The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTRevisiting Volta: How to Accelerate Deep Learning
While we’ve gone over Volta’s distinguishing characteristics several times now, the marquee addition of tensor cores somewhat overshadows all the other changes that supplement or outright support tensor core usage. For one, as we've already seen, it's tightly tied into the improved SIMT model with Volta's independent thread scheduling and collective groups.
Mixed Precision: Making FP16 Work for Deep Learning
Ultimately, Volta’s deep learning prowess is built on utilizing half precision (IEEE-754 FP16) rather than single precision (FP32) for deep learning training. First supported by cuDNN 3 and implemented in Tegra X1’s Maxwell cores, native half precision compute was fully introduced with Pascal as “Pseudo FP16”, where FP32 ALUs could instead process pairs of FP16 instructions for theoretically double FP16 throughput per clock. We've actually seen this in how tensor cores deal with matrix fragments in the register, as the two FP16 input matrices are gathered in 8 elements of FP16x2, or 16 FP16 elements.
In terms of FP32 versus FP16, because the single precision format ‘describes’ more data than half precision, operations are more computationally intensive and more memory storage/bandwidth is needed to house and transfer the data, in turn consuming more power. So the successful usage of lower precision in compute has been a poor man’s holy grail of sorts, targeting applications where higher precision is unnecessary.
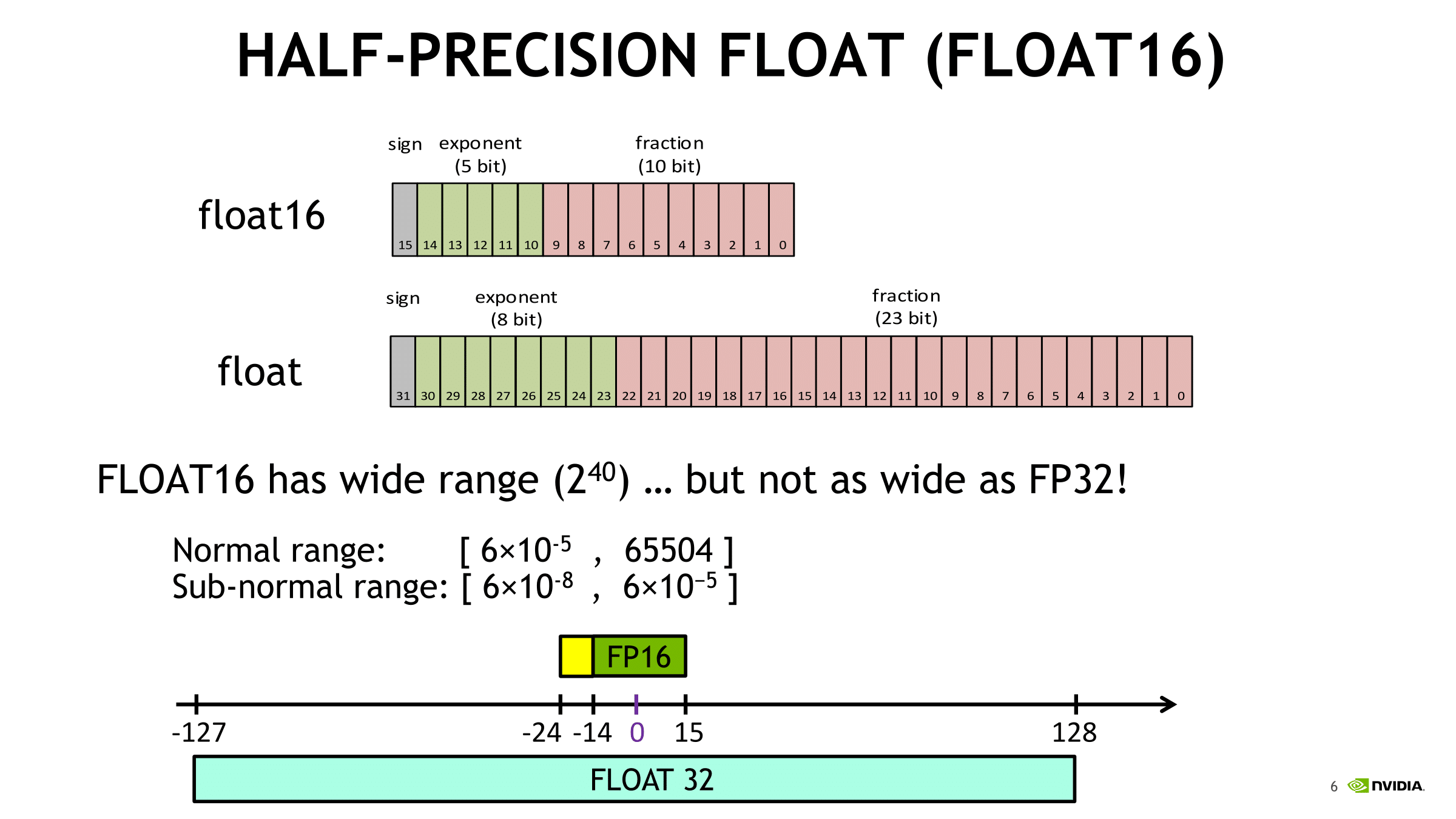
Aside from API/compiler/framework support, the perennial drawback for deep learning is the (unsurprising) loss of precision in using FP16 data types, where the training process would not be accurate enough and so the model cannot converge. Enter mixed precision.

