The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTDeepBench Training: Convolutions
Moving on to DeepBench's convolutions training workloads, we should see tensor cores significantly accelerate performance once again. Given that convolutional layers are essentially standard for image recognition and classification, convolutions are one of the biggest potential beneficiaries of tensor core acceleration.
Taking the average of all tests, we again see Volta's mixed precision (FP16 with tensor cores enabled) taking the lead. Unlike with GEMM, enabling tensors on FP32 convolutions results in a tangible performance penalty.
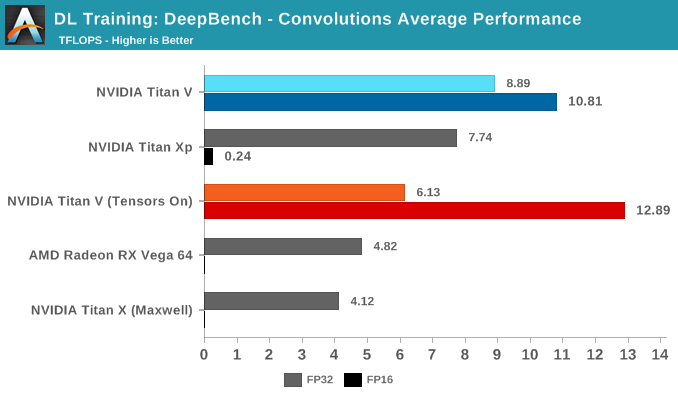
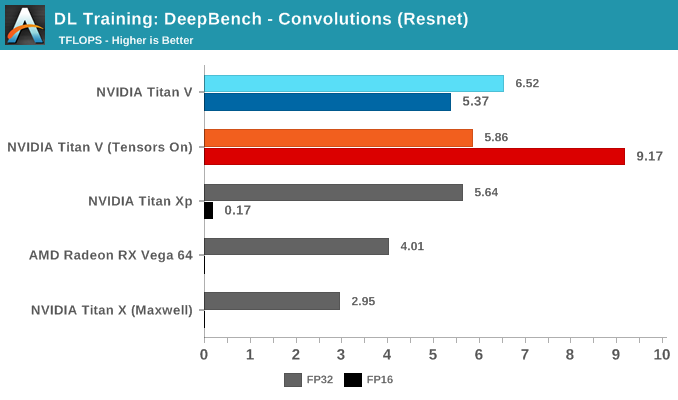
Breaking the tests out by application does not particularly clarify matters. It's only when we return to the DeepBench convolution kernels that we get a little more detail. Performance drops for both mixed precision modes when computations involve ill-matching tensor dimensions, and while standard precision modes follow a cuDNN-specified fastest forward algorithm, such as Winograd, the mixed precision modes are obliged to use implicit precomputed GEMM for all kernels.
To qualify for tensor core acceleration, both input and output channel dimensions must be a multiple of eight, and the input, filter, and output data-types must be half precision. Without going too deep into detail, the implementation of convolution acceleration with tensor cores requires tensors to be in a NHWC format (Number-Height-Width-Channel), but DeepBench, and most frameworks, expect NCHW formatted tensors. In this case, the input channels are not multiples of eight, but DeepBench does automatic padding to account for this.
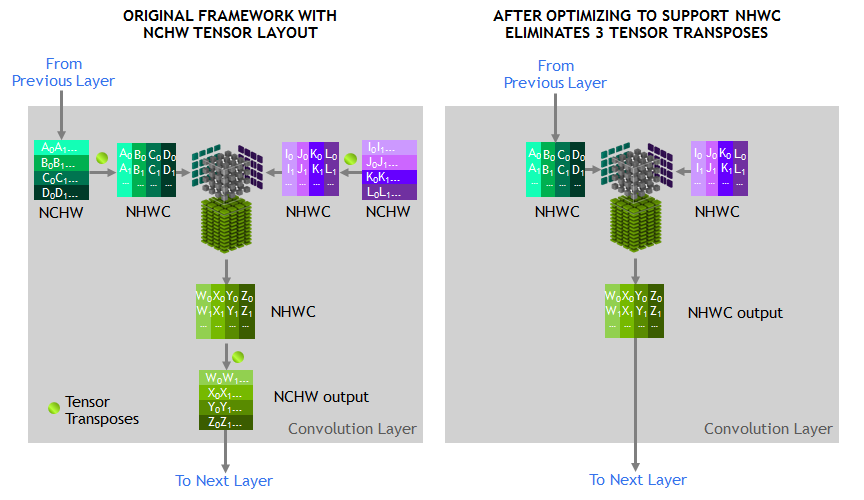
The other factor is that all these NCHW kernels would require transposition to NHWC, which NVIDIA has noted takes up appreciable runtime once convolutions are accelerated. This would affect both FP32 and FP16 mixed precision modes.
