Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Latency
The performance of modern CPUs depends heavily on the cache subsystem. And some applications depend heavily on the DRAM subsystem too. We used LMBench in an effort to try to measure cache and memory latency. The numbers we looked at were "Random load latency stride=16 Bytes".
| Mem Hierarchy |
AMD EPYC 7601 DDR4-2400 |
Intel Skylake-SP DDR4-2666 |
Intel Broadwell Xeon E5-2699v4 DDR4-2400 |
| L1 Cache cycles | 4 | 4 | 4 |
| L2 Cache cycles | 12 | 14-22 | 12-15 |
| L3 Cache 4-8 MB - cycles | 34-47 | 54-56 | 38-51 |
| 16-32 MB - ns | 89-95 ns | 25-27 ns (+/- 55 cycles?) |
27-42 ns (+/- 47 cycles) |
| Memory 384-512 MB - ns | 96-98 ns | 89-91 ns | 95 ns |
Previously, Ian has described the AMD Infinity Fabric that stitches the two CCXes together in one die and interconnects the 4 different "Zeppelin" dies in one MCM. The choice of using two CCXes in a single die is certainly not optimal for Naples. The local "inside the CCX" 8 MB L3-cache is accessed with very little latency. But once the core needs to access another L3-cache chunk – even on the same die – unloaded latency is pretty bad: it's only slightly better than the DRAM access latency. Accessing DRAM is on all modern CPUs a naturally high latency operation: signals have to travel from the memory controller over the memory bus, and the internal memory matrix of DDR4-2666 DRAM is only running at 333 MHz (hence the very high CAS latencies of DDR4). So it is surprising that accessing SRAM over an on-chip fabric requires so many cycles.
What does this mean to the end user? The 64 MB L3 on the spec sheet does not really exist. In fact even the 16 MB L3 on a single Zeppelin die consists of two 8 MB L3-caches. There is no cache that truly functions as single, unified L3-cache on the MCM; instead there are eight separate 8 MB L3-caches.
That will work out fine for applications that have a footprint that fits within a single 8 MB L3 slice, like virtual machines (JVM, Hypervisors based ones) and HPC/Big Data applications that work on separate chunks of data in parallel (for example, the "map" phase of "map/reduce"). However this kind of setup will definitely hurt the performance of applications that need "central" access to one big data pool, such as database applications and big data applications in the "Shuffle phase".
Memory Subsystem: TinyMemBench
To double check our latency measurements and get a deeper understanding of the respective architectures, we also use the open source TinyMemBench benchmark. The source was compiled for x86 with GCC 5.4 and the optimization level was set to "-O3". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
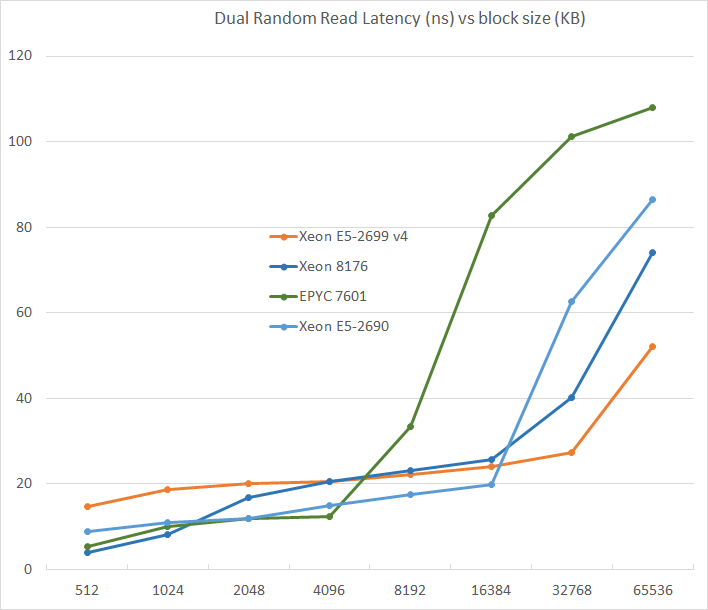
L3-cache sizes have increased steadily over the years. The Xeon E5 v1 had up to 20 MB, v3 came with 45 MB, and v4 "Broadwell EP" further increased this to 55 MB. But the fatter the cache, the higher the latency became. L3 latency doubled from Sandy Bridge-EP to Broadwell-EP. So it is no wonder that Skylake went for a larger L2-cache and a smaller but faster L3. The L2-cache offers 4 times lower latency at 512 KB.
AMD's unloaded latency is very competitive under 8 MB, and is a vast improvement over previous AMD server CPUs. Unfortunately, accessing more 8 MB incurs worse latency than a Broadwell core accessing DRAM. Due to the slow L3-cache access, AMD's DRAM access is also the slowest. The importance of unloaded DRAM latency should of course not be exaggerated: in most applications most of the loads are done in the caches. Still, it is bad news for applications with pointer chasing or other latency-sensitive operations.








219 Comments
View All Comments
JKflipflop98 - Wednesday, July 12, 2017 - link
For years I thought you were just really committed to playing the "dumb AMD fanbot" schtick for laughs. It's infinitely more funny now that I know you've actually been *serious* this entire time.ddriver - Wednesday, July 12, 2017 - link
Whatever helps you feel better about yourself ;) I bet it is funny now, that AT have to carefully devise intel biased benches and lie in its reviews in hopes intel at least saves face. BTW I don't have a single amd CPU running ATM.WinterCharm - Thursday, July 13, 2017 - link
Uh, what are you smoking? this is a pretty even piece.boozed - Tuesday, July 11, 2017 - link
You haven't done your job properly unless you've annoyed the fanboys (and perhaps even fangirls) for both sides!JohanAnandtech - Wednesday, July 12, 2017 - link
Wise words. Indeed :-)Ranger1065 - Wednesday, July 12, 2017 - link
If you are referring to ddriver, I agree, wise words indeed.ddriver - Wednesday, July 12, 2017 - link
Well, that assumption rests on the presumption that the point of reviews is to upsed fanboys.I'd say that a "review done right" would include different workload scenarios, there is nothing wrong with having one that will show the benefits of intel's approach to doing server chips, but that should be properly denoted, and should be just one of several database tests and should be accompanied by gigabytes of databases which is what we use in real world scenarios.
CoachAub - Wednesday, July 12, 2017 - link
It was mentioned more than once that this review was rushed to make a deadline and that the suite of benchmarks were not everything they wanted to run and without optimizations or even the usual tweaks an end-user would make to their system. So, keep that in mind as you argue over the tests and different scenarios, etc.ddriver - Thursday, July 13, 2017 - link
It doesn't take a lot of time to populate a larger database so that you can make a benchmark that involves an actual real world usage scenario. It wasn't the "rushing" that prompted the choice of database size...mpbello - Friday, July 14, 2017 - link
If you are rushing, you reduce scope and deliver fewer pieces with high quality instead of insisting on delivering a full set of benchmarks that you are not sure about its quality.The article came to a very strong conclusion: Intel is better for database scenarios. Whatever you do, whether you are rushing or not, you cannot state something like that if the benchmarks supporting your conclusion are not well designed.
So I agree that the design of the DB benchmark was incredibly weak to sustain such an important conclusion that Intel is the best choice for DB applications.