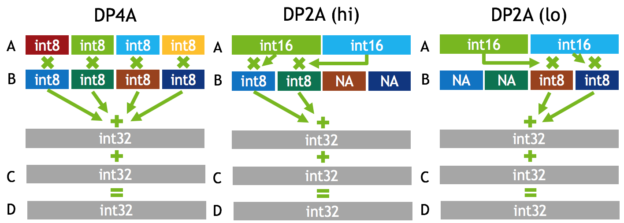
To be fair, NVIDIA has wheeled out the 'mixed precision' term before in very similar context, in discussing Pascal's fast FP16 (for GP100) and DP4A/DP2A integer dot product operations (for GP102, GP104, and GP106 GPUs). Back then, the focus was on inference, and very much like Titan V's 'deep learning TFLOPS,' Titan X (Pascal) launched with a "44 TOPS (new deep learning inferencing instruction)." The new instructions performed integer dot products on 4-element 8-bit vectors or 2-element 8-bit/16-bit vectors, resulting in a 32-bit integer product that could be accumulated with other 32-bit integers.
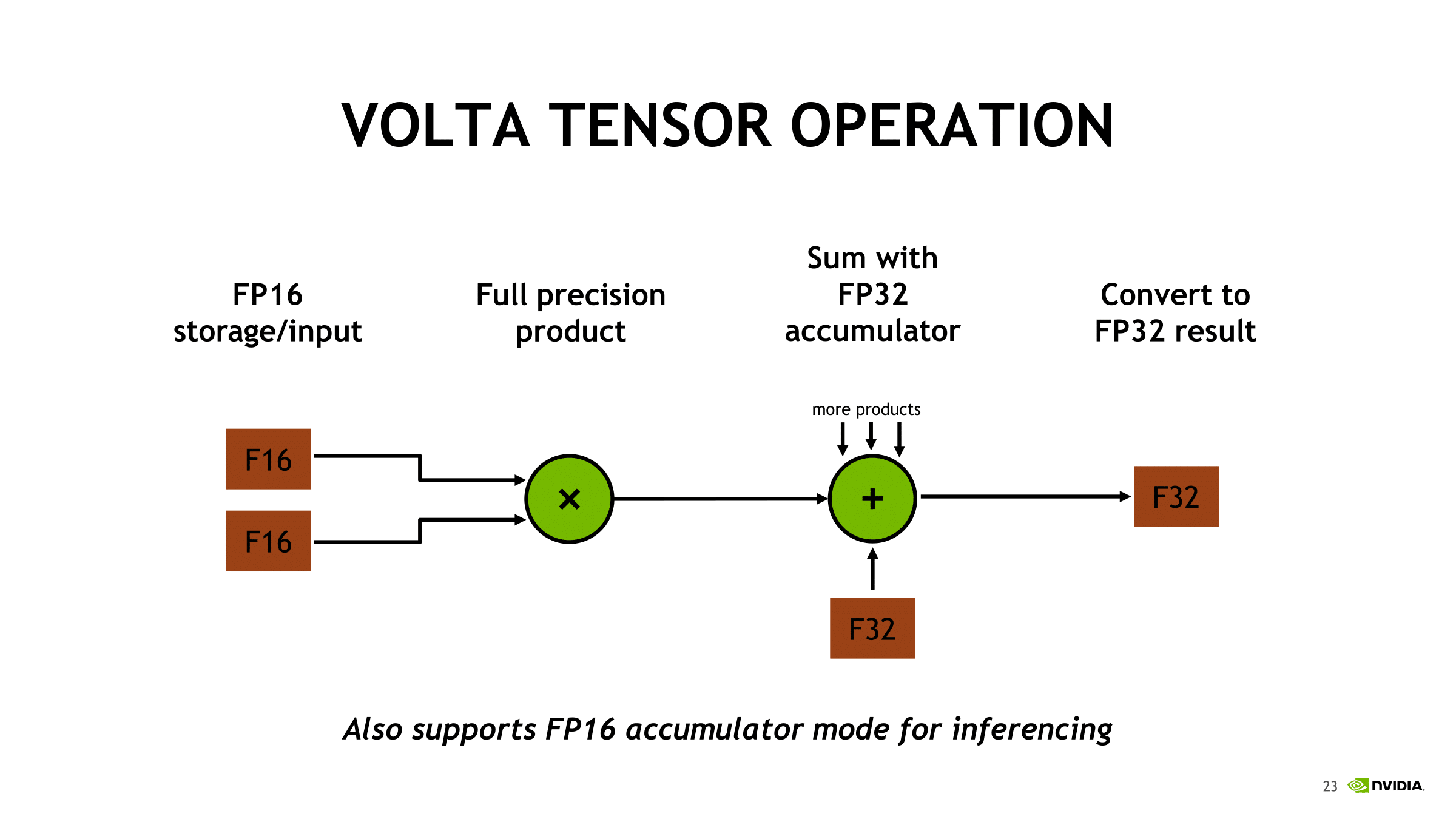
So for mixed precision in Volta, there are several more wrinkles. First is that important precision-sensitive data like master weights are stored as FP32. The second is tensor cores, where mixed precision training describes how two half precision input matrices are multiplied to get a single precision product, which is then accumulated into a single precision sum. NVIDIA has stated that the result is converted back to half precision before being written into memory, though