Hot Chips 2018: Fujitsu's A64FX Arm Core Live Blog
by Dr. Ian Cutress on August 21, 2018 8:25 PM EST- Posted in
- CPUs
- Arm
- Hot Chips
- HPC
- Trade Shows
- Fujitsu
- Enterprise CPUs
- ARMv8
- Live Blog
- AFX64

08:30PM EDT - Remember back when Arm announced Scalable Vector Extensions? Well Fujitsu has made an Arm CPU that uses it with a 512-bit width. The presentation looks super interesting, so follow along with our live blog. The talk is set to start at 5:30pm PT / 12:30am UTC.

08:32PM EDT - Last time we were here, had a 3-min presentation about Post-K
08:32PM EDT - Called A64FX

08:32PM EDT - First chip to use Arm SVE
08:32PM EDT - Scalable Vector Extensions
08:33PM EDT - New microarch maximises SVE perf
08:33PM EDT - Fujitsu has been making processors for 60 years

08:34PM EDT - SPARC? Remember that?
08:34PM EDT - UNIX, HPC, Mainframe, now HPC + AI
08:34PM EDT - New CPU inherits DNA from Fujitsu

08:34PM EDT - Reliability, speed, flexibility, high perf/watt
08:34PM EDT - end up with CPU w/ extremely high throughput
08:35PM EDT - low power
08:35PM EDT - (A64FX doesn't mean Athlon 64, FX)
08:35PM EDT - Optimized for massively parallel
08:35PM EDT - Four features
08:35PM EDT - Perf: FP64 through to INT8
08:36PM EDT - Throughput: 512-bit SIMD x 2 pipes/core, HBM2, 48-cores, Tofu interconnect

