The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTNVIDIA Caffe2 Docker: ResNet50 and ImageNet
Kernels and deep learning math operations may be useful, but in the end devices are trained with real datasets. Using the standard ILSVRC 2012 pictureset, we run the standard ResNet-50 training implementation that is included in NVIDIA's Caffe2 Docker image. The model trains on ImageNet and gives us some throughput data.
While there were separate switches for FP16 and tensor cores, running FP16 mode with tensors enabled and disabled resulted in identical results for the Titan V.
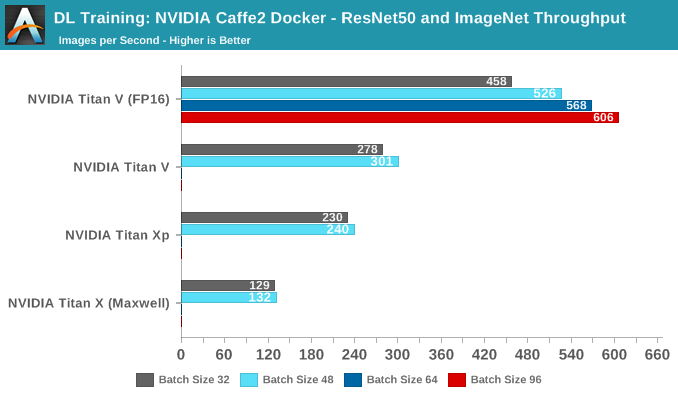
No score indicates card ran out of video memory
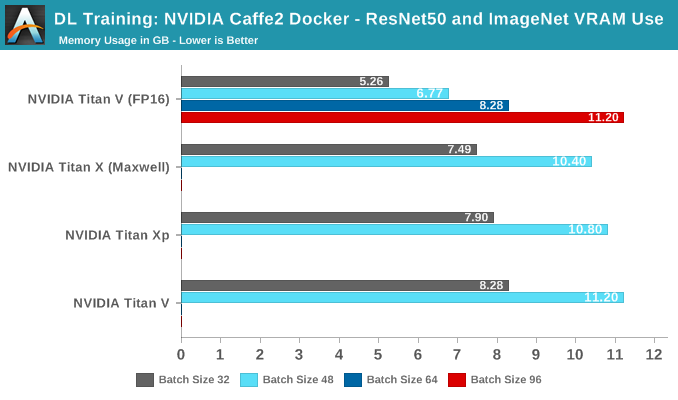
In terms of pure throughput, the Titan V takes the lead at all batch sizes. In fact, with tensors enabled it is able to go beyond 64 batches, as opposed to the other cards, even though they all have 12 GBs of VRAM. The reasoning is that FP16 consumes less video memory.
The issue with raw throughput metrics is that real-world performance for deep learning is never so simple. For one, many models might be optimized for throughput but sacrifice accuracy and/or training time. Peak or even sustained images trained per second may not be useful if the model takes an extended amount of time to converge. This is particularly relevant for Volta with FP16 storage and tensor cores, as there may be a number of necessary mitigations like loss scaling or single precision batch normalization, which wouldn't be directly accounted for in throughput metrics.
That being said, finding modern benchmarks that are Volta-aware, reasonably close to state-of-the-art, provide better metrics, go beyond CNNs for computer vision, and are accessible by non-researchers, has been a struggle. Throughput benchmarks are easier to validate and create, but in many situations they are better suited for identifying bottlenecks, platform differences, and optimization points.








65 Comments
View All Comments
SirCanealot - Tuesday, July 3, 2018 - link
No overclocking benchmarks. WAT. ¬_¬ (/s)Thanks for the awesome, interesting write up as usual!
Chaitanya - Tuesday, July 3, 2018 - link
This is more of an enterprise product for consumers so even if overclocking it enabled its something that targeted demographic is not going to use.Samus - Tuesday, July 3, 2018 - link
woooooooshMrSpadge - Tuesday, July 3, 2018 - link
He even put the "end sarcasm" tag (/s) to point out this was a joke.Ticotoo - Tuesday, July 3, 2018 - link
Where oh where are the MacOS drivers? It took 6 months to get the pascal Titan drivers.Hopefully soon
cwolf78 - Tuesday, July 3, 2018 - link
Nobody cares? I wouldn't be surprised if support gets dropped at some point. MacOS isn't exactly going anywhere.eek2121 - Tuesday, July 3, 2018 - link
Quite a few developers and professionals use Macs. Also college students. By manufacturer market share Apple probably has the biggest share, if not then definitely in the top 5.mode_13h - Tuesday, July 3, 2018 - link
I doubt it. Linux rules the cloud, and that's where all the real horsepower is at. Lately, anyone serious about deep learning is using Nvidia on Linux. It's only 2nd-teir players, like AMD and Intel, who really stand anything to gain by supporting niche platforms like Macs and maybe even Windows/Azure.Once upon a time, Apple actually made a rackmount OS X server. I think that line has long since died off.
Freakie - Wednesday, July 4, 2018 - link
Lol, those developers and professionals use their Macs to remote in to their compute servers, not to do any of the number crunching with.The idea of using a personal computer for anything except writing and debugging code is next to unheard of in an environment that requires the kind of power that these GPUs are meant to output. The machine they use for the actual computations are 99.5% of the time, a dedicated server used for nothing but to complete heavy compute tasks, usually with no graphical interface, just straight command-line.
philehidiot - Wednesday, July 4, 2018 - link
If it's just a command line why bother with a GPU like this? Surely integrated graphics would do?(Even though this is a joke, I'm not sure I can bear the humiliation of pressing "submit")