how this happens is not exactly clear. For inferencing purposes though, the tensor core will instead accumulate the result into a half precision sum. Ultimately, when using half precision format, less data is needed in the registers and memory, which helps compensate for the data in very large matrices.
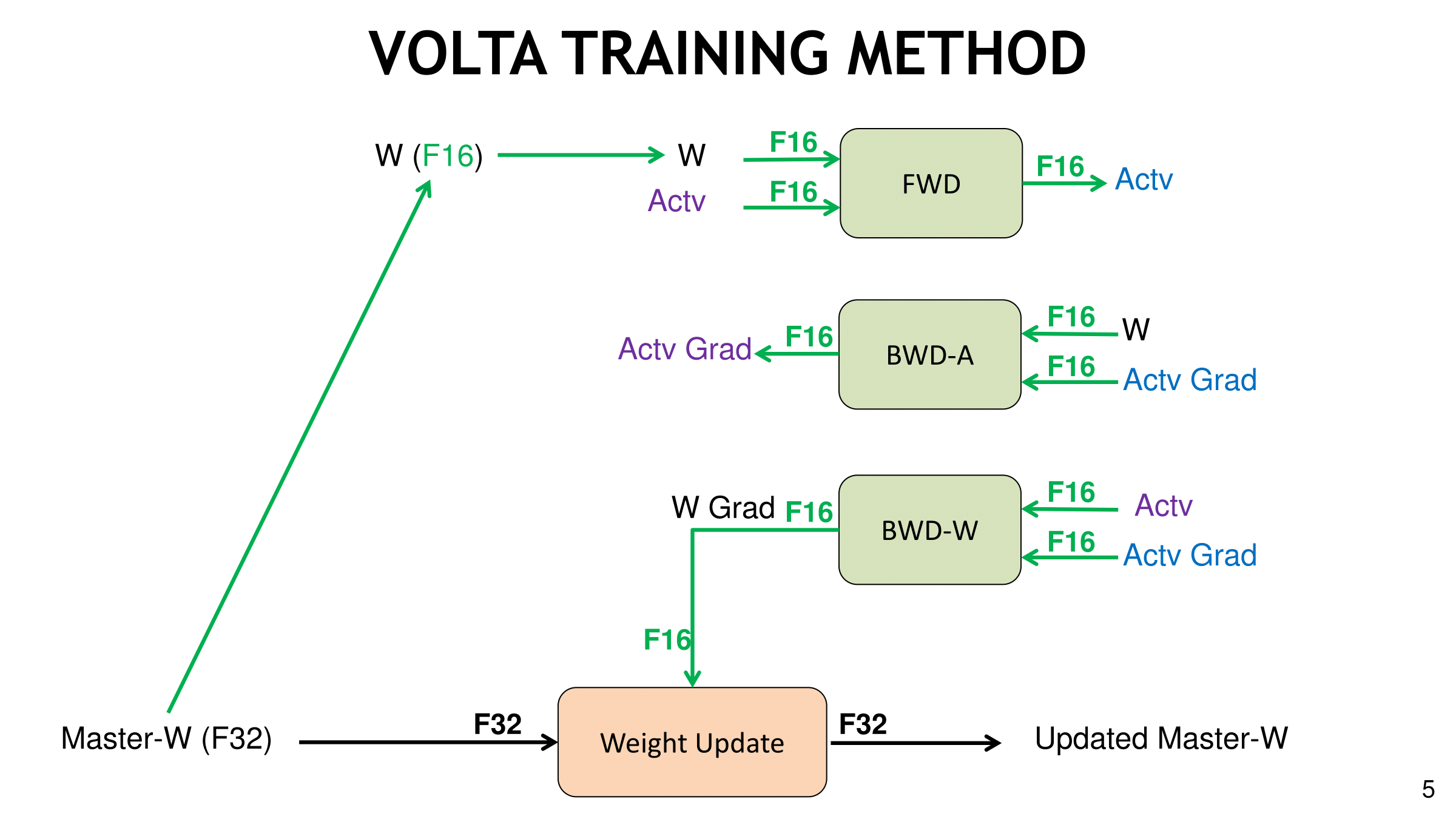
For a given training iteration, Volta mixed precision means the master weights are copied in single and half precision, and while that takes up more memory, NVIDIA believes the accuracy gains are worth it. The half precision weights are used in the ensuing computations, and when the master weights are ready to be updated with the resulting computation, the FP32 copy is used. At that last stage of an iteration, the computed weight updates are converted from FP16 to FP32 in order to update the FP32 master copy of weights, again for accuracy reasons.
Recalling that FP16 does not cover the same data space as FP32, a normalization method can resolve issues where an FP32 value is outside the representable range of FP16 and thus would be converted to a zero. For example, values of many activation gradients would fall