The Snapdragon 855 Phone Roundup: Searching for the Best Implementations
by Andrei Frumusanu on September 5, 2019 8:30 AM ESTMachine Learning Inference Performance
AIMark 3
AIMark makes use of various vendor SDKs to implement the benchmarks. This means that the end-results really aren’t a proper apples-to-apples comparison, however it represents an approach that actually will be used by some vendors in their in-house applications or even some rare third-party app.
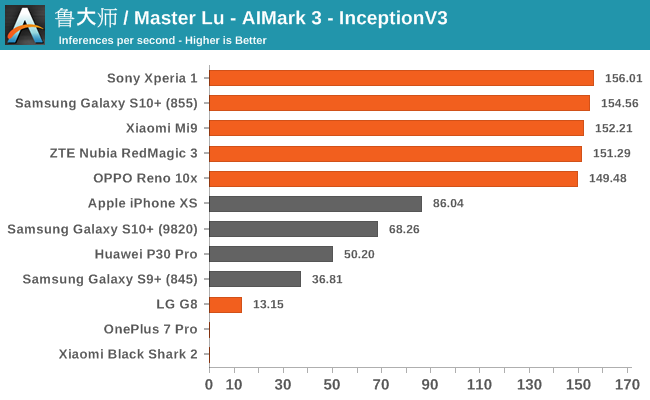
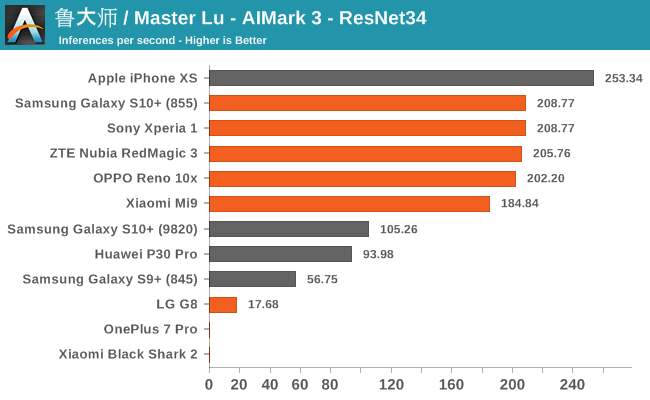
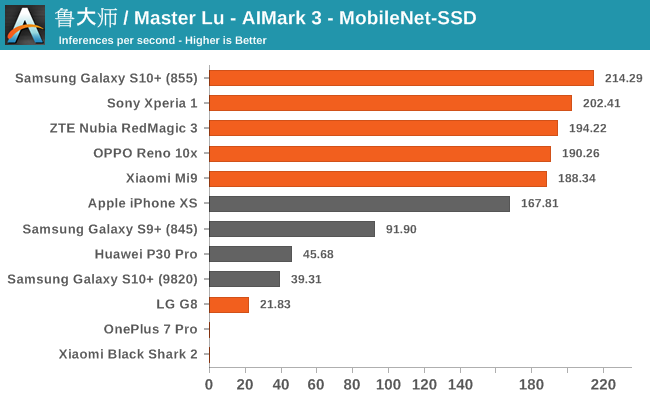

Summarizing the four sub-tests of AIMark 3, we see a few clear outliers: OnePlus 7 Pro and Xiaomi’s Black Shark 2 lack Qualcomms driver libraries on which the benchmark relies on (or they’re broken), and the application crashes. Another outlier is the G8, here the phone also lacked the libraries for hardware acceleration, but the app at least fell back onto CPU execution of the workloads, albeit at a massive performance penalty.
We notably see that AIMark has been able to implement Samsung’s NPU SDK as we’re seeing evident hardware acceleration. Huawei’s P30 Pro also makes use of its NPU here via its proprietary SDK. Naturally, Apple’s iPhone XS uses the CoreML framework to accelerate the AI workloads.
Overall, the Snapdragon 855 devices with the latest SDKs and frameworks here seem to compete extremely well, offering extensive performance that is leading the pack across all the different sub-tests.
AIBenchmark 3
AIBenchmark takes a different approach to benchmarking. Here the test uses the hardware agnostic NNAPI in order to accelerate inferencing, meaning it doesn’t use any proprietary aspects of a given hardware except for the drivers that actually enable the abstraction between software and hardware. This approach is more apples-to-apples, but also means that we can’t do cross-platform comparisons, like testing iPhones.
