The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTDeepBench Training: GEMM and RNN
Opening up our DeepBench results are GEMM tests, which we've already seen as pure synthetic operations. Using kernels and GEMM operations used in certain deep learning applications (DeepSpeech, Speaker ID, and Language Modelling), performance here is a little more representative than running through pure matrix-matrix multiplications in cuBLAS.
To preface, the NVIDIA Titan Xp has crippled half precision, while the GeForce GTX Titan X (Maxwell) only supports single precision. According to Baidu, they test a FP32 with tensor cores mode for Volta, where 32-bit inputs undergo 16-bit multiplication and 32-bit accumulation. The specifics of this are somewhat unclear, but we've gone ahead and included those results. Otherwise, FP16 with tensor cores is the 'standard' Volta mixed precision.
The average results of all sub-tests seem unsurprising: enabling tensor cores results in large performance increases all around. Digging into the details reveals just how specific tensor core acceleration is to certain types of matrix-matrix multiplications.
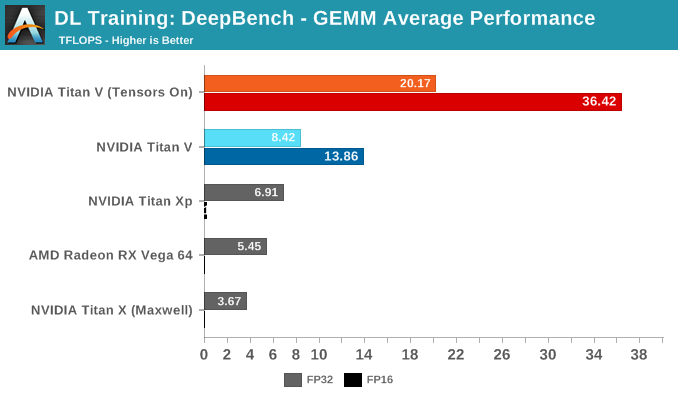
Splitting up the GEMM tests by DL application, we can start to see how tensor cores fare in ideal (and non-ideal) circumstances.
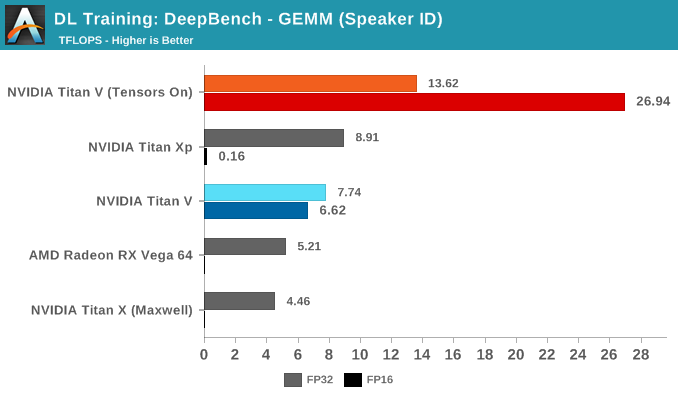
The Speaker ID GEMM workloads actually consist of only two kernels, where a difference of 10 microseconds means a difference of around 1 TFLOPS. The Titan Xp's higher performance is normal variance.
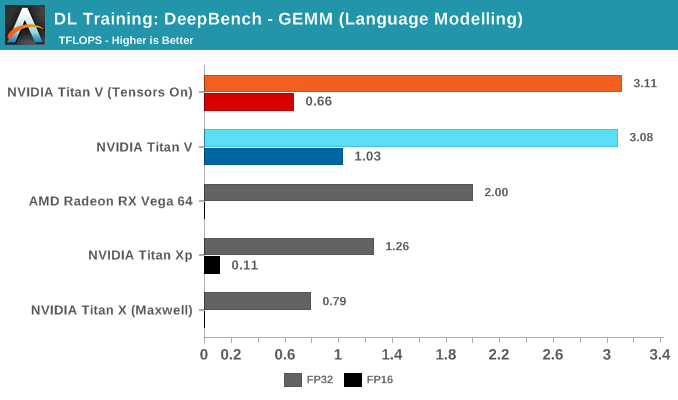
Looking into the Language Modelling kernels explains the poor performance of tensor cores. The sizes of those kernel matrices are m = 512 or 1024, n = 8 or 16, and k = 500000, and the small size of n compared to the very large k is notable. While each number is technically divisible by 8 – one of the basic requirements to qualify for tensor core acceleration – the shape of these matrices isn't a neat fit with the supported basic WMMA shapes: 16x16x16, 32x8x16, and 8x32x16. Nor does it go well with 8x8x8, if we're assuming that tensor cores truly operate on an independent 8x8x8 level.