outside of the range of FP16, but because these values are clustered together, multiplying the loss with a scaling factor moves most of the values in the range of FP16. The gradients are re-scaled to the original range before weight updates are done, maintaining the original precision.
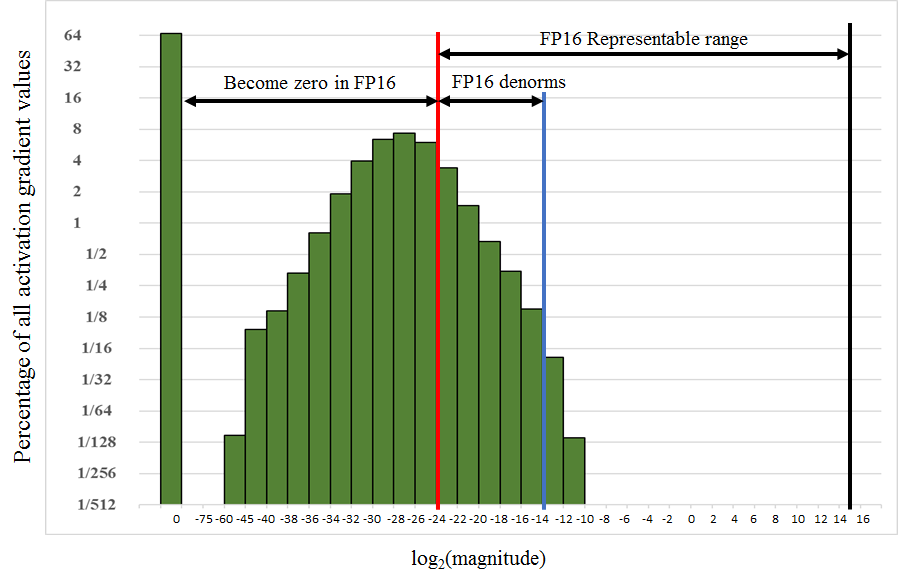
Not all math, neural networks, and layers work well with FP16 storage or math, so depending on the framework or type of neural net, FP16 will either be disabled by default or not recommended. In general, mixed precision with FP16 and tensor cores are best suited with convolution and RNN-heavy image processing and the like. For the most part, cuDNN handles a lot, and developers may only need a few pointers from NVIDIA's Mixed Precision guide. Meanwhile, cuBLAS and CUTLASS also include tensor core support. Altogether, especially with with the maturation of cuDNN it is hard to imagine tensor cores being succesful without it. Intrepid developers can continue trying to wrangle tensor cores directly in CUDA C++, PTX, and the like, though as we have seen tensor cores are, as far as generally programmable GPU blocks go, rather inflexible.
