The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTDeepBench Inference: GEMM
Shifting gears to inferencing, what DeepBench is simulating with graphics cards are more for their suitability in inference deployment servers, rather than edge devices. So of the inference kernels, none of the 'device' type ones are run.
Precision-wise, DeepBench inference tasks support INT8 on Volta and Pascal. More specifically, Baidu qualifies DeepBench GEMM and convolutions as INT8 mutiply with 32-bit accumulate.
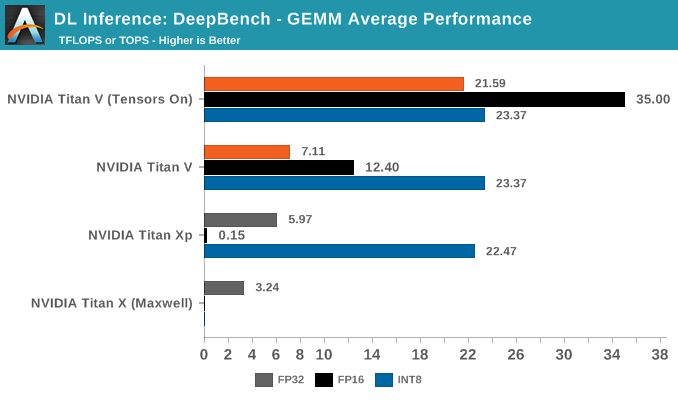
Both Titan V and Titan Xp feature quad rate INT8 performance, and DeepBench's INT8 inferencing implementation neatly falls under the DP4A vector dot product capability introduced by Pascal. The instruction is still supported under Volta, and shows up once again as IDP and IDP4A in the instruction set.
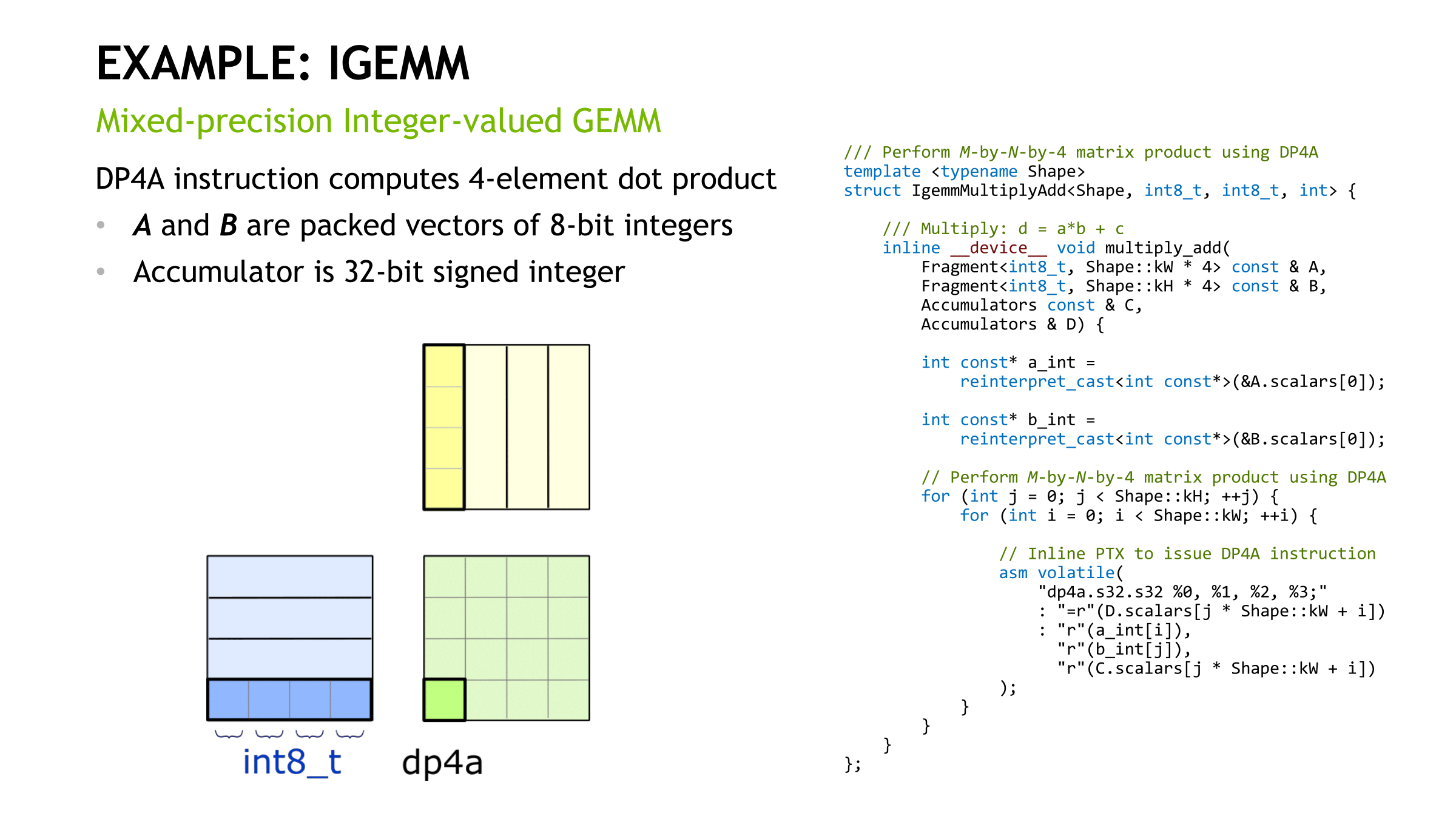
For IGEMM, as CUTLASS shows, DP4A is the bespoke operation. So we see 8-bit integer performance at a high level throughout, except in language modelling. Once again, the irregular dimensions don't lend itself to easy acceleration, if at all.
