The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTNVIDIA Caffe2 Docker: ResNet50 and ImageNet
Kernels and deep learning math operations may be useful, but in the end devices are trained with real datasets. Using the standard ILSVRC 2012 pictureset, we run the standard ResNet-50 training implementation that is included in NVIDIA's Caffe2 Docker image. The model trains on ImageNet and gives us some throughput data.
While there were separate switches for FP16 and tensor cores, running FP16 mode with tensors enabled and disabled resulted in identical results for the Titan V.
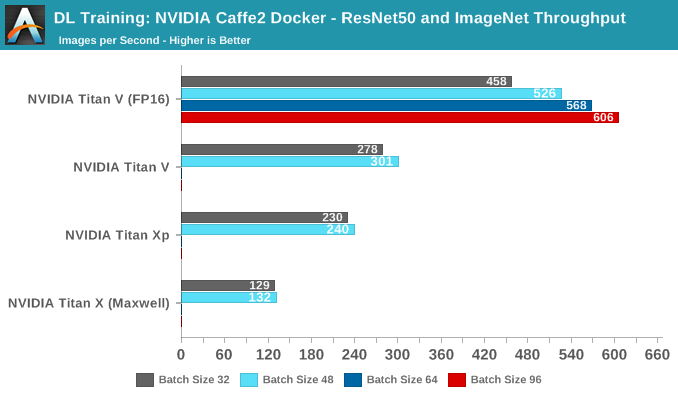
No score indicates card ran out of video memory
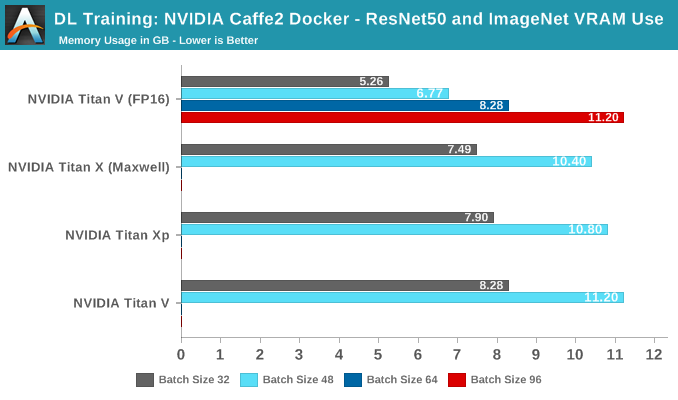
In terms of pure throughput, the Titan V takes the lead at all batch sizes. In fact, with tensors enabled it is able to go beyond 64 batches, as opposed to the other cards, even though they all have 12 GBs of VRAM. The reasoning is that FP16 consumes less video memory.
The issue with raw throughput metrics is that real-world performance for deep learning is never so simple. For one, many models might be optimized for throughput but sacrifice accuracy and/or training time. Peak or even sustained images trained per second may not be useful if the model takes an extended amount of time to converge. This is particularly relevant for Volta with FP16 storage and tensor cores, as there may be a number of necessary mitigations like loss scaling or single precision batch normalization, which wouldn't be directly accounted for in throughput metrics.
That being said, finding modern benchmarks that are Volta-aware, reasonably close to state-of-the-art, provide better metrics, go beyond CNNs for computer vision, and are accessible by non-researchers, has been a struggle. Throughput benchmarks are easier to validate and create, but in many situations they are better suited for identifying bottlenecks, platform differences, and optimization points.








65 Comments
View All Comments
mode_13h - Monday, July 9, 2018 - link
Nice. You gonna water-cool it?https://www.anandtech.com/show/12483/ekwb-releases...
wumpus - Thursday, July 12, 2018 - link
Don't forget double precision GFLOPS. Just because fp16 is the next new thing, nVidia didn't forget their existing CUDA customers and left out the doubles. I'm not sure what you would really benchmark, billion-point FFTs or something?mode_13h - Thursday, July 12, 2018 - link
Yeah, good point. Since GPUs don't support denormals, you run into the limitations of fp32 much more quickly than on many CPU implementations.I wonder if Nvidia will continue to combine tensor cores AND high-fp64 performance in the same GPUs, or if they'll bifurcate into deep-learning and HPC-centric variants.
byteLAKE - Friday, July 13, 2018 - link
Yes, indeed. Mixed precision does not come out of the box and requires development. We've done some research and actual projects in the space (described here https://medium.com/@marcrojek/how-artificial-intel... and results give a speedup.ballsystemlord - Monday, September 30, 2019 - link
Both myself and techpowerup get 14.90Tflops SP. Can you check your figures?https://www.techpowerup.com/gpu-specs/titan-v.c305...