Volta and Pascal: Memory Improvements, SM Changes, and More
With mixed precision tensor cores, it would seem like the memory bandwidth issue was mitigated. As it turns out, not very much, despite the fact that Volta has received memory subsystem enhancements nearly across the board.
For one, Volta now has a 12 KiB L0 instruction cache, and while Pascal and others have had instruction buffers before, Volta's more efficient L0 is private to the sub-core SM partitions. And by that, it is private to the warp scheduler. This compensates for the larger instruction size of Volta's new ISA, and more likely than not, contributes to the framework supporting tensor core thoroughput, which uses the presumably beefy HMMA on a warp-based level. Instruction latency is also reduced from Pascal, notably with core FMAs down to 4 cycles from 6, which we previously confirmed.
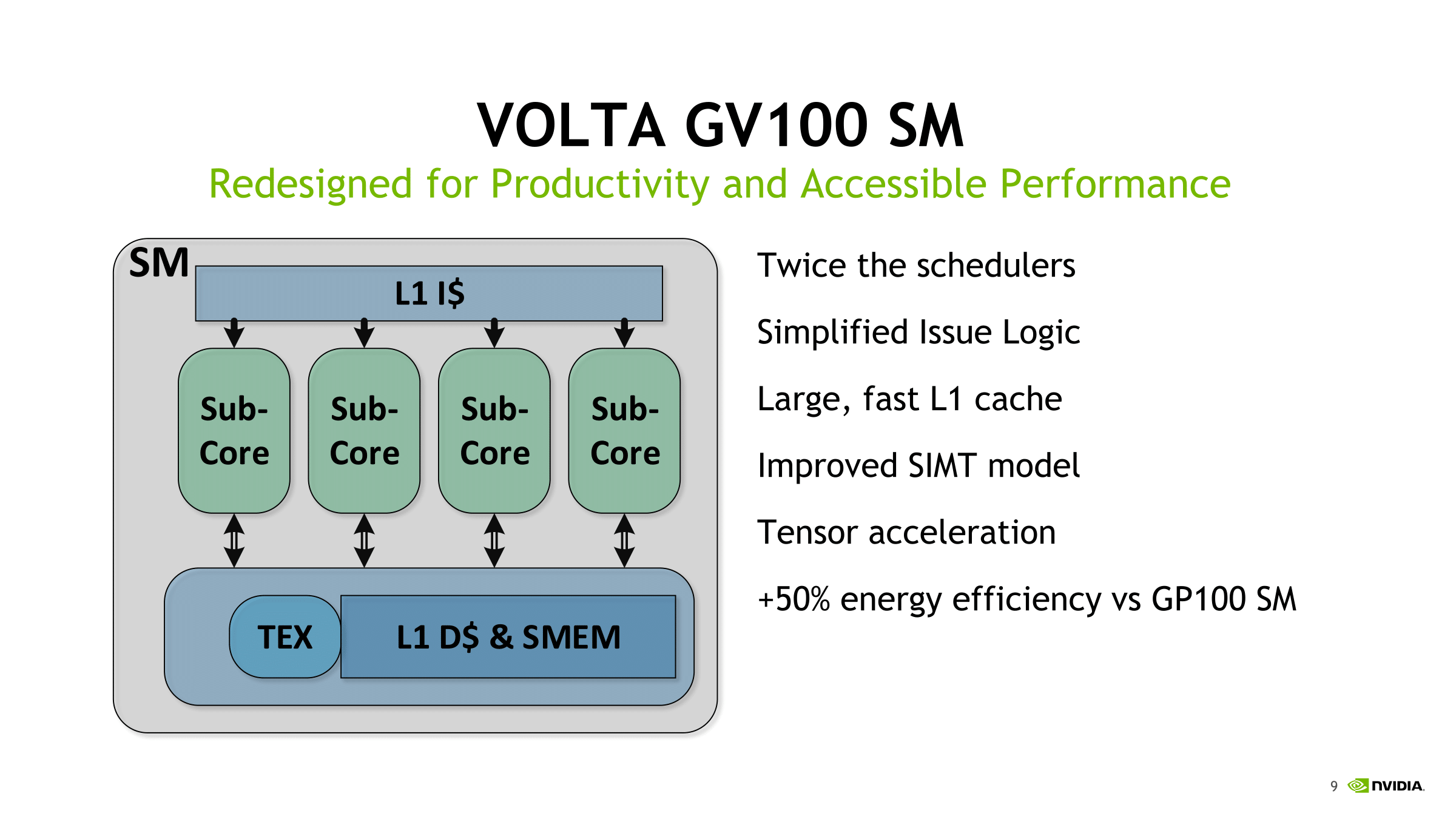
