Intel to Build Silicon for Fully Homomorphic Encryption: This is Important
by Dr. Ian Cutress on March 8, 2021 11:00 AM EST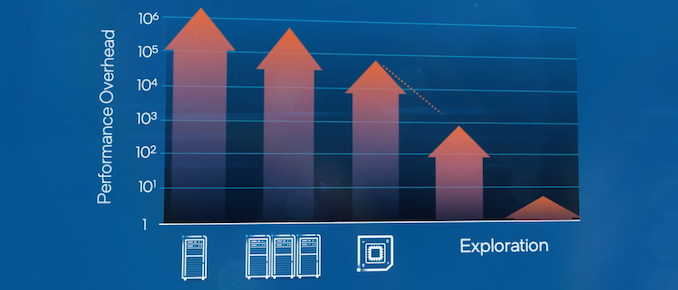
When considering data privacy and protections, there is no data more important than personal data, whether that’s medical, financial, or even social. The discussions around access to our data, or even our metadata, becomes about who knows what, and if my personal data is safe. Today’s announcement between Intel, Microsoft, and DARPA, is a program designed around keeping information safe and encrypted, but still using that data to build better models or provide better statistical analysis without disclosing the actual data. It’s called Fully Homomorphic Encryption, but it is so computationally intense that the concept is almost useless in practice. This program between the three companies is a driver to provide IP and silicon to accelerate the compute, enabling a more secure environment for collaborative data analysis.
Mind Your Data
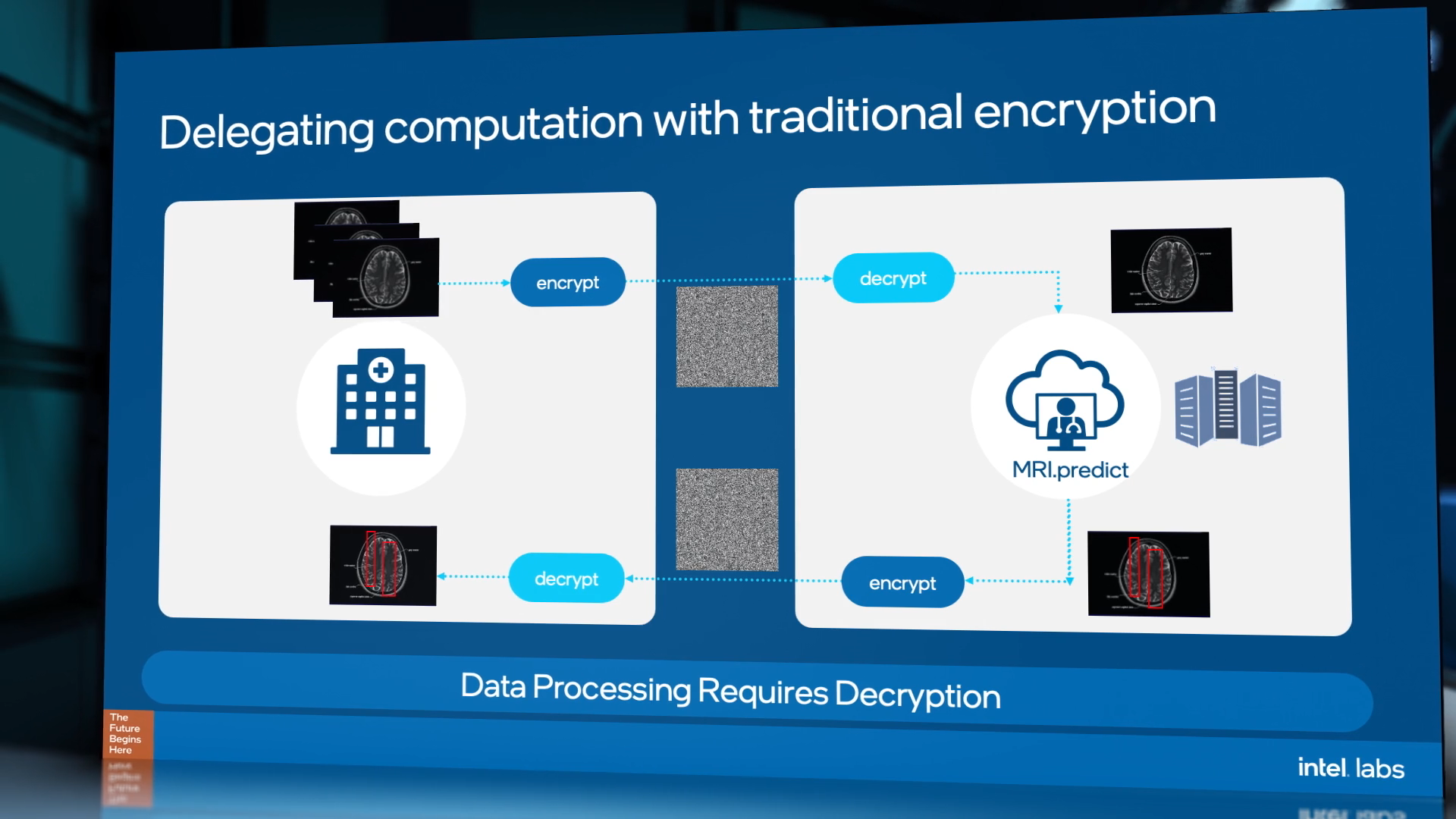
Data protection is one of the most important aspects to the future of computing. The volume of personal data is continually growing, as well as the value of that data, and the number of legal protections required. This makes any processing of personal, private, and confidential data difficult, often resulting in dedicated data silos, because any processing requires data transfer coupled with encryption/decryption, involving trust that isn’t always possible. All it takes is for one key in the chain to be lost or leaked, and the dataset is compromised.
There is a way around this, known as Fully Homomorphic Encryption (FHE). FHE enables the ability to take encrypted data, transfer it to where it needs to go, perform calculations on it, and get results without ever knowing the exact underlying dataset.
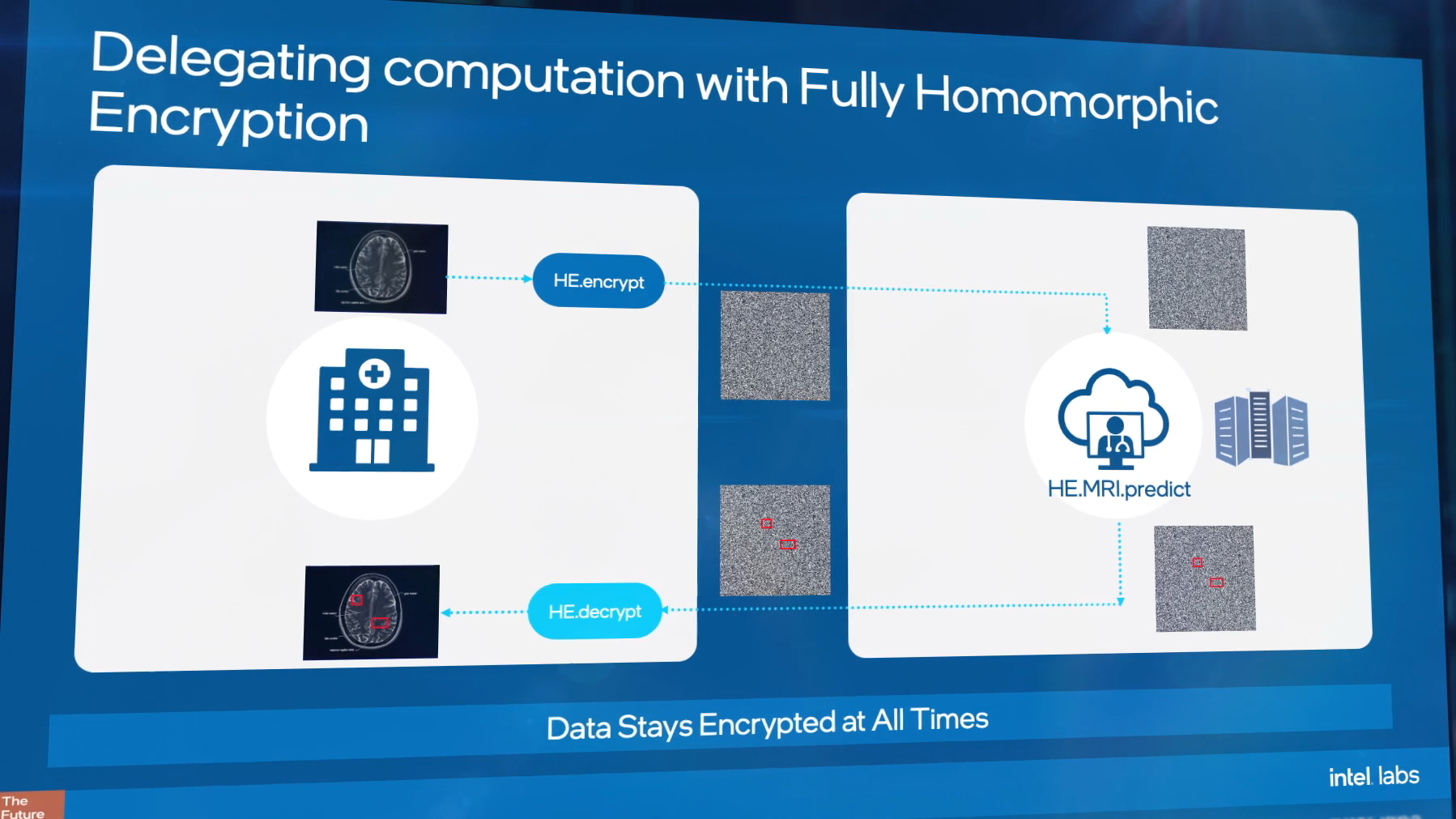
