Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Apache Spark 2.1 Benchmarking
Apache Spark is the poster child of Big Data processing. Speeding up Big Data applications is the top priority project at the university lab I work for (Sizing Servers Lab of the University College of West-Flanders), so we produced a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large amount of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library "BoilerPipe". Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities ("words that mean something") out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
In previous articles, we tested with Spark 1.5 in standalone mode (non-clustered). That worked out well enough, but we saw diminishing returns as core counts went up. In hindsight, just dumping 300 GB of compressed data in one JVM was not optimal for 30+ core systems. The high core counts of the Xeon 8176 and EPYC 7601 caused serious performance issues when we first continued to test this way. The 64 core EPYC 7601 performed like a 16-core Xeon, the Skylake-SP system with 56 cores was hardly better than a 24-core Xeon E5 v4.
So we decided to turn our newest servers into virtual clusters. Our first attempt is to run with 4 executors. Researcher Esli Heyvaert also upgraded our Spark benchmark so it could run on the latest and greatest version: Apache Spark 2.1.1.
Here are the results:
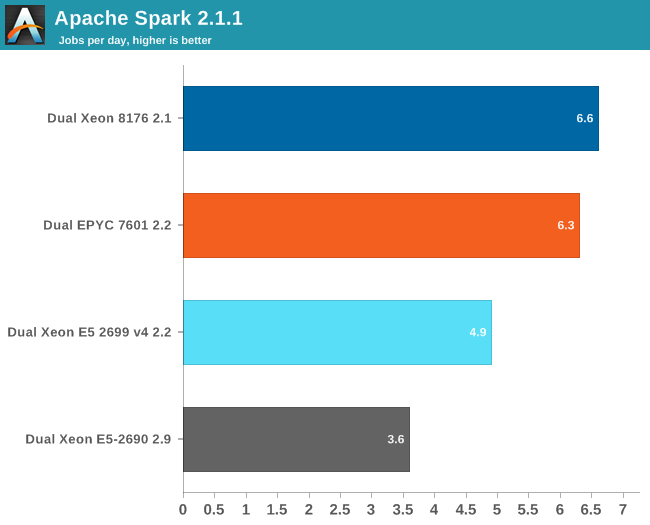
If you wonder who needs such server behemoths besides the people who virtualize a few dozen virtual machines, the answer is Big Data. Big Data crunching has an unsatisfiable hunger for – mostly integer – processing power. Even on our fastest machine, this test needs about 4 hours to finish. It is nothing less than a killer app.
Our Spark benchmark needs about 120 GB of RAM to run. The time spent on storage I/O is negligible. Data processing is very parallel, but the shuffle phases require a lot of memory interaction. The ALS phase does not scale well over many threads, but is less than 4% of the total testing time.
Given the higher clockspeed in lightly threaded and single threaded parts, the faster shuffle phase probably gives the Intel chip an edge of only about 5%.








219 Comments
View All Comments
CajunArson - Tuesday, July 11, 2017 - link
Would a high-end server that was built in 2014 necessarily update? Maybe not.Should a high-end server with a brand new microarchitecture use the most recent version of the software if it has any expectation of seeing a real benefit? Absolutely.
If this was a GPU review and Anandtech used 2 year old drivers on a new GPU (assuming they even worked at all) we wouldn't even be having this conversation.
BrokenCrayons - Tuesday, July 11, 2017 - link
Home users playing video games are in a different environment than you find in a business datacenter. There's a lot less money to be lost when a driver update causes a performance regression or eliminates a feature. Conversely, needlessly updating software in the aforementioned datacenter can result in the loss of many millions if something goes wrong.wallysb01 - Tuesday, July 11, 2017 - link
Conversely, having stuff working, but unnecessarily slowly costs money as well. Its a balance, and if you're spending hundreds of thousands or even millions on a cluster/data center/what have you, you'd probably want to spend at least a little bit of time optimizing it, right?Icehawk - Tuesday, July 11, 2017 - link
Most of the businesses I have worked for, ranging from 10 people to 50k, use severely outdated software and the barest minimum of patching. Optimization? HA!For example I work for a manufacturer & retailer currently, our POS system was last patched in 2012 by the vendor and has been replaced by at least two versions newer. We have XP machines in each of our stores as that is the only OS that can run the software.
The above is very typical. The 50k company I worked for had software so old and deeply entrenched that modernizing it is virtually impossible. My current company is working on getting to a new product... that was new in 2012 and has also been replaced with a newer version. Whee!
Icehawk - Tuesday, July 11, 2017 - link
One other thing - maybe the big shops actually do test/size but none of the places I have worked at and have been involved in do any testing, benchmarking, etc. They just buy whatever their preferred vendor gives them that meets the budget and they *think* will work. My coworker is in charge (lol) of selecting servers for a new office... he has no clue what anything in this article is. He has never read a single review, overview, or test of a processor. I could keep going on like this :(0ldman79 - Wednesday, July 12, 2017 - link
Icehawk's comments are so accurate it is scary.I can't tell you how many businesses running custom *nix software running in a VM on a Windows server.
They're not all about speed. Reliability is the single most important factor, speed is somewhere down the line. The people that make those decisions and the people that drink coffee while they're waiting on the machines are very different.
Neither understand that it could all be done so much better and almost all of them are utterly terrified at the concept of speeding up the process if it means *any* changes are made.
JohanAnandtech - Friday, July 21, 2017 - link
We did test with NAMD 2.12 (Dec 2016).sutamatamasu - Tuesday, July 11, 2017 - link
Glad, AMD make back again to this segment, now we can only see what can Raja to do for server market with Radeon instinct.Kaotika - Tuesday, July 11, 2017 - link
So this confirms that the previous information regarding Skylake-X core configurations was wrong, and 12-core variant is in fact using HCC-core instead of LCC-core?Ian Cutress - Tuesday, July 11, 2017 - link
We corrected that in our Skylake-X review.