Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Intel's New On-Chip Topology: A Mesh
Since the introduction of the "Nehalem" CPU architecture – and the Xeon 5500 that started almost a decade-long reign for Intel in the datacenter – Intel's engineers have relied upon a low latency, high bandwidth ring to connect their cores with their caches, memory controllers, and I/O controllers.
Intel's most recent adjustment to their ring topology came with the Ivy Bridge-EP (Xeon E5 2600 v2) family of CPUs. The top models were the first with three columns of cores connected by a dual ring bus, which utilized both outer and inner rings. The rings moved data in opposite directions (clockwise/counter-clockwise) in order to minimize latency by allowing data to take the shortest path to the destination. As data is brought onto the ring infrastructure, it must be scheduled so that it does not collide with previous data.
The ring topology had a lot of advantages. It ran very fast, up to 3 GHz. As result, the L3-cache latency was pretty low: if the core is lucky enough to find the data in its own cache slice, only one extra cycle is needed (on top of the normal L1-L2-L3 latency). Getting a cacheline of another slice can cost up to 12 cycles, with an average cost of 6 cycles.
However the ring model started show its limits on the high core count versions of the Xeon E5 v3, which had no less than four columns of cores and LLC slices, making scheduling very complicated: Intel had to segregate the dual ring buses and integrate buffered switches. Keeping cache coherency performant also became more and more complex: some applications gained quite a bit of performance by choosing the right snoop filter mode (or alternatively, lost a lot of performance if they didn't pick the right mode). For example, our OpenFOAM benchmark performance improved by almost 20% by choosing "Home Snoop" mode, while many easy to scale, compute-intensive applications preferred "Cluster On Die" snooping mode.
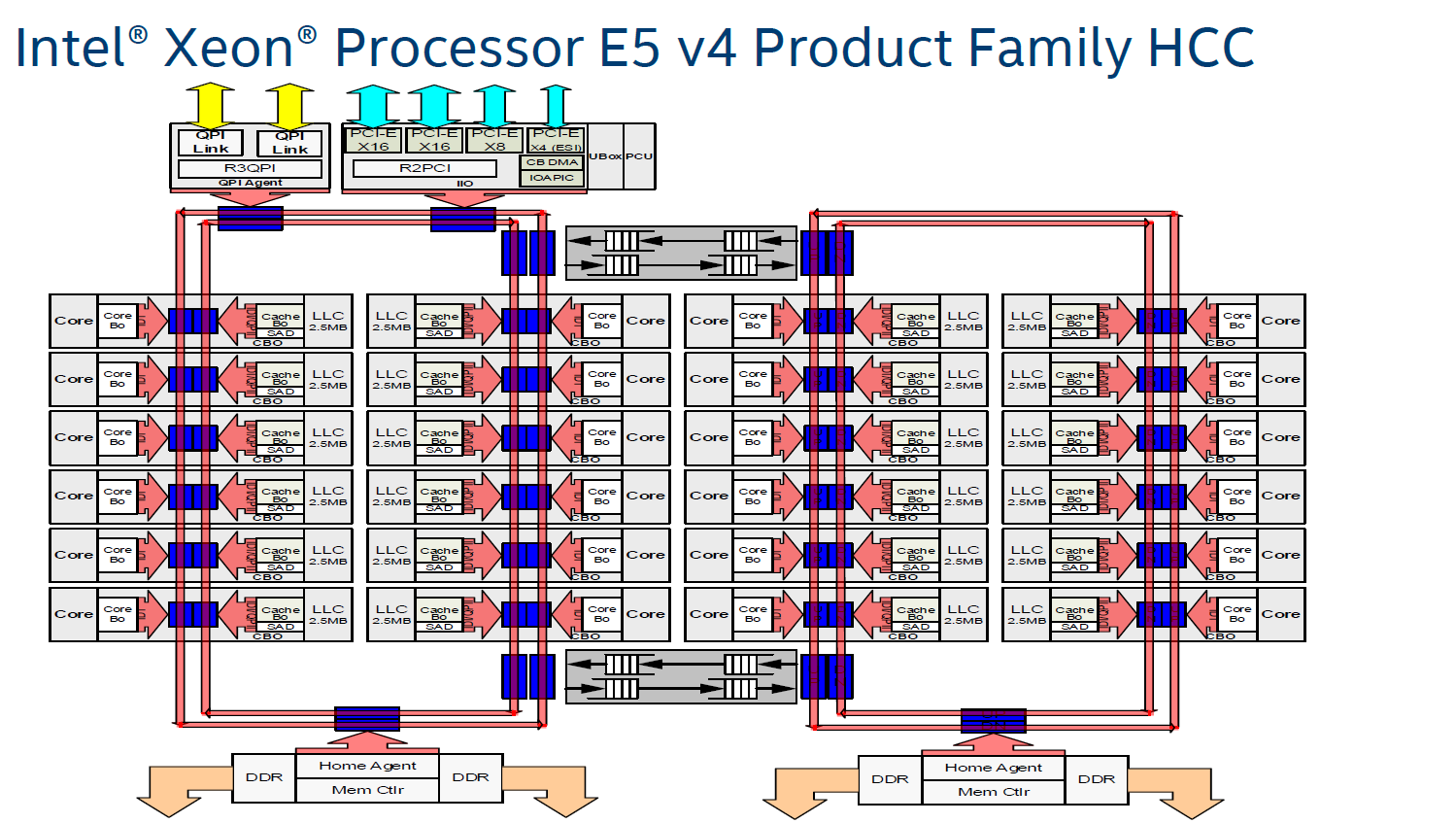
In other words, placing 22 (E7:24) cores, several PCIe controllers, and several memory controllers was close to the limit what a dual ring could support. In order to support an even larger number of cores than the Xeon v4 family, Intel would have to add a third ring, and ultimately connecting 3 rings with 6 columns of cores each would be overly complex.
Given that, it shouldn't come as a surprise that Intel's engineers decided to use a different topology for Skylake-SP to connect up to 28 cores with the "uncore." Intel's new solution? A mesh architecture.
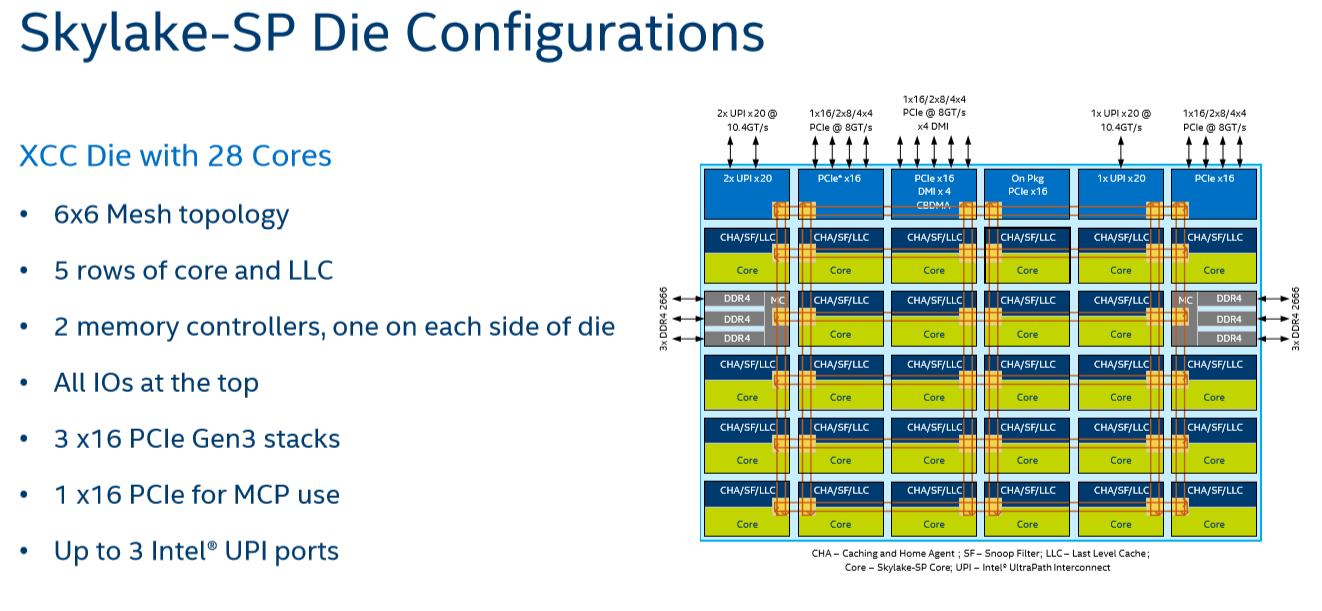
Under Intel's new topology, each node – a caching/home agent, a core, and a chunk of LLC – is interconnected via a mesh. Conceptually it is very similar to the mesh found on Xeon Phi, but not quite the same. In the long-run the mesh is far more scalable than Intel's previous ring topology, allowing Intel to connect many more nodes in the future.