Take for example, analyzing medical data records: if a researcher needs to process a specific data-set for some analysis, the traditional method would be to encrypt the data, send the data, decrypt the data, and process it – but giving the researcher access to the specifics in the records might not be legal or face regulatory challenges. With FHE, that researcher can take the encrypted data, perform the analysis and get a result, without ever knowing any specifics of the dataset. This might involve combined statistical analysis of a population over multiple encrypted datasets, or taking those encrypted datasets and using them as additional inputs to train machine learning algorithms, enhancing the accuracy through having more data. Of course, the researcher has to have trust that the data given is complete and genuine, however that is arguably a different topic than enabling compute on encrypted data.
One of the issues as to why this matters is because the best insights from data come from the largest datasets. This includes being able to train a neural network, and the best neural networks are coming against issues of not having enough data, or are facing regulatory hurdles when it comes to the sensitive nature of that data. This is why Fully Homomorphic Encryption, the ability to analyze data without knowing its contents, matters.
Fully Homomorphic Encryption, as a concept, has been around for several decades, however the concept has only been realized in the last 20 years or so. A number of partial homomorphic encryption schemes were presented in that initial timeframe, and since 2010 several PHE/FHE designs able to process basic operations on encrypted data or cyphertexts have been developed with a number of libraries developed with industry standards. Some of these are open source. A lot of these methods are computationally complex for obvious reasons due to dealing with encrypted data, although efforts are being made with SIMD-like packing and other features to accelerate