With the ratio of schedulers per SM increased, the loss of the second dispatch port seems to be a tradeoff in favor of independent sub-core with separate data paths and math dispatch unit; with simultaneous FP32/INT32 execution capability, it also opens the door to other lower precision/mixed precision models. Overall, the sub-core enhancements that we detailed earlier look to optimize the tensor core array.
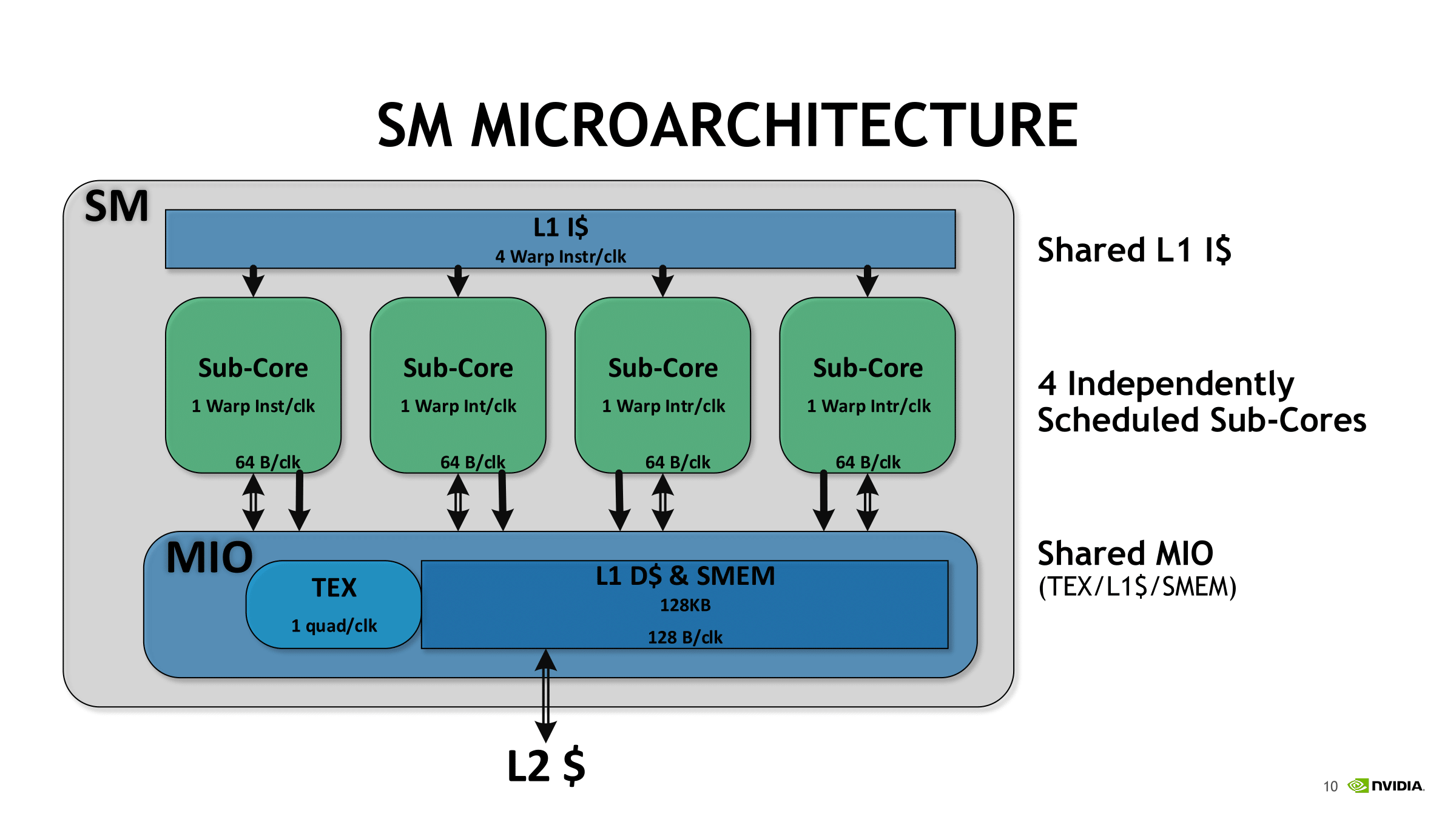
Another big change was merging the L1 cache and shared memory. While in the same block, the shared memory is configurable up to 96 KiB per SM. The HBM2 controller was also updated, and NVIDIA and others have noted 10 - 15% increase in efficiency.
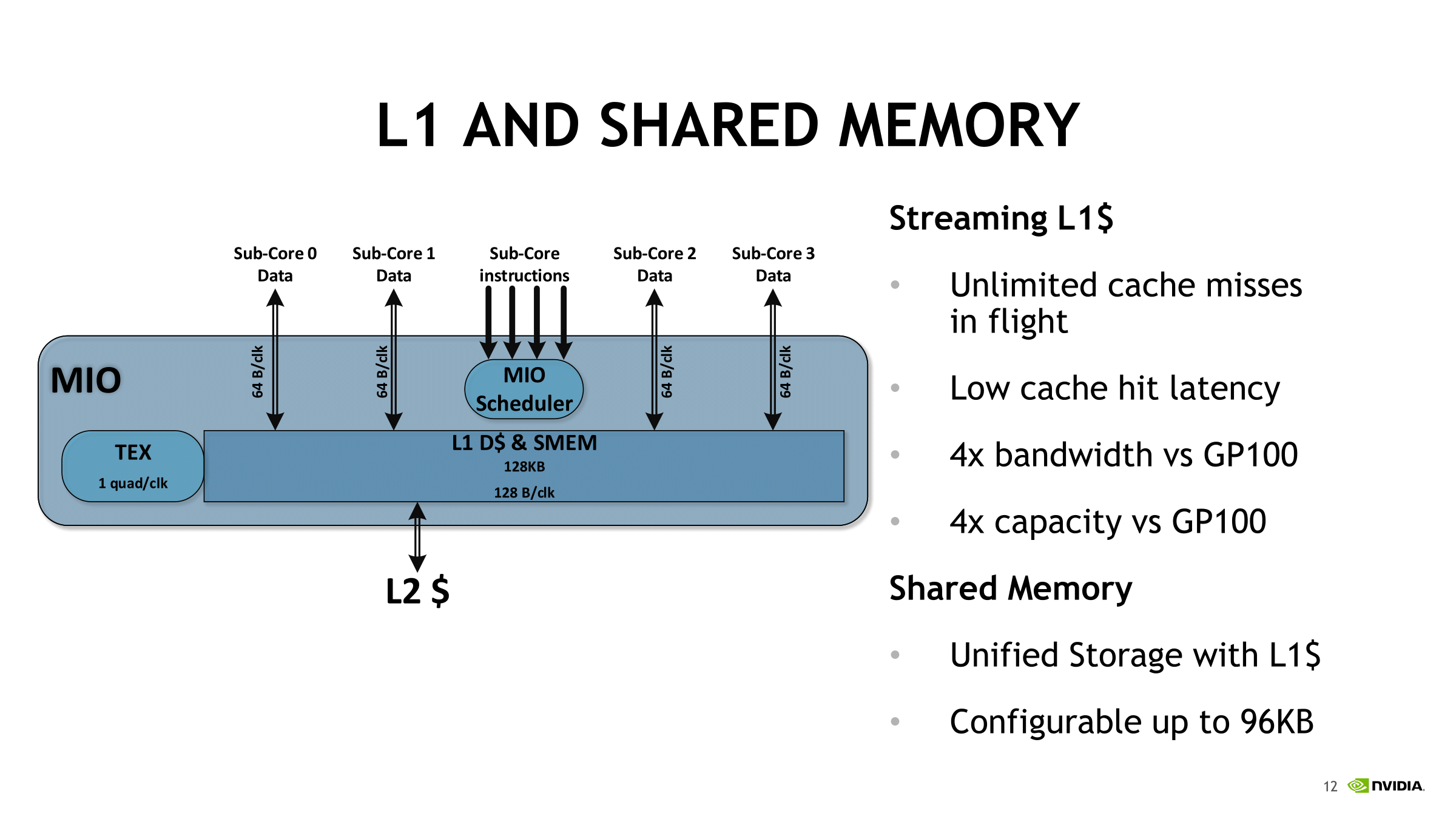
Summing up the SM, Volta looks to be building around a new style of independent partition that supports tensor cores, and one leaning far more on the compute side than on gaming.








65 Comments
View All Comments
krazyfrog - Saturday, July 7, 2018 - link
I don't think so.https://www.anandtech.com/show/12170/nvidia-titan-...
mode_13h - Saturday, July 7, 2018 - link
Yeah, I mean why else do you think they built the DGX Station?https://www.nvidia.com/en-us/data-center/dgx-stati...