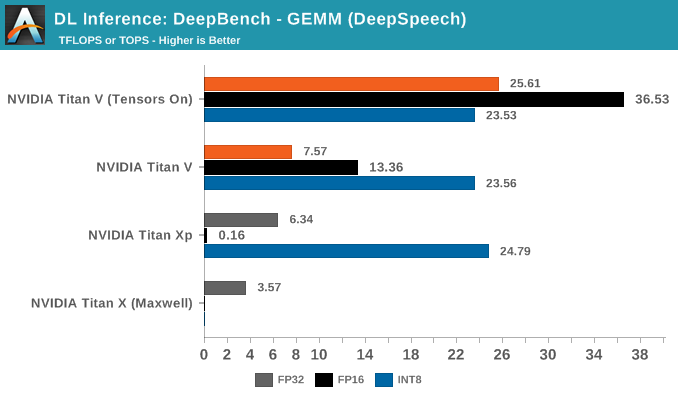
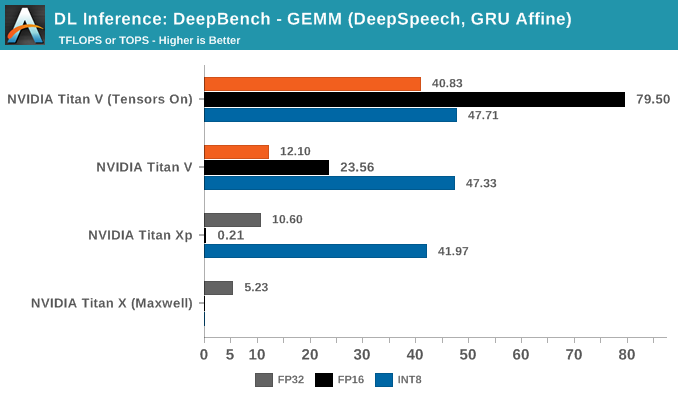
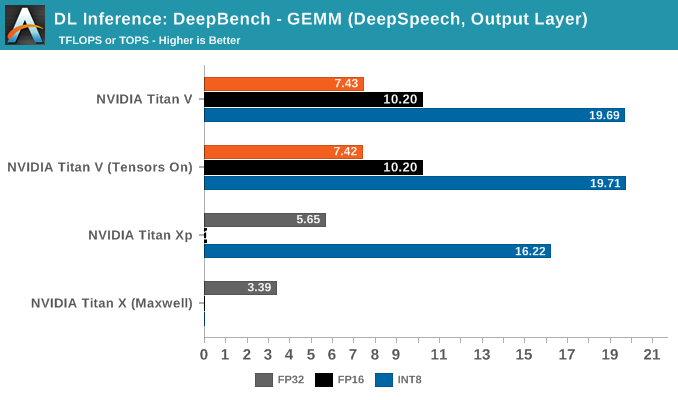
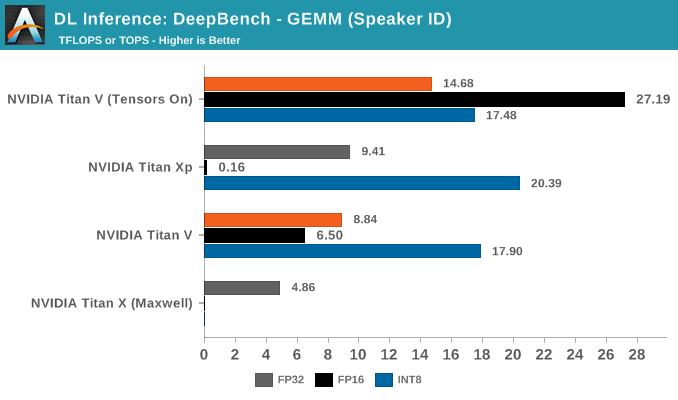
In fully-connected (or 'affine') layers, every node in that layer is connected to every node in the previous layer. What this means for a typical CNN is that the fully-connected layer is able combines all the extracted features to make a final prediction and classify the image. By the numbers, this also means large and regularly-proportioned matrices, which can equal large speedups as we see here.









65 Comments
View All Comments
mode_13h - Monday, July 9, 2018 - link
Nice. You gonna water-cool it?https://www.anandtech.com/show/12483/ekwb-releases...
wumpus - Thursday, July 12, 2018 - link
Don't forget double precision GFLOPS. Just because fp16 is the next new thing, nVidia didn't forget their existing CUDA customers and left out the doubles. I'm not sure what you would really benchmark, billion-point FFTs or something?mode_13h - Thursday, July 12, 2018 - link
Yeah, good point. Since GPUs don't support denormals, you run into the limitations of fp32 much more quickly than on many CPU implementations.I wonder if Nvidia will continue to combine tensor cores AND high-fp64 performance in the same GPUs, or if they'll bifurcate into deep-learning and HPC-centric variants.
byteLAKE - Friday, July 13, 2018 - link
Yes, indeed. Mixed precision does not come out of the box and requires development. We've done some research and actual projects in the space (described here https://medium.com/@marcrojek/how-artificial-intel... and results give a speedup.ballsystemlord - Monday, September 30, 2019 - link
Both myself and techpowerup get 14.90Tflops SP. Can you check your figures?https://www.techpowerup.com/gpu-specs/titan-v.c305...