08:36PM EDT - Efficiency: GEMM and Triad perf
08:37PM EDT - Standards: Arm v8.2 + SVE + SBSA level 3 (Server Base System Architecture)
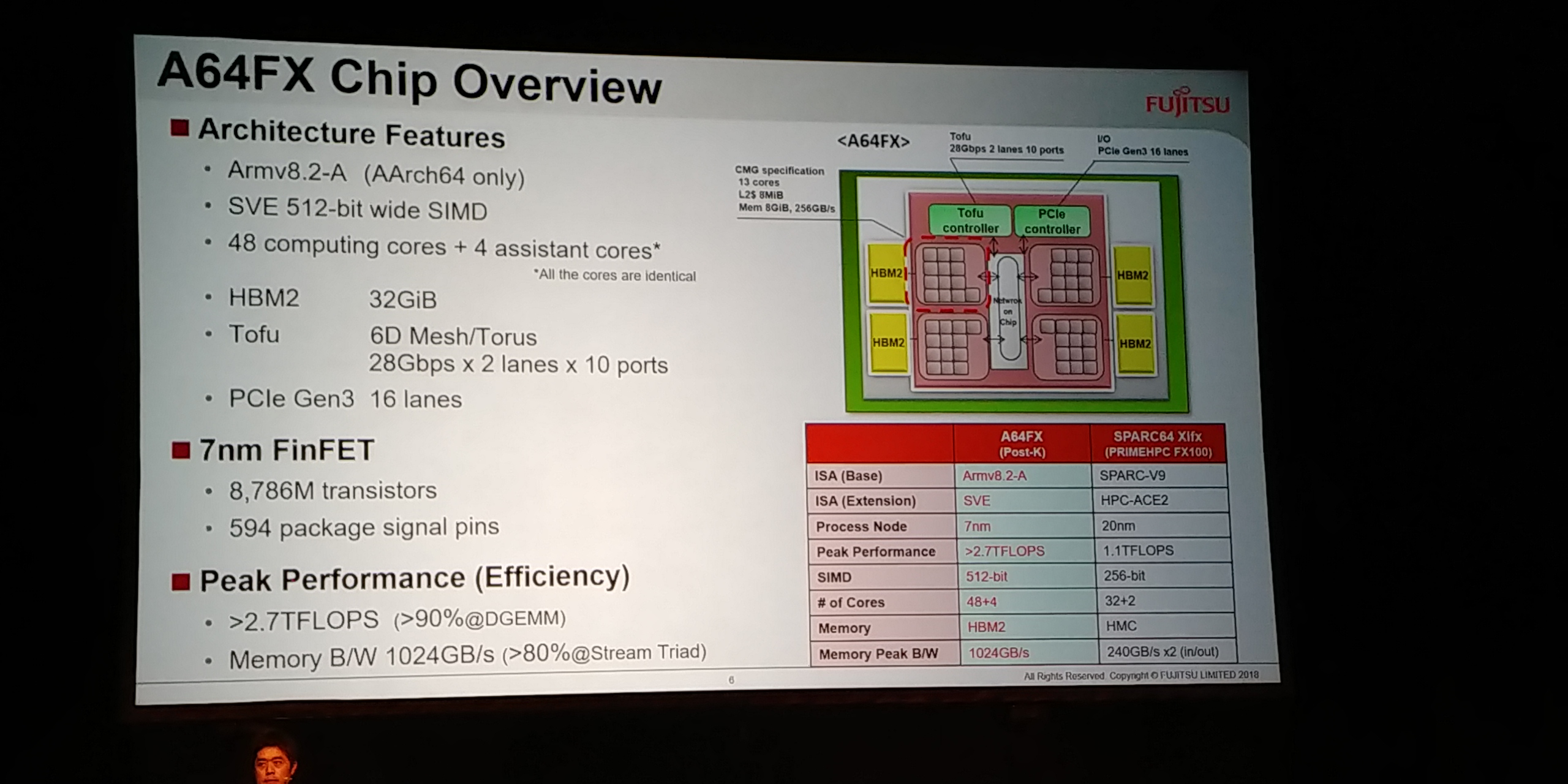
08:37PM EDT - AArch64 only, no 32
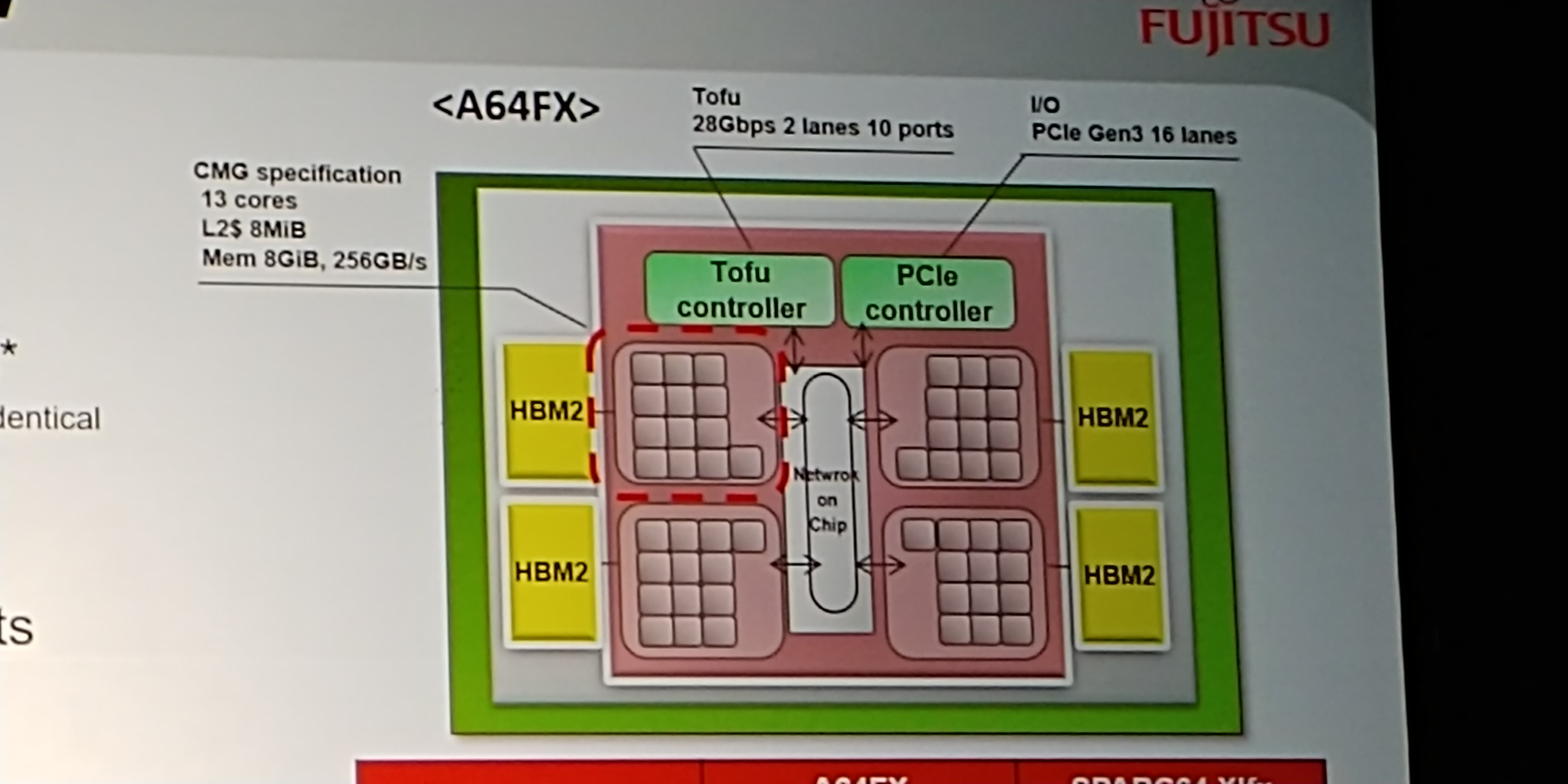
08:37PM EDT - 48 computing cores and 4 identical assistant cores
08:37PM EDT - 32GiB HBM2
08:38PM EDT - 6D Mesh - 28 Gbps x 2 lanes x 10 ports
08:38PM EDT - PCIe 3.0 x16
08:38PM EDT - Built on 7nm FinFET
