The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTDeepBench Training: Convolutions
Moving on to DeepBench's convolutions training workloads, we should see tensor cores significantly accelerate performance once again. Given that convolutional layers are essentially standard for image recognition and classification, convolutions are one of the biggest potential beneficiaries of tensor core acceleration.
Taking the average of all tests, we again see Volta's mixed precision (FP16 with tensor cores enabled) taking the lead. Unlike with GEMM, enabling tensors on FP32 convolutions results in a tangible performance penalty.
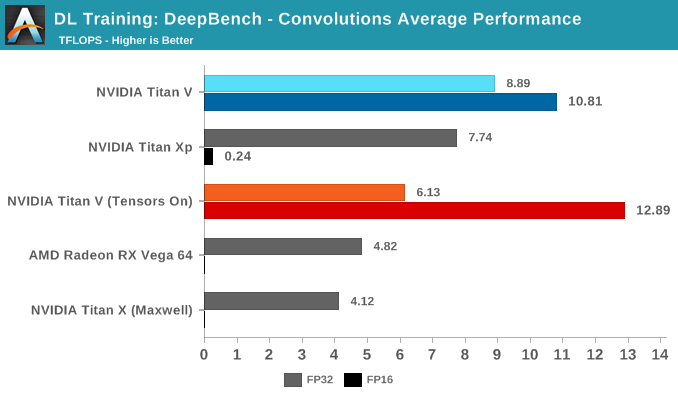
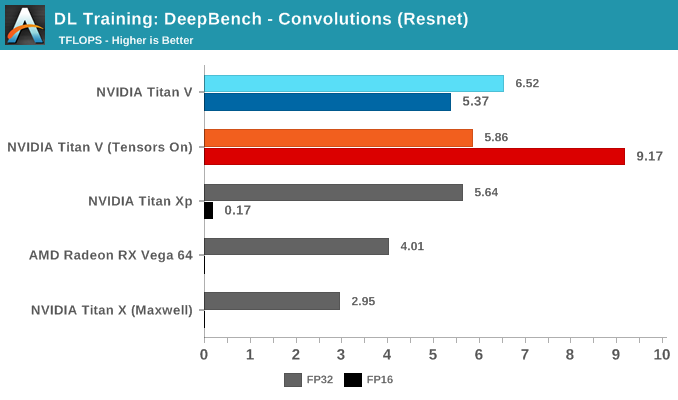
Breaking the tests out by application does not particularly clarify matters. It's only when we return to the DeepBench convolution kernels that we get a little more detail. Performance drops for both mixed precision modes when computations involve ill-matching tensor dimensions, and while standard precision modes follow a cuDNN-specified fastest forward algorithm, such as Winograd, the mixed precision modes are obliged to use implicit precomputed GEMM for all kernels.
To qualify for tensor core acceleration, both input and output channel dimensions must be a multiple of eight, and the input, filter, and output data-types must be half precision. Without going too deep into detail, the implementation of convolution acceleration with tensor cores requires tensors to be in a NHWC format (Number-Height-Width-Channel), but DeepBench, and most frameworks, expect NCHW formatted tensors. In this case, the input channels are not multiples of eight, but DeepBench does automatic padding to account for this.
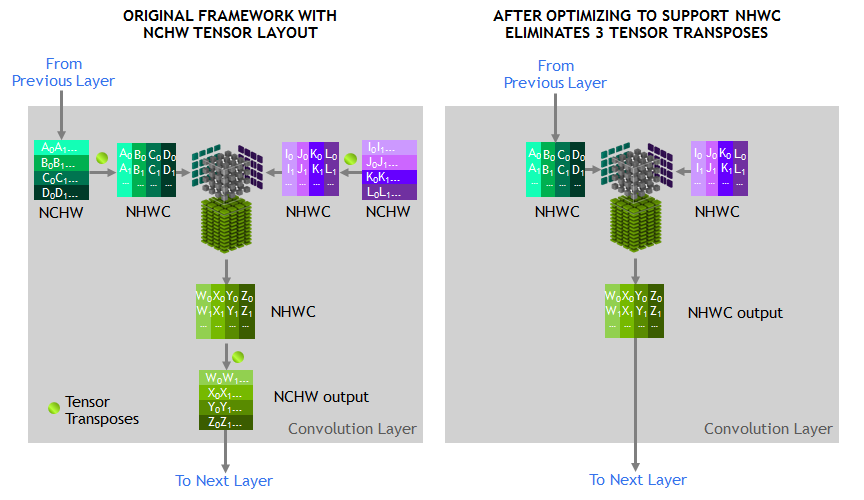
The other factor is that all these NCHW kernels would require transposition to NHWC, which NVIDIA has noted takes up appreciable runtime once convolutions are accelerated. This would affect both FP32 and FP16 mixed precision modes.