So tensor cores are being pulled into action on very lopsided matrices that can't be broken up easily as n = 8 or 16, at least, not without performance penalties.
Meanwhile, the tensor cores have runaway performance on DeepSpeech kernels:
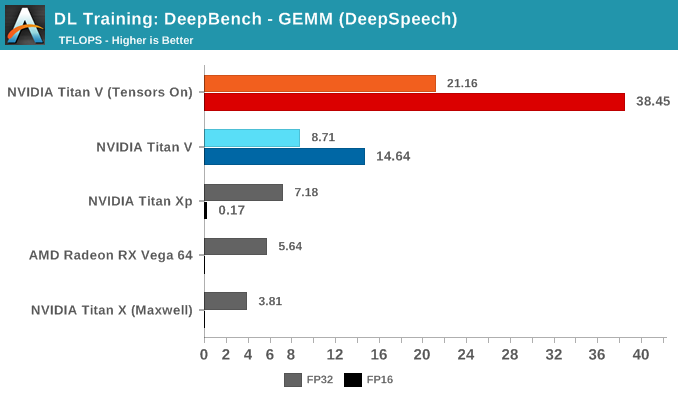
As an average, it turns out to be an impressive number of TFLOPs. Granularly, the same impact of wrong-proportioned matrices is occuring. When matrices fit the tensor core proportions, performance can jump to more than 90 TFLOPS. When they don't, and the right transpositions are not in play, then performances can drop to below 1 TFLOPS.
For the DeepBench RNN kernels, there is no drastic divergence between RNN type. But within in each RNN type, the same patterns can be seen if judging kernel-by-kernel.
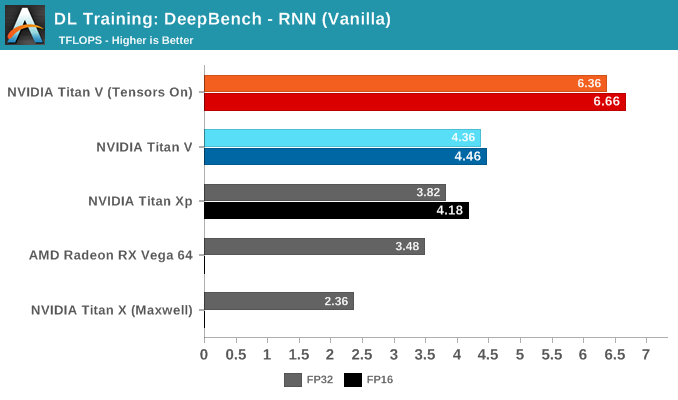
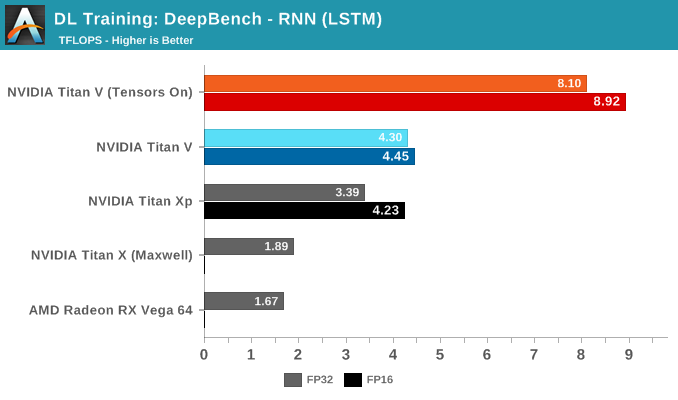
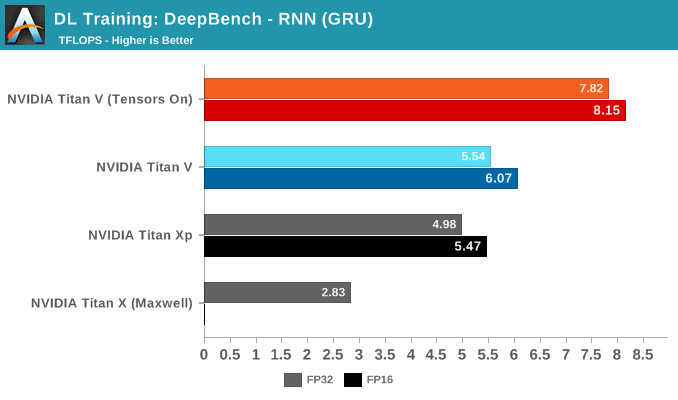
What is interesting is how close the Titan Xp can come to non-tensor core accelerated Titan V performance. We know that the Titan Xp's superior clockspeeds are doing it a favor here, but also one of Titan V's big advantages – HBM2 – is partially mitigated by its 3 controller configuration. Bandwidth-to-bandwidth, the Titan V only has theoretically around 100GB/s more, but at the same amount of VRAM; and while Volta's HBM controller efficiency has improved over Pascal P100, Titan Xp presumably features NVIDIA's 2nd generation GDDR5X controller.