How does it compare to the ring architecture? The Ring could run at up to 3 GHz, while the current mesh and L3-cache runs at at between 1.8GHZ and 2.4GHz. On top of that, the mesh inside the top Skylake-SP SKUs has to support more cores, which further increases the latency. Still, according to Intel the average latency to the L3-cache is only 10% higher, and the power usage is lower.

A core that access an L3-cache slice that is very close (like the ones vertically above each other) gets an additional latency of 1 cycle per hop. An access to a cache slice that is vertically 2 hops away needs 2 cycles, and one that is 2 hops away horizontally needs 3 cycles. A core from the bottom that needs to access a cache slice at the top needs only 4 cycles. Horizontally, you get a latency of 9 cycles at the most. So despite the fact that this Mesh connects 6 extra cores verse Broadwell-EP, it delivers an average latency in the same ballpark (even slightly better) as the former's dual ring architecture with 22 cores (6 cycles average).
Meanwhile the worst case scenario – getting data from the right top node to the bottom left node – should demand around 13 cycles. And before you get too concerned with that number, keep in mind that it compares very favorably with any off die communication that has to happen between different dies in (AMD's) Multi Chip Module (MCM), with the Skylake-SP's latency being around one-tenth of EPYC's. It is crystal clear that there will be some situations where Intel's server chip scales better than AMD's solution.
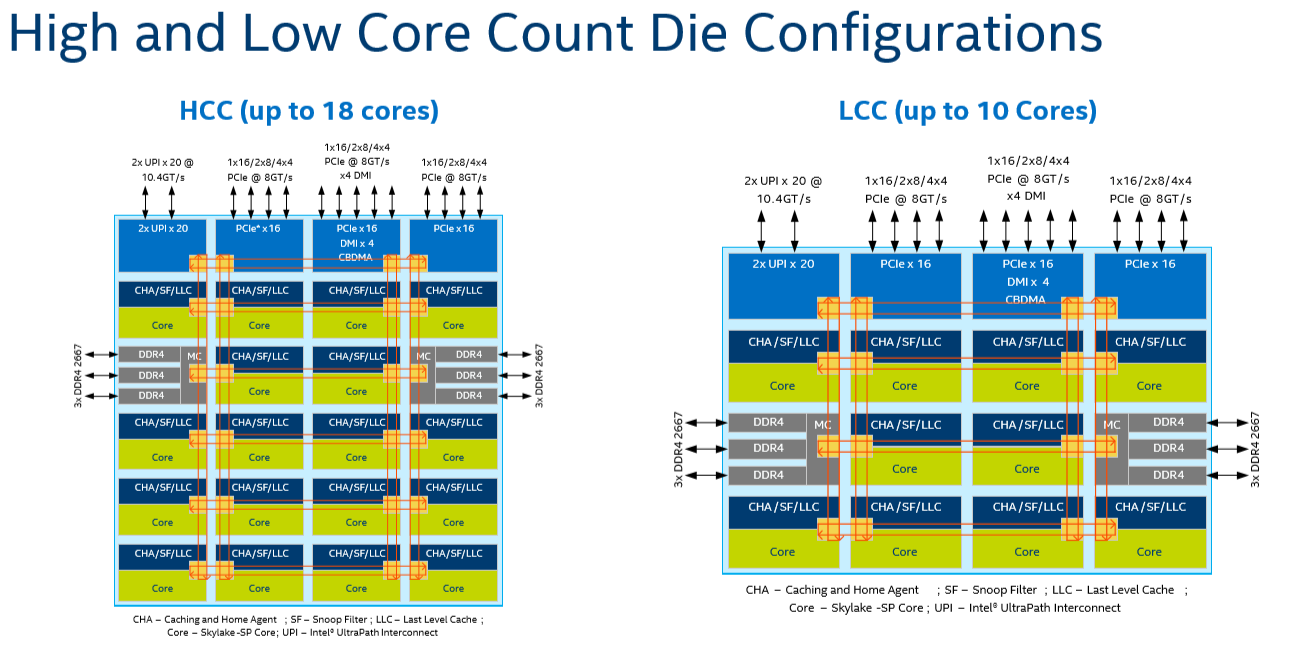
There are other advantages that help Intel's mesh scale: for example, caching and home agents are now distributed, with each core getting one. This reduces snoop traffic and reduces snoop latency. Also, the number of snoop modes is reduced: no longer do you need to choose between home snoop or early snoop. A "cluster-on-die" mode is still supported: it is now called sub-NUMA Cluster or SNC. With SNC you can divide the huge Intel server chips into two NUMA domains to lower the latency of the LLC (but potentially reduce the hitrate) and limit the snoop broadcasts to one SNC domain.