We’re publishing one-shot inference times. The difference here to sustained performance inference times is that these figures have more timing overhead on the part of the software stack from initialising the test to actually executing the computation.
AIBenchmark 3 - NNAPI CPU
We’re segregating the AIBenchmark scores by execution block, starting off with the regular CPU workloads that simply use TensorFlow libraries and do not attempt to run on specialized hardware blocks.
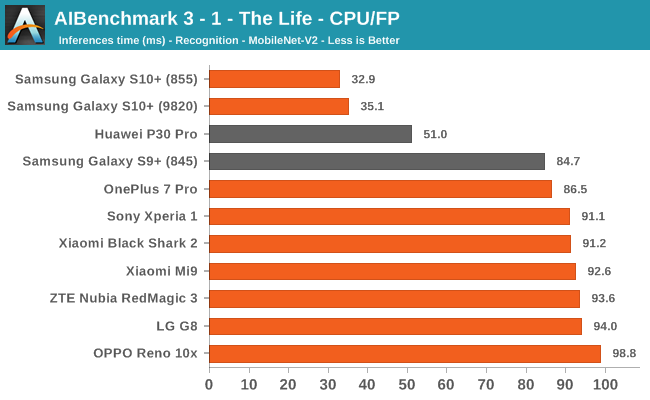
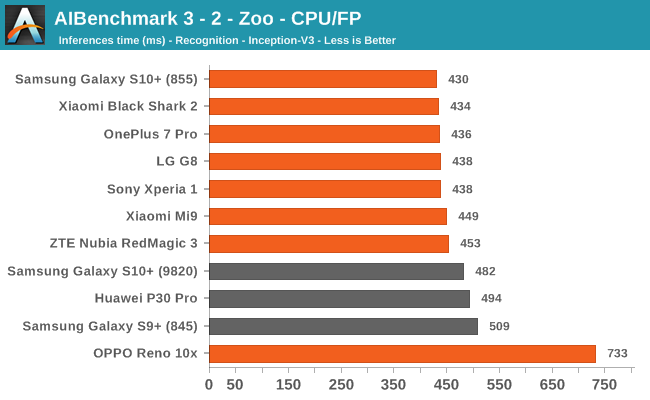
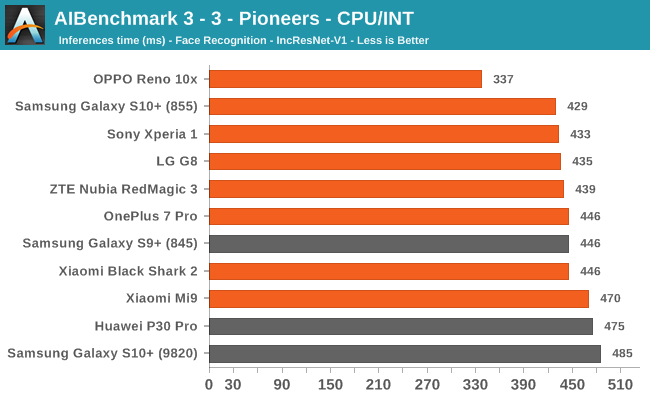
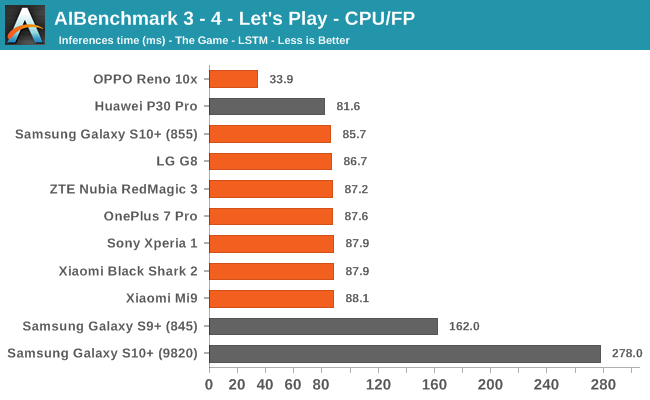


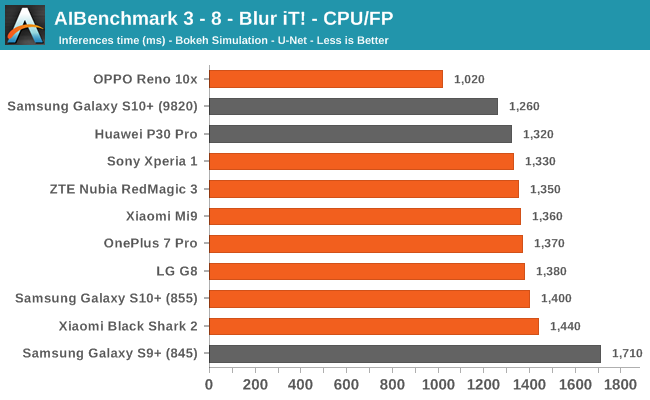
We’re seeing largely regular results here, although some observations pop up again, such as seeing that the Black Shark 2 having a very conservative result in some subtests. The other big outlier is the OPPO Reno 10x, here we’re seeing that the phone consistently performs better than the rest of the pack. This is very interesting, particularly because the phone actually isn’t able to actually use the NNAPI acceleration in the subsequent tests we’re covering next. This means that the “plain” TensorFlow libraries the OPPO is making use of are performing better than what’s employed for the rest of the devices.