processing. Even though FHE schemes are being accelerated, this isn’t the same as decryption, because the math doesn’t decrypt the data - because the data is always in an encrypted state, it can (arguably) be used by untrusted third parties as the underlying information is never exposed. (One might argue that a sufficient dataset could reveal more than intended despite being encrypted.)
Today’s Announcement: Custom Silicon for FHE
When measuring the performance of FHE compute, the result is compared to the same analysis against the plain text version of the data. Because of the computational complexity of FHE compute, current compute methods are substantially slower. Encryption methods to enable FHE can increase the size of the data by 100-1000x, and then compute on that data is 10000x to 1 million times slower than conventional compute. That means that one second of compute on the raw data can take from 3 hours to 12 days.

So whether that means combining hospital medical records over a state, or customizing a personal service using personal metadata gathered on a user’s smartphone, FHE at that scale is no longer a viable solution. Enter the DARPA DPRIVE program.
- DARPA: Defense Advanced Research Projects Agency
- DPRIVE: Data Protection in Virtual Environments
Intel has announced that as part of the DPRIVE program, it has signed an agreement with DARPA to develop custom IP leading to silicon to enable faster FHE in the cloud, specifically with Microsoft on both Azure and JEDI cloud, initially with the US government. As part of this multi-year project, expertise from Intel Labs, Intel’s Design Engineering, and Intel’s Data Platforms Group will come together to create a dedicated ASIC to reduce the computational overhead of FHE over existing CPU-based methods. The press release states that the target is to reduce processing time by five orders of magnitude from current methods, reducing compute times from days to minutes.
