Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Apache Spark 2.1 Benchmarking
Apache Spark is the poster child of Big Data processing. Speeding up Big Data applications is the top priority project at the university lab I work for (Sizing Servers Lab of the University College of West-Flanders), so we produced a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large amount of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
In previous articles, we tested with Spark 1.5 in standalone mode (non-clustered). That worked out well enough, but we saw diminishing returns as core counts went up. In hindsight, just dumping 300 GB of compressed data in one JVM was not optimal for 30+ core systems. The high core counts of the Xeon 8176 and EPYC 7601 caused serious performance issues when we first continued to test this way. The 64 core EPYC 7601 performed like a 16-core Xeon, the Skylake-SP system with 56 cores was hardly better than a 24-core Xeon E5 v4.
So we decided to turn our newest servers into virtual clusters. Our first attempt is to run with 4 executors. Researcher Esli Heyvaert also upgraded our Spark benchmark so it could run on the latest and greatest version: Apache Spark 2.1.1.
Here are the results:
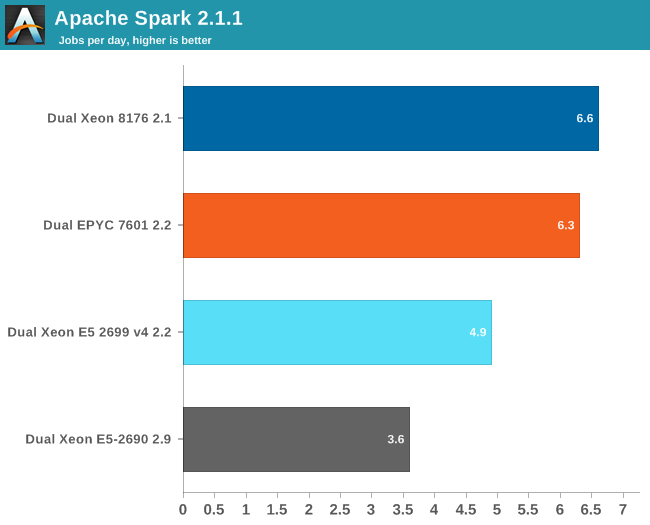
If you wonder who needs such server behemoths besides the people who virtualize a few dozen virtual machines, the answer is Big Data. Big Data crunching has an unsatisfiable hunger for – mostly integer – processing power. Even on our fastest machine, this test needs about 4 hours to finish. It is nothing less than a killer app.
Our Spark benchmark needs about 120 GB of RAM to run. The time spent on storage I/O is negligible. Data processing is very parallel, but the shuffle phases require a lot of memory interaction. The ALS phase does not scale well over many threads, but is less than 4% of the total testing time.
Given the higher clockspeed in lightly threaded and single threaded parts, the faster shuffle phase probably gives the Intel chip an edge of only about 5%.








219 Comments
View All Comments
Kaotika - Tuesday, July 11, 2017 - link
http://www.anandtech.com/show/11464/intel-announce...This one remains wrong though
Ian Cutress - Tuesday, July 11, 2017 - link
Always reference the newest piece, especially the main review.Or we'd spend half of our time going back and updating old pieces and reviews with new data.
scottb9239 - Tuesday, July 11, 2017 - link
On the POV-RAY benchmark, shouldn't that read as almost 16% faster than the dual 2699 v4 and 32% faster than the dual 8176?scienceomatica - Tuesday, July 11, 2017 - link
I think that a fair game would be to compare the top offer of one and the other manufacturer, in other words, the Xeon 8180 should be included in the benchmark regardless of the aspect of the price. Then the difference would be quite in favor of the Intel processor, although it has few cores less.Tamz_msc - Tuesday, July 11, 2017 - link
Will we get to see more FP HPC-oriented workloads like SPECfp2006 or even 2017 being discussed in a future article?lefty2 - Tuesday, July 11, 2017 - link
I can summarize this article: "$8719 chip beaten by $4200 chip in everything except database and Appache spark."Well done Intel, another Walletripper!
Shankar1962 - Wednesday, July 12, 2017 - link
Then why did google att aws etc upgraded to skylake. They could have saved billions of dollars.Shankar1962 - Wednesday, July 12, 2017 - link
Look at what big players upgrading to skylake reportedThese are real workloads
No one cares about labs
These numbers decide who wins and who loses
No wonder AMD sells at $4200
https://www.google.com/amp/s/seekingalpha.com/amp/...
nitrobg - Tuesday, July 11, 2017 - link
Pricing on page 10 should reflect that the 2P EPYC prices are for 2 processors, not per CPU. The price of Xeons is per CPU.coder543 - Tuesday, July 11, 2017 - link
That doesn't seem true. The prices they currently have seem to be correct. Got a source?