AIBenchmark 3 - NNAPI INT8
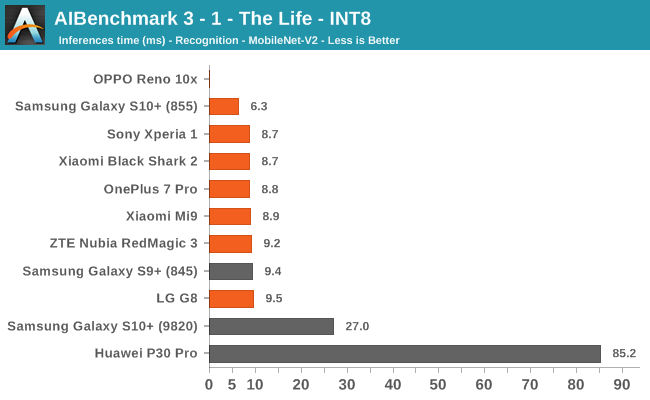
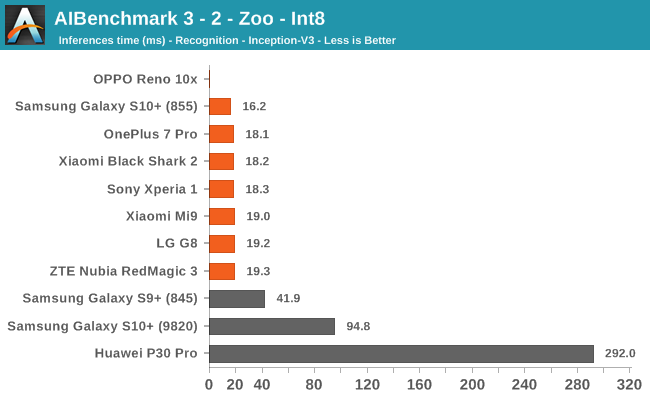
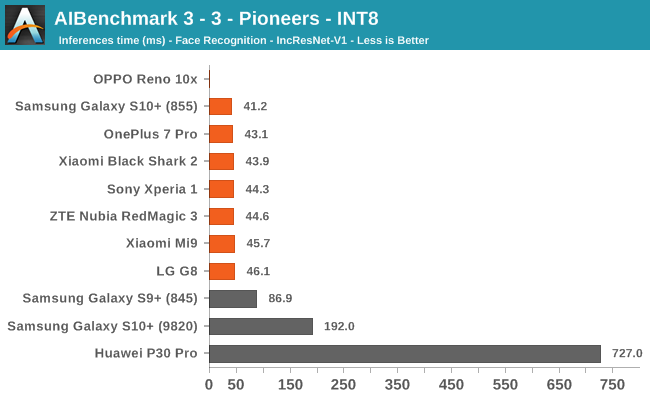
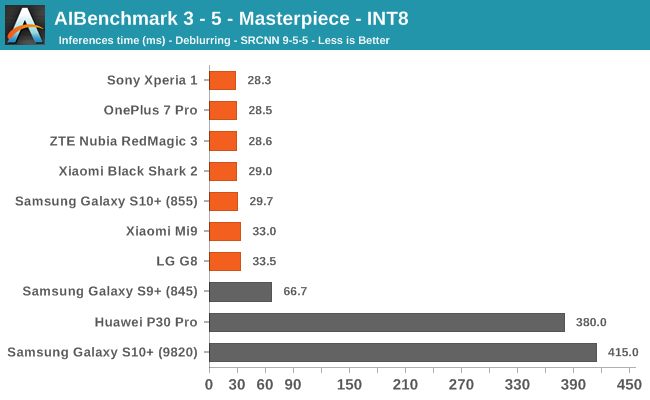
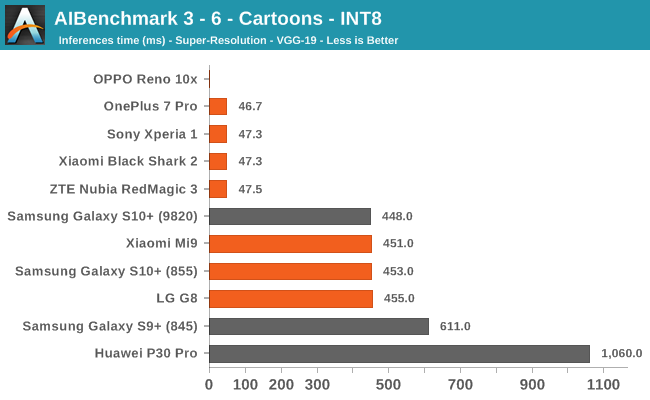
INT8 performance is dominated by the Snapdragon 855 devices, and this is thanks to the vector processing units of the Hexagon DSP. Test 3-6 stands out for some devices, and it’s likely