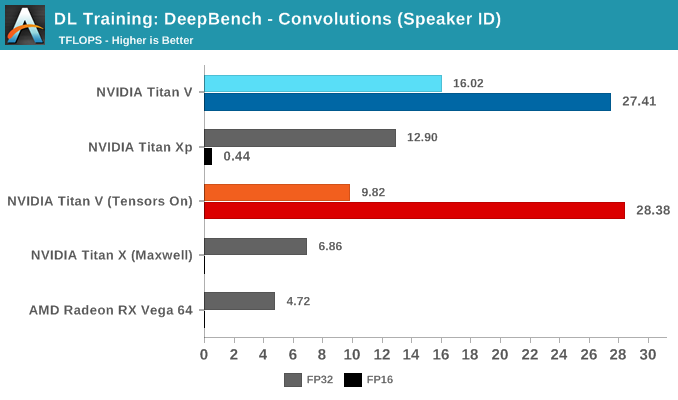
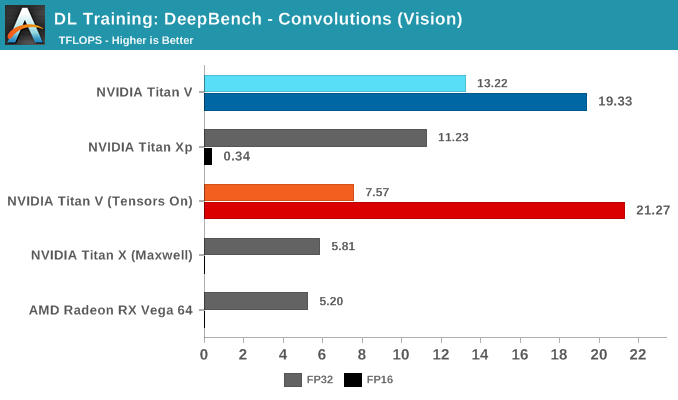
Convolutions still have to be adjusted correctly to benefit from tensor core acceleration. As DeepBench uses the NVIDIA-supplied libraries and makefiles, it's interesting that the standard behavior here would be to force tensor core use at all times.








65 Comments
View All Comments
mode_13h - Monday, July 9, 2018 - link
Nice. You gonna water-cool it?https://www.anandtech.com/show/12483/ekwb-releases...
wumpus - Thursday, July 12, 2018 - link
Don't forget double precision GFLOPS. Just because fp16 is the next new thing, nVidia didn't forget their existing CUDA customers and left out the doubles. I'm not sure what you would really benchmark, billion-point FFTs or something?mode_13h - Thursday, July 12, 2018 - link
Yeah, good point. Since GPUs don't support denormals, you run into the limitations of fp32 much more quickly than on many CPU implementations.I wonder if Nvidia will continue to combine tensor cores AND high-fp64 performance in the same GPUs, or if they'll bifurcate into deep-learning and HPC-centric variants.
byteLAKE - Friday, July 13, 2018 - link
Yes, indeed. Mixed precision does not come out of the box and requires development. We've done some research and actual projects in the space (described here https://medium.com/@marcrojek/how-artificial-intel... and results give a speedup.ballsystemlord - Monday, September 30, 2019 - link
Both myself and techpowerup get 14.90Tflops SP. Can you check your figures?https://www.techpowerup.com/gpu-specs/titan-v.c305...