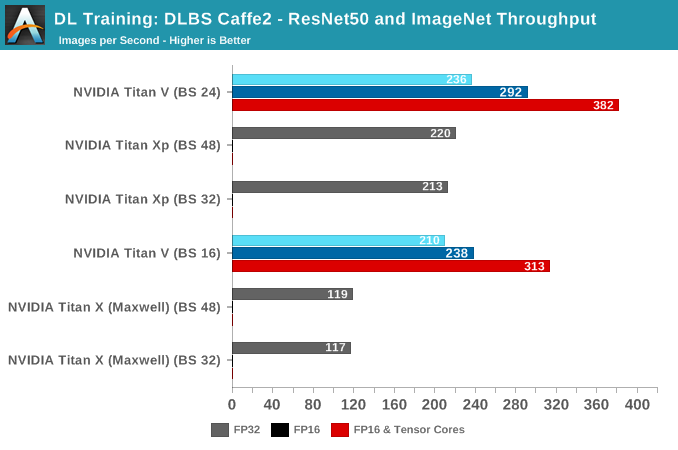
During the training benchmarking, certain batch sizes for Titan V refused to run, but generally, we see the same trend as before, with FP16 and tensor cores providing higher throughput.
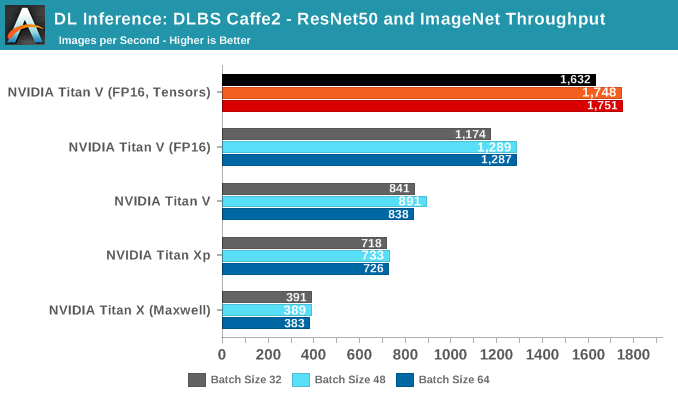
We see the same trends continue with inferencing. Unfortunately, the DLBS Caffe2 test does not seem to support INT8 inferencing.








65 Comments
View All Comments
mode_13h - Monday, July 9, 2018 - link
Nice. You gonna water-cool it?https://www.anandtech.com/show/12483/ekwb-releases...
wumpus - Thursday, July 12, 2018 - link
Don't forget double precision GFLOPS. Just because fp16 is the next new thing, nVidia didn't forget their existing CUDA customers and left out the doubles. I'm not sure what you would really benchmark, billion-point FFTs or something?mode_13h - Thursday, July 12, 2018 - link
Yeah, good point. Since GPUs don't support denormals, you run into the limitations of fp32 much more quickly than on many CPU implementations.I wonder if Nvidia will continue to combine tensor cores AND high-fp64 performance in the same GPUs, or if they'll bifurcate into deep-learning and HPC-centric variants.
byteLAKE - Friday, July 13, 2018 - link
Yes, indeed. Mixed precision does not come out of the box and requires development. We've done some research and actual projects in the space (described here https://medium.com/@marcrojek/how-artificial-intel... and results give a speedup.ballsystemlord - Monday, September 30, 2019 - link
Both myself and techpowerup get 14.90Tflops SP. Can you check your figures?https://www.techpowerup.com/gpu-specs/titan-v.c305...