Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Bandwidth
Measuring the full bandwidth potential with John McCalpin's Stream bandwidth benchmark is getting increasingly difficult on the latest CPUs, as core and memory channel counts have continued to grow. We compiled the stream 5.10 source code with the Intel compiler (icc) for linux version 17, or GCC 5.4, both 64-bit. The following compiler switches were used on icc:
icc -fast -qopenmp -parallel (-AVX) -DSTREAM_ARRAY_SIZE=800000000
Notice that we had to increase the array significantly, to a data size of around 6 GB. We compiled one version with AVX and one without.
The results are expressed in gigabytes per second.
Meanwhile the following compiler switches were used on gcc:
-Ofast -fopenmp -static -DSTREAM_ARRAY_SIZE=800000000
Notice that the DDR4 DRAM in the EPYC system ran at 2400 GT/s (8 channels), while the Intel system ran its DRAM at 2666 GT/s (6 channels). So the dual socket AMD system should theoretically get 307 GB per second (2.4 GT/s* 8 bytes per channel x 8 channels x 2 sockets). The Intel system has access to 256 GB per second (2.66 GT/s* 8 bytes per channel x 6 channels x 2 sockets).
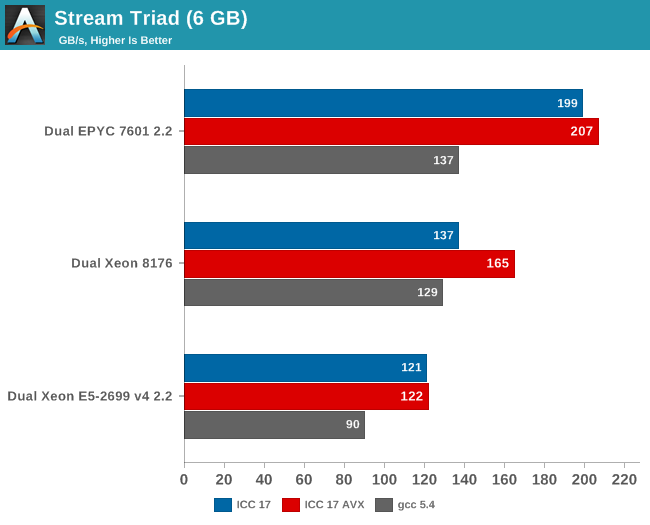
AMD told me they do not fully trust the results from the binaries compiled with ICC (and who can blame them?). Their own fully customized stream binary achieved 250 GB/s. Intel claims 199 GB/s for an AVX-512 optimized binary (Xeon E5-2699 v4: 128 GB/s with DDR-2400). Those kind of bandwidth numbers are only available to specially tuned AVX HPC binaries.
Our numbers are much more realistic, and show that given enough threads, the 8 channels of DDR4 give the AMD EPYC server a 25% to 45% bandwidth advantage. This is less relevant in most server applications, but a nice bonus in many sparse matrix HPC applications.
Maximum bandwidth is one thing, but that bandwidth must be available as soon as possible. To better understand the memory subsystem, we pinned the stream threads to different cores with numactl.
| Pinned Memory Bandwidth (in MB/sec) | |||
| Mem Hierarchy |
AMD "Naples" EPYC 7601 DDR4-2400 |
Intel "Skylake-SP" Xeon 8176 DDR4-2666 |
Intel "Broadwell-EP" Xeon E5-2699v4 DDR4-2400 |
| 1 Thread | 27490 | 12224 | 18555 |
| 2 Threads, same core same socket |
27663 | 14313 | 19043 |
| 2 Threads, different cores same socket |
29836 | 24462 | 37279 |
| 2 Threads, different socket | 54997 | 24387 | 37333 |
| 4 threads on the first 4 cores same socket |
29201 | 47986 | 53983 |
| 8 threads on the first 8 cores same socket |
32703 | 77884 | 61450 |
| 8 threads on different dies (core 0,4,8,12...) same socket |
98747 | 77880 | 61504 |
The new Skylake-SP offers mediocre bandwidth to a single thread: only 12 GB/s is available despite the use of fast DDR-4 2666. The Broadwell-EP delivers 50% more bandwidth with slower DDR4-2400. It is clear that Skylake-SP needs more threads to get the most of its available memory bandwidth.
Meanwhile a single thread on a Naples core can get 27,5 GB/s if necessary. This is very promissing, as this means that a single-threaded phase in an HPC application will get abundant bandwidth and run as fast as possible. But the total bandwidth that one whole quad core CCX can command is only 30 GB/s.
Overall, memory bandwidth on Intel's Skylake-SP Xeon behaves more linearly than on AMD's EPYC. All off the Xeon's cores have access to all the memory channels, so bandwidth more directly increases with the number of threads.








219 Comments
View All Comments
TheOriginalTyan - Tuesday, July 11, 2017 - link
Another nicely written article. This is going to be a very interesting next couple of months.coder543 - Tuesday, July 11, 2017 - link
I'm curious about the database benchmarks. It sounds like the database is tiny enough to fit into L3? That seems like a... poor benchmark. Real world databases are gigabytes _at best_, and AMD's higher DRAM bandwidth would likely play to their favor in that scenario. It would be interesting to see different sizes of transactional databases tested, as well as some NoSQL databases.psychobriggsy - Tuesday, July 11, 2017 - link
I wrote stuff about the active part of a larger database, but someone's put a terrible spam blocker on the comments system.Regardless, if you're buying 64C systems to run a DB on, you likely will have a dataset larger than L3, likely using a lot of the actual RAM in the system.
roybotnik - Wednesday, July 12, 2017 - link
Yea... we use about 120GB of RAM on the production DB that runs our primary user-facing app. The benchmark here is useless.haplo602 - Thursday, July 13, 2017 - link
I do hope they elaborate on the DB benchmarks a bit more or do a separate article on it. Since this is a CPU article, I can see the point of using a small DB to fit into the cache, however that is useless as an actual DB test. It's more an int/IO test.I'd love to see a larger DB tested that can fit into the DRAM but is larger than available caches (32GB maybe ?).
ddriver - Tuesday, July 11, 2017 - link
We don't care about real world workloads here. We care about making intel look good. Well... at this point it is pretty much damage control. So let's lie to people that intel is at least better in one thing.Let me guess, the databse size was carefully chosen to NOT fit in a ryzen module's cache, but small enough to fit in intel's monolithic die cache?
Brought to you by the self proclaimed "Most Trusted in Tech Since 1997" LOL
Ian Cutress - Tuesday, July 11, 2017 - link
I'm getting tweets saying this is a severely pro AMD piece. You are saying it's anti-AMD. ¯\_(ツ)_/¯ddriver - Tuesday, July 11, 2017 - link
Well, it is hard to please intel fanboys regardless of how much bias you give intel, considering the numbers.I did not see you deny my guess on the database size, so presumably it is correct then?
ddriver - Tuesday, July 11, 2017 - link
In the multicore 464.h264ref test we have 2670 vs 2680 for the xeon and epyc respectively. Considering that the epyc score is mathematically higher, howdoes it yield a negative zero?Granted, the difference is a mere 0.3% advantage for epyc, but it is still a positive number.
Headley - Friday, July 14, 2017 - link
I thought the exact same thing