Intel already has a foot in the door when it comes to FHE, having a research team inside Intel Labs dedicated to the issue. This has primarily been on the side of software, standards, and regulatory hurdles, but will now also move into hardware design, cloud software stacks, and collaborative deployment within Azure and JEDI cloud for the US government. Other highlighted target markets include healthcare, insurance, and finance.

During the Intel Labs day in December 2020, Intel detailed some of the direction it was already going in with this work, along with standards and development to parallel traditional encryption but at an international scale given the additional regulatory hurdles. Microsoft will now become part of that discussion with the DPRIVE program, along with Intel’s continued investments at the academic level.
Aside from the ‘five orders of magnitude’ element, today’s announcement doesn’t go beyond that in creating definitive goals, nor does it present a time-frame, instead saying this is a ‘multi-year’ agreement. It will be interesting to see how much Intel or their academic affiliations discuss on the topic beyond today, beyond the work standardization.
Related Reading
- Federated Learning and Fully Homomorphic Encryption at Intel Labs Day 2020
- Microsemi Announces SmartRAID Cards With On-Board Supercapacitors And Encryption
- Synaptics Discusses Fingerprint Security and the Need For End-to-End Encryption








31 Comments
View All Comments
jtd871 - Monday, March 8, 2021 - link
Anybody else immediately think that DPRIVE is an unfortunately horrible acronym?!MenhirMike - Monday, March 8, 2021 - link
It deprives hackers of your dataOxford Guy - Wednesday, March 10, 2021 - link
Depends on how broad one’s definition of hacker is.There should be a ‘law’: No large government will permit the sale of undefeatable security.
I read the claim that 512-bit encryption is illegal for ‘ordinary’ US citizens to use — as if that would matter since the hardware is compromised already. Sure, go ahead and run anything you like while the little friend on Londo’s shoulder isn’t sleeping.
ballsystemlord - Monday, March 8, 2021 - link
Spelling and grammar errors:"...but it is so computationally intense that the concept almost useless in practice."
Missing "is":
"but it is so computationally intense that the concept is almost useless in practice."
Ryan Smith - Monday, March 8, 2021 - link
Thanks!mwalker0 - Monday, March 8, 2021 - link
This is one step closer to being able to have compute as a commodity.theVergeOf - Monday, March 8, 2021 - link
How so? This is encrypt/decrypt as a service. Not Compute in a general sense.mwalker0 - Monday, March 8, 2021 - link
"FHE enables the ability to take encrypted data, transfer it to where it needs to go, perform calculations on it, and get results without ever knowing the exact underlying dataset."Imagine I want to train a network but I don't want to share my training data to anyone because it is proprietary but I do not have the processing power to train the network my self. so I look around to see if I can find the cheapest processing provider I can. I can use GWS(Google Web Services), or RPP(Russia Processing Provider). RPP is the cheapest and less secure and GWS is the most expensive but more secure. If I cant encrypt my data and the processing provider gets access to the raw training data then I have to use GWS and pay whatever they demand, but if I can encrypt my data and they can train a network on a encrypted dataset then I dont care who is more secure. I will just pick whoever is cheaper. Also once I have my network trained I can send my trained network to another processing provider to preform analysis if another processing provider becomes cheaper. This cuts out the security market differentiation in the cloud space making for more competition and lower prices.
grant3 - Tuesday, March 9, 2021 - link
FHE is still orders of magnitude more expensive than working on unencrypted data, and even the most optimistic future exploration has it remaining many multiples more expensive.So sure, you can buy some half-price russian cloud service, but you're still going to use 5x as much compute power (even assuming Intel's greatest dreams are realized) so you're still paying several times more than if you were working on unencrypted data on a server you trust.
FHE will make working on unencrypted data *feasible* but it will not be *cheaper*.
akvadrako - Tuesday, March 9, 2021 - link
What FHE provides is not encryption – it's processing on encrypted data without exposing that data to the data processor.However it's still so much slower than doing it yourself that it doesn't makes sense for a service.