that this is due to discrepancies in the NNAPI drivers which don’t fully accelerate things on the hardware for the S10, Mi9 and G8.
AIBenchmark 3 - NNAPI FP16
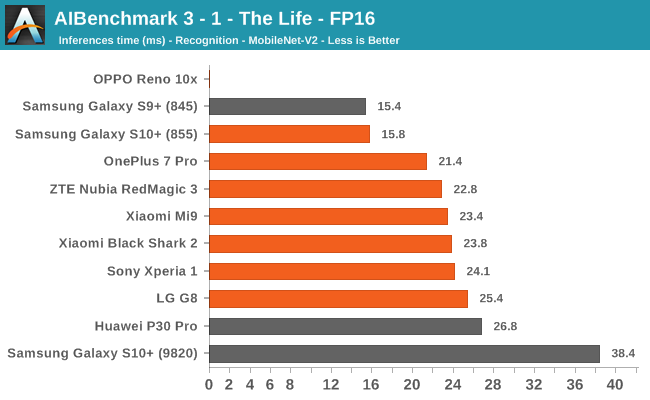
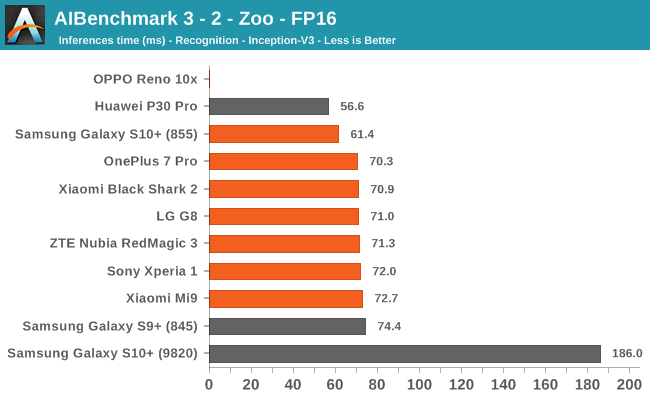
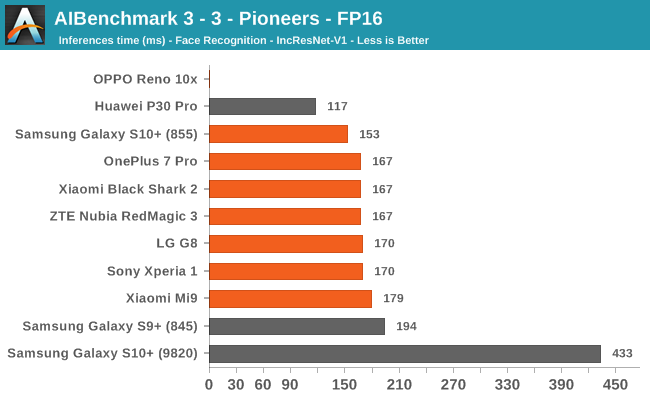
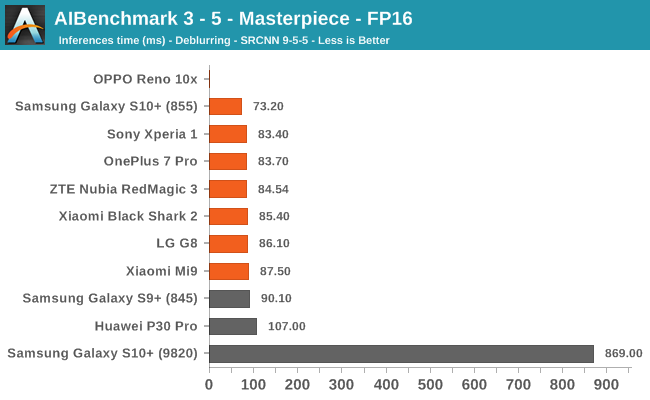
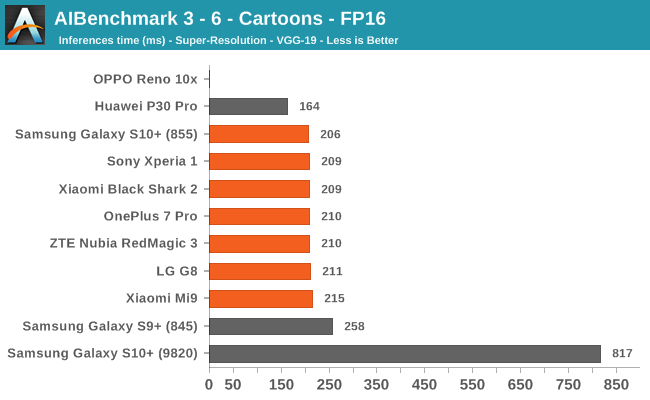
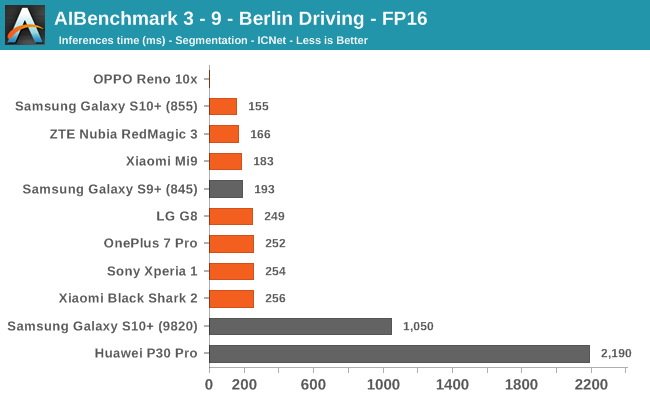
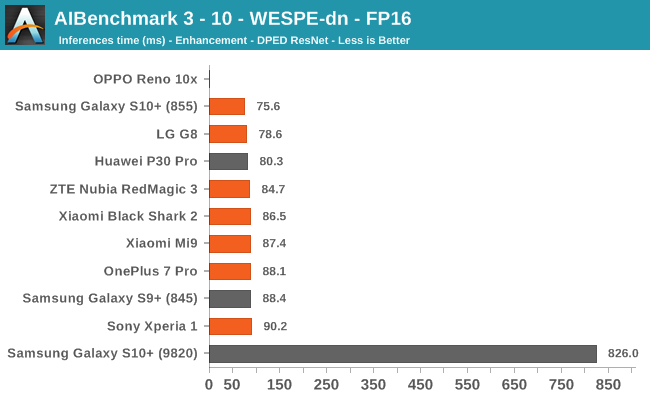
FP16 performance is again quite even across the board, with the difference coming down to DVFS and scheduler responsiveness. Here the Snapdragon 855 competes neck-in-neck with the Kirin 980, winning some tests while losing others. It’s to be remembered that the Kirin 980’s NPU doesn’t support INT8 acceleration at this time, and that’s why it shows up better in the FP16 benchmarks.