65 Comments
View All Comments
Ryan Smith - Tuesday, July 3, 2018 - link
To clarify: SXM3 is the name of the socket used for the mezzanine form factor cards for servers. All Titan Vs are PCie.Drumsticks - Tuesday, July 3, 2018 - link
Nice review. Will anandtech be putting forth an effort to cover the ML hardware space in the future? AMD and Intel both seem to have plans here.The V100 and Titan V should have well over 100TF according to Nvidia in training and inference, if I remember correctly, but nothing I saw here got close in actuality. Were these benches not designed to hit those numbers, or are those numbers just too optimistic in most scenarios to occur?
Ryan Smith - Tuesday, July 3, 2018 - link
"The V100 and Titan V should have well over 100TF according to Nvidia in training and inference"The Titan V only has 75% of the memory bandwidth of the V100. So it's really hard to hit 100TF. Even in our Titan V preview where we ran a pure CUDA-based GEMM benchmark, we only hit 97 TFLOPS. Meanwhile real-world use cases are going to be lower still, as you can only achieve those kinds of high numbers in pure tensor core compute workloads.
https://www.anandtech.com/show/12170/nvidia-titan-...
Nate Oh - Tuesday, July 3, 2018 - link
To add on to Ryan's comment, 100+ TF is best-case (i.e. synthetic) performance based on peak FMA ops on individual matrix elements, which only comes about when everything perfectly qualifies for tensor core acceleration, no memory bottleneck by reusing tons of register data, etc.remedo - Tuesday, July 3, 2018 - link
Nate, I hope you could have included more TensorFlow/Keras specific benchmarks, given that the majority of deep learning researchers/developers are now using TensorFlow. Just compare the GitHub stats of TensorFlow vs. other frameworks. Therefore, I feel that this article missed some critical benchmarks in that regard. Still, this is a fascinating article, and thank you for your work. I understand that Anandtech is still new to deep learning benchmarks compared to your decades of experience in CPU/Gaming benchmark. If possible, please do a future update!Nate Oh - Tuesday, July 3, 2018 - link
Several TensorFlow benchmarks did not make the cut for today :) We were very much interested in using it, because amongst other things it offers global environmental variables to govern tensor core math, and integrates somewhat directly with TensorRT. However, we've been having issues finding and using one that does all the things we need it to do (and also offers different results than just pure throughput), and I've gone so far as trying to rebuild various models/implementations directly in Python (obviously to no avail, as I am ultimately not an ML developer).According to people smarter than me (i.e. Chintala, and I'm sure many others), if it's only utilizing standard cuDNN operations then frameworks should perform about the same; if there are significant differences, a la the inaugural version of Deep Learning Frameworks Comparison, it is because it is poorly optimized for TensorFlow or whatever given framework. From a purely GPU performance perspective, usage of different frameworks often comes down to framework-specific optimization, and not all reference implementations or benchmark suite tests do what we need it to do out-of-the-box (not to mention third-party implementations). Analyzing the level of TF optimization is developer-level work, and that's beyond the scope of the article. But once benchmark suites hit their stride, that will resolve that issue for us.
For Keras, I wasn't able to find anything that was reasonably usable by a non-developer, though I could've easily missed something (I'm aware of how it relates to TF, Theano, MXNet, etc). I'm sure that if we replaced PyTorch with Tensorflow implementations, we would get questions on 'Where's PyTorch?' :)
Not to say your point isn't valid, it is :) We're going to keep on looking into it, rest assured.
SirPerro - Thursday, July 5, 2018 - link
Keras has some nice examples in its github repo to be run with the tensorflow backend but for the sake of benchmarking it does not offer anything that it's not covered by the pure tensorflow examples, I guessBurntMyBacon - Tuesday, July 3, 2018 - link
I believe the GTX Titan with memory clock 6Gbps and memory bus width of 384 bits should have a memory bandwidth of 288GB/sec rather than the list 228GB/sec. Putting that aside, this is a nice review.Nate Oh - Tuesday, July 3, 2018 - link
Thanks, fixedJon Tseng - Tuesday, July 3, 2018 - link
Don't be silly. All we care about is whether it can run Crysis at 8K.