They claim "AI", but I'm sure it was just an excuse they told their investors.
keg504 - Tuesday, July 3, 2018 - link
"With Volta, there has little detail of anything other than GV100 exists..." (First page)What is this sentence supposed to be saying?
Nate Oh - Tuesday, July 3, 2018 - link
Apologies, was a brain fart :)I've reworked the sentence, but the gist is: GV100 is the only Volta silicon that we know of (outside of an upcoming Drive iGPU)
junky77 - Tuesday, July 3, 2018 - link
ThanksAny thoughts about Google TPUv2 in comparison?
mode_13h - Tuesday, July 3, 2018 - link
TPUv2 is only 45 TFLOPS/chip. They initially grabbed a lot of attention with a 180 TFLOPS figure, but that turned out to be per-board.I'm not sure if they said how many TFLOPS/w.
SirPerro - Thursday, July 5, 2018 - link
TPUv3 was announced in May with 8x the performance of TPUv2 for a total of a 1 PF per podtuxRoller - Tuesday, July 3, 2018 - link
Since utilization is, apparently, an issue with these workloads, I'm interested in seeing how radically different architectures, such as tpu2+ and the just announced ibm ai accelerator (https://spectrum.ieee.org/tech-talk/semiconductors... which looks like a monster.MDD1963 - Wednesday, July 4, 2018 - link
4 ordinary people will buy this....by mistake, thinking it is a gamer. :)philehidiot - Wednesday, July 4, 2018 - link
"With DL researchers and academics successfully using CUDA to train neural network models faster, it was only a matter of time before NVIDIA released their cuDNN library of optimized deep learning primitives, of which there was ample precedent with the HPC-focused BLAS (Basic Linear Algebra Subroutines) and corresponding cuBLAS. So cuDNN abstracted away the need for researchers to create and optimize CUDA code for DL performance. As for AMD’s equivalent to cuDNN, MIOpen was only released last year under the ROCm umbrella, though currently is only publicly enabled in Caffe."Whatever drugs you're on that allow this to make any sense, I need some. Being a layman, I was hoping maybe 1/5th of this might make sense. I'm going back to the porn. </headache>