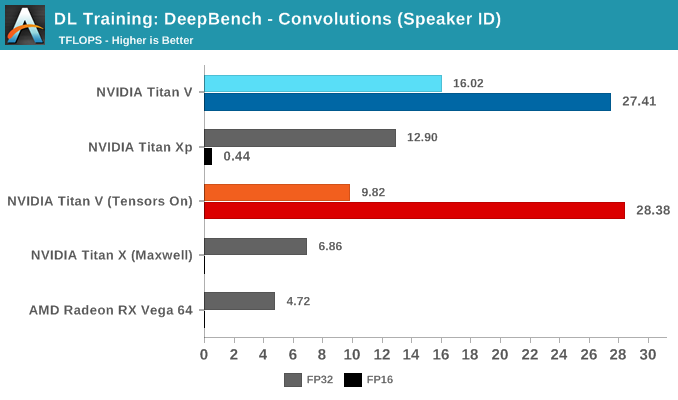
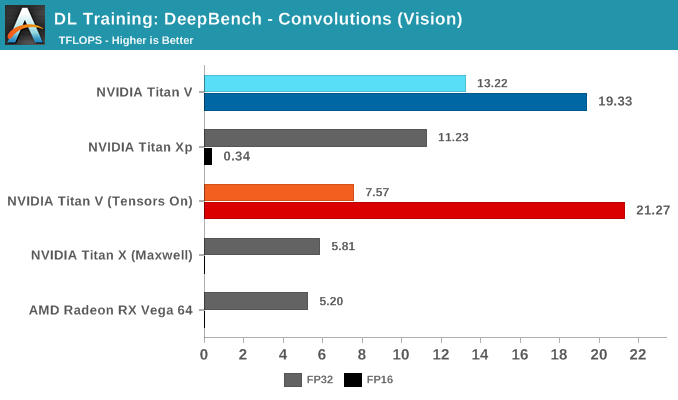
Convolutions still have to be adjusted correctly to benefit from tensor core acceleration. As DeepBench uses the NVIDIA-supplied libraries and makefiles, it's interesting that the standard behavior here would be to force tensor core use at all times.








65 Comments
View All Comments
Ryan Smith - Tuesday, July 3, 2018 - link
To clarify: SXM3 is the name of the socket used for the mezzanine form factor cards for servers. All Titan Vs are PCie.Drumsticks - Tuesday, July 3, 2018 - link
Nice review. Will anandtech be putting forth an effort to cover the ML hardware space in the future? AMD and Intel both seem to have plans here.The V100 and Titan V should have well over 100TF according to Nvidia in training and inference, if I remember correctly, but nothing I saw here got close in actuality. Were these benches not designed to hit those numbers, or are those numbers just too optimistic in most scenarios to occur?
Ryan Smith - Tuesday, July 3, 2018 - link
"The V100 and Titan V should have well over 100TF according to Nvidia in training and inference"The Titan V only has 75% of the memory bandwidth of the V100. So it's really hard to hit 100TF. Even in our Titan V preview where we ran a pure CUDA-based GEMM benchmark, we only hit 97 TFLOPS. Meanwhile real-world use cases are going to be lower still, as you can only achieve those kinds of high numbers in pure tensor core compute workloads.
https://www.anandtech.com/show/12170/nvidia-titan-...
Nate Oh - Tuesday, July 3, 2018 - link
To add on to Ryan's comment, 100+ TF is best-case (i.e. synthetic) performance based on peak FMA ops on individual matrix elements, which only comes about when everything perfectly qualifies for tensor core acceleration, no memory bottleneck by reusing tons of register data, etc.remedo - Tuesday, July 3, 2018 - link
Nate, I hope you could have included more TensorFlow/Keras specific benchmarks, given that the majority of deep learning researchers/developers are now using TensorFlow. Just compare the GitHub stats of TensorFlow vs. other frameworks. Therefore, I feel that this article missed some critical benchmarks in that regard. Still, this is a fascinating article, and thank you for your work. I understand that Anandtech is still new to deep learning benchmarks compared to your decades of experience in CPU/Gaming benchmark. If possible, please do a future update!Nate Oh - Tuesday, July 3, 2018 - link
Several TensorFlow benchmarks did not make the cut for today :) We were very much interested in using it, because amongst other things it offers global environmental variables to govern tensor core math, and integrates somewhat directly with TensorRT. However, we've been having issues finding and using one that does all the things we need it to do (and also offers different results than just pure throughput), and I've gone so far as trying to rebuild various models/implementations directly in Python (obviously to no avail, as I am ultimately not an ML developer).According to people smarter than me (i.e. Chintala, and I'm sure many others), if it's only utilizing standard cuDNN operations then frameworks should perform about the same; if there are significant differences, a la the inaugural version of Deep Learning Frameworks Comparison, it is because it is poorly optimized for TensorFlow or whatever given framework. From a purely GPU performance perspective, usage of different frameworks often comes down to framework-specific optimization, and not all reference implementations or benchmark suite tests do what we need it to do out-of-the-box (not to mention third-party implementations). Analyzing the level of TF optimization is developer-level work, and that's beyond the scope of the article. But once benchmark suites hit their stride, that will resolve that issue for us.
For Keras, I wasn't able to find anything that was reasonably usable by a non-developer, though I could've easily missed something (I'm aware of how it relates to TF, Theano, MXNet, etc). I'm sure that if we replaced PyTorch with Tensorflow implementations, we would get questions on 'Where's PyTorch?' :)
Not to say your point isn't valid, it is :) We're going to keep on looking into it, rest assured.
SirPerro - Thursday, July 5, 2018 - link
Keras has some nice examples in its github repo to be run with the tensorflow backend but for the sake of benchmarking it does not offer anything that it's not covered by the pure tensorflow examples, I guessBurntMyBacon - Tuesday, July 3, 2018 - link
I believe the GTX Titan with memory clock 6Gbps and memory bus width of 384 bits should have a memory bandwidth of 288GB/sec rather than the list 228GB/sec. Putting that aside, this is a nice review.Nate Oh - Tuesday, July 3, 2018 - link
Thanks, fixedJon Tseng - Tuesday, July 3, 2018 - link
Don't be silly. All we care about is whether it can run Crysis at 8K.