219 Comments
View All Comments
tamalero - Tuesday, July 11, 2017 - link
How is that different if AMD ran stuff that is extremely optimized for them?Friendly0Fire - Tuesday, July 11, 2017 - link
That's kinda the point? You want to benchmark the CPUs in optimal scenarios, since that's what you'd be looking at in practice. If one CPU's weakness is eliminated by using a more recent/tweaked compiler, then it's not a weakness.coder543 - Tuesday, July 11, 2017 - link
Rather, you want to test under practical scenarios. Very few people are going to be running 17.04 on production grade servers, they will run an LTS release, which in this case is 16.04.It would be good to have benchmarks from 17.04 as another point of comparison, but given how many things they didn't have time to do just using 16.04, I can understand why they didn't use 17.04.
Santoval - Wednesday, July 12, 2017 - link
A compromise can be found by upgrading Ubuntu 16.04's outdated kernel. Ubuntu LTS releases include support for rolling HWE Stacks, which is a simple meta package for installing newer kernels compiled, modified, tested and packaged by the Ubuntu Kernel Team, and installed directly from the official Ubuntu repositories (not via a Launchpad PPA). With HWE 16.04 LTS can install up to the kernel of 18.04 LTS.I also use 16.04 LTS + HWE (it just requires installing the linux-generic-hwe-16.04 package), which currently provides the 4.8 kernel. There is even a "beta" version of HWE (the same package plus an -edge at the end) for installing the 4.10 kernel (aka the kernel of 17.04) earlier, which will normally be released next month.
I just spotted various 4.10 kernel listings after checking in Synaptic, so they must have been added very recently. After that there are two more scheduled kernel upgrades, as is shown in the following link. Of course HWE upgrades solely the kernel, it does not upgrade any application or any of the user level parts to a more recent version of Ubuntu.
https://wiki.ubuntu.com/Kernel/RollingLTSEnablemen...
CajunArson - Tuesday, July 11, 2017 - link
Considering the similarities between RyZen and Haswell (that aren't coincidental at all) you are already seeing a highly optimized set of RyZen results.But I have no problem seeing RyZen be tested with the newest distros, the only difference being that even Ubuntu 16.04 already has most of the optimizations for RyZen baked in.
coder543 - Tuesday, July 11, 2017 - link
What similarities? They're extremely different architectures. I can't think of any obvious similarities. Between the CCX model, caches being totally different layouts, the infinity fabric, Intel having better AVX-256/512 stuff (IIRC), etc.I don't think 16.04 is naturally any more optimized for Ryzen than it is for Skylake-SP.
CajunArson - Tuesday, July 11, 2017 - link
Oh please, at the core level RyZen is a blatant copy-n-paste of Haswell with the only exception being they just omitted half the AVX hardware to make their lives easier.It's so obvious that if you followed any of the developer threads for people optimizing for RyZen they say to just use the Haswell compiler optimizations that actually work better than the official RyZen optimization flags.
ddriver - Tuesday, July 11, 2017 - link
Can't tell if this post is funny or sad.CajunArson - Tuesday, July 11, 2017 - link
It's neither: It's accurate.Don't believe me? Look at the differences in performance of the holy 1800X over multiple Linux distros ranging from pretty new (OpenSuse Tumbleweed) to pretty old (Fedora 23 from 2015): http://www.phoronix.com/scan.php?page=article&...
Nowhere near the variation that we see with Skylake X since Haswell was already a solved problem long before RyZen lauched.
coder543 - Tuesday, July 11, 2017 - link
Right, of course. Ryzen is a copy-and-paste of Haswell.Don't make me laugh.