AIBenchmark 3 - NNAPI FP32
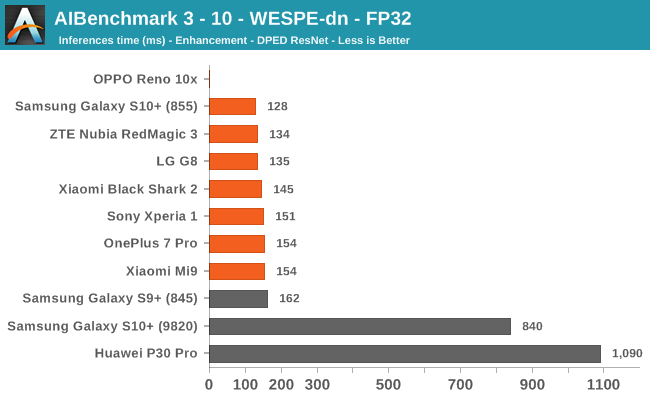
Finally, on the FP32 benchmark, Qualcomm accelerates these workloads on the GPU and is far ahead of the competition, which either have lacking GPU drivers or have to fall back to CPU acceleration.








47 Comments
View All Comments
yeeeeman - Thursday, September 5, 2019 - link
Andrei, this is nice, but we could guesstimate how an 855+ will behave.We really want to see Exynos 9825 since that is harder to estimate.
Andrei Frumusanu - Thursday, September 5, 2019 - link
I don't have the 9825/Note10 yet, we'll have to buy one. Currently this won't happen till maybe October as it's going to be busy with other stuff the next few weeks.LarsBolender - Thursday, September 5, 2019 - link
But you are going to review the 9825, are you?rocketman122 - Thursday, September 5, 2019 - link
all I care about is if the camera is great, and the op7 is garbage as has been all the others before it.FunBunny2 - Thursday, September 5, 2019 - link
"all I care about is if the camera is great"and, how many phone companies make the cameras? it is, of course, just a matter of buying off-the-shelf from other vendors.
IUU - Friday, September 6, 2019 - link
Lol! Couldn't care any less about the camera! But each to his own.cha0z_ - Monday, September 9, 2019 - link
It would make an interesting read to see the benefits going from 8nm to 7nm, but from what is known - the benefits are super slim to even justify doing that in the first place for something different than "beta test" the 7nm for the next year SOC.There are more interesting things that comes like the A13 SOC and the next kirin.
FunBunny2 - Thursday, September 5, 2019 - link
"all I care about is if the camera is great"and, how many phone companies make the cameras? it is, of course, just a matter of buying off-the-shelf from other vendors.
philehidiot - Saturday, September 7, 2019 - link
I look at these charts and I get angrier and angrier about Samsung forcing me into Exynos when the performance (and other subsystems) are really quite inferior. It's marketed as one product but it's two very different phones. I compare this to motorbikes as that's my thing. A 1000cc Fireblade is NOT the same bike as a 650CC version. They are similar in looks and similar in purpose but they handle and perform differently and are worth different amounts because of this. I, personally, would be absolutely fine with a 650cc version as it would suit my riding better. I would NOT be fine with someone selling me a "Fireblade" and not specifying in the advert what model it is and trying to sell me a 650cc as if it was the same value as a 1000cc. Both models are marketed as different bikes with one called the CBR1000RR and the other the CBR650R. Just because they look similar and share many similar components does not mean they are the same machine when the core elements are different. Both have excessive performance for the road - more than you'll ever be able to apply and so arguing that the phones are both satisfactory for the market is missing the point.Samsung need to recognise they can not go selling an inferior phone under the same name as another model and using the same marketing as if they both have the same value. And if you're ever wondering, just ask yourself this - if you could have either a Snapdragon or an Exynos model and they'd both work the same on the networks you use, etc.... would you really choose the slower one for the same money? No, you'd go for the faster one with the better DSP, better imaging, better sound quality, etc.
My other concern is that, whilst these are both adequate now, I might want my phone to last longer than the usual 2-3 years. What if I want 5? Mine is an S8 and it's already showing signs of slowing down as software requirements increase. So if you start off with a faster phone, logically it will likely make a difference towards the latter end of its life. So I buy an inferior phone which also has a shorter useful life and I'm expected to value it the same as the other model?
Samsung, please tell your marketing department to kindly piss off. The bunch of raging arse parsnips.
s.yu - Sunday, September 8, 2019 - link
I don't get your point, they're not for the same money, not even in the same range as twice I bought an SK variant Samsung for ~30% less than Mainland China's.They also have different code names. Note 10+ for example, directly from GSMA: Versions: SM-N975F (Europe); SM-N975F/DS (Global); SM-N975U (USA); SM-N975U1 (USA unlocked); SM-N975W (Canada); SM-N9750/DS (LATAM, Brazil, China); SM-N975N (South Korea)