08:38PM EDT - 8.786B transistors, but only 594 pin
08:38PM EDT - 2.7 TFLOPS
08:38PM EDT - 1TB/s memory bandwidth
08:39PM EDT - ISA feature support
08:39PM EDT - Optimized SVE for wide range of applications
08:39PM EDT - INT8 Dot Product
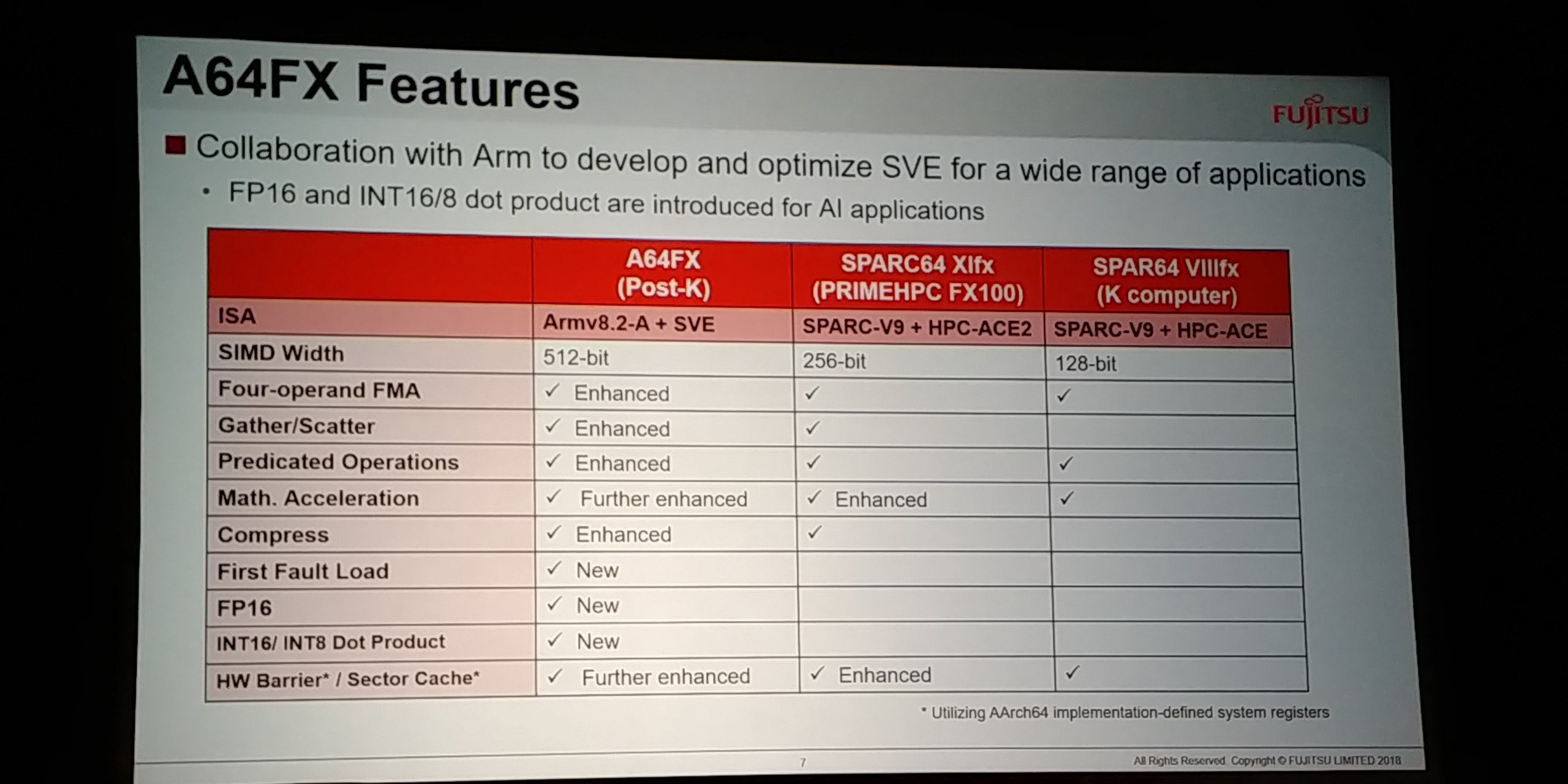
08:39PM EDT - Enhanced compression
08:39PM EDT - AI applications
08:40PM EDT - HW Barrier and Sector cache - implementation defined system registers from AArch64
08:40PM EDT - Enahnced blocks in chip
