Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Database Performance: MySQL Percona Server 5.7.0
For database benchmarking we still base our testing on Percona server 5.7, an enhanced drop-in replacement for MySQL. But we have updated our SQL benchmarking once again. This time we use Sysbench 1.0.7, which is a lot more efficient than the previous 0.4 and 0.5 versions. As a result, the measured numbers are quite a bit higher, especially on the strongest systems. So you cannot compare this with any similar Sysbench-based benchmarking we have done before.
For our testing we used the read-only OLTP benchmark, which is slightly less realistic, but still much more interesting than most other Sysbench tests. This allows us to measure CPU performance without creating an I/O bottleneck.
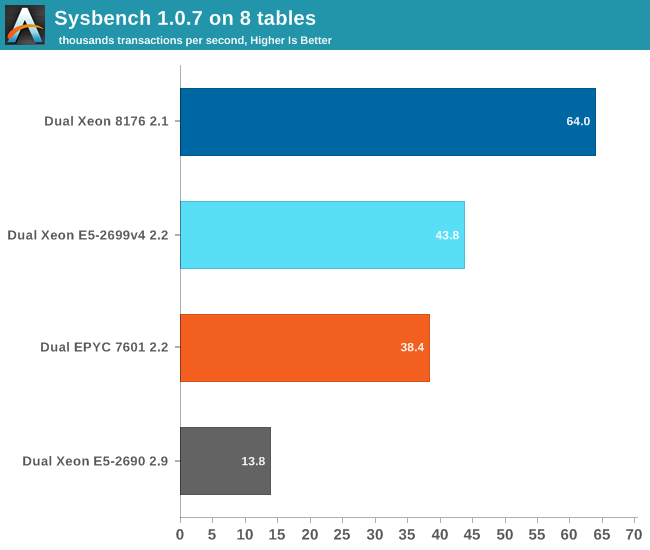
As expected, the EPYC 7601 can not deliver high database performance out of the box. A small database that can be mostly cached in the L3-cache is the worst case scenario for EPYC. That said, there are quite a few tuning opportunities on EPYC. According to AMD, if you enable Memory Interleaving, performance should rise a bit (+10-15%?). Unfortunately, a few days before our deadline our connection to the BMC failed, so we could not try it out. In a later article, we will go deeper into specific tuning for both platforms and test additional database systems.
Nevertheless, our point stands: out of the box is the EPYC CPU a rather mediocre transactional database CPU. With good tuning it is possible EPYC may pass the Xeon v4, but the 8176 is by far the champion here. It will be interesting to measure how EPYC compares in the non-transactional databases (Document stores, Key-value...) but transactional databases will remain Intel territory for now.
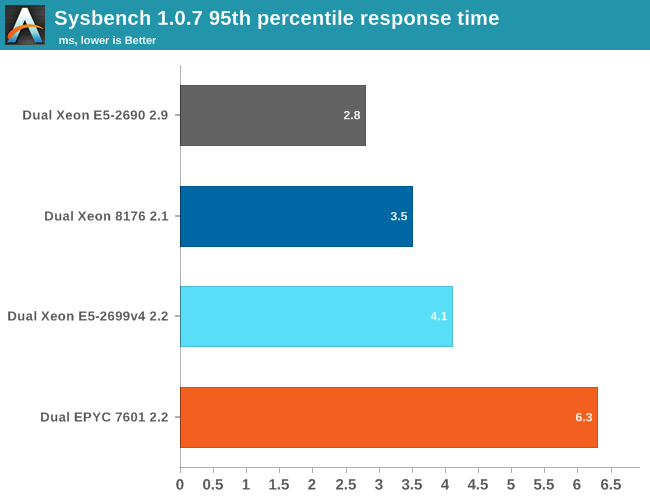
Typically when high response times were reported, this indicated low single threaded performance. However for EPYC this is not the case. We tested with a database that is quite a bit larger than the 8 MB L3-cache, and the high response time is probably a result of the L3-cache latency.








219 Comments
View All Comments
psychobriggsy - Tuesday, July 11, 2017 - link
Indeed it is a ridiculous comment, and puts the earlier crying about the older Ubuntu and GCC into context - just an Intel Fanboy.In fact Intel's core architecture is older, and GCC has been tweaked a lot for it over the years - a slightly old GCC might not get the best out of Skylake, but it will get a lot. Zen is a new core, and GCC has only recently got optimisations for it.
EasyListening - Wednesday, July 12, 2017 - link
I thought he was joking, but I didn't find it funny. So dumb.... makes me sad.blublub - Tuesday, July 11, 2017 - link
I kinda miss Infinity Fabric on my Haswell CPU and it seems to only have on die - so why is that missing on Haswell wehen Ryzen is an exact copy?blublub - Tuesday, July 11, 2017 - link
Your actually sound similar to JuanRGA at SAKevin G - Wednesday, July 12, 2017 - link
@CajunArson The cache hierarchy is radically different between these designs as well as the port arrangement for dispatch. Scheduling on Ryzen is split between execution resources where as Intel favors a unified approach.bill.rookard - Tuesday, July 11, 2017 - link
Well, that is something that could be figured out if they (anandtech) had more time with the servers. Remember, they only had a week with the AMD system, and much like many of the games and such, optimizing is a matter of run test, measure, examine results, tweak settings, rinse and repeat. Considering one of the tests took 4 hours to run, having only a week to do this testing means much of the optimization is probably left out.They went with a 'generic' set of relative optimizations in the interest of time, and these are the (very interesting) results.
CoachAub - Wednesday, July 12, 2017 - link
Benchmarks just need to be run on as level as a field as possible. Intel has controlled the market so long, software leans their way. Who was optimizing for Opteron chips in 2016-17? ;)theeldest - Tuesday, July 11, 2017 - link
The compiler used isn't meant to be the the most optimized, but instead it's trying to be representative of actual customer workloads.Most customer applications in normal datacenters (not google, aws, azure, etc) are running binaries that are many years behind on optimizations.
So, yes, they can get better performance. But using those optimizations is not representative of the market they're trying to show numbers for.
CajunArson - Tuesday, July 11, 2017 - link
That might make a tiny bit of sense if most of the benchmarks run were real-world workloads and not C-Ray or POV-Ray.The most real-world benchmark in the whole setup was the database benchmark.
coder543 - Tuesday, July 11, 2017 - link
The one benchmark that favors Intel is the "most real-world"? Absolutely, I want AnandTech to do further testing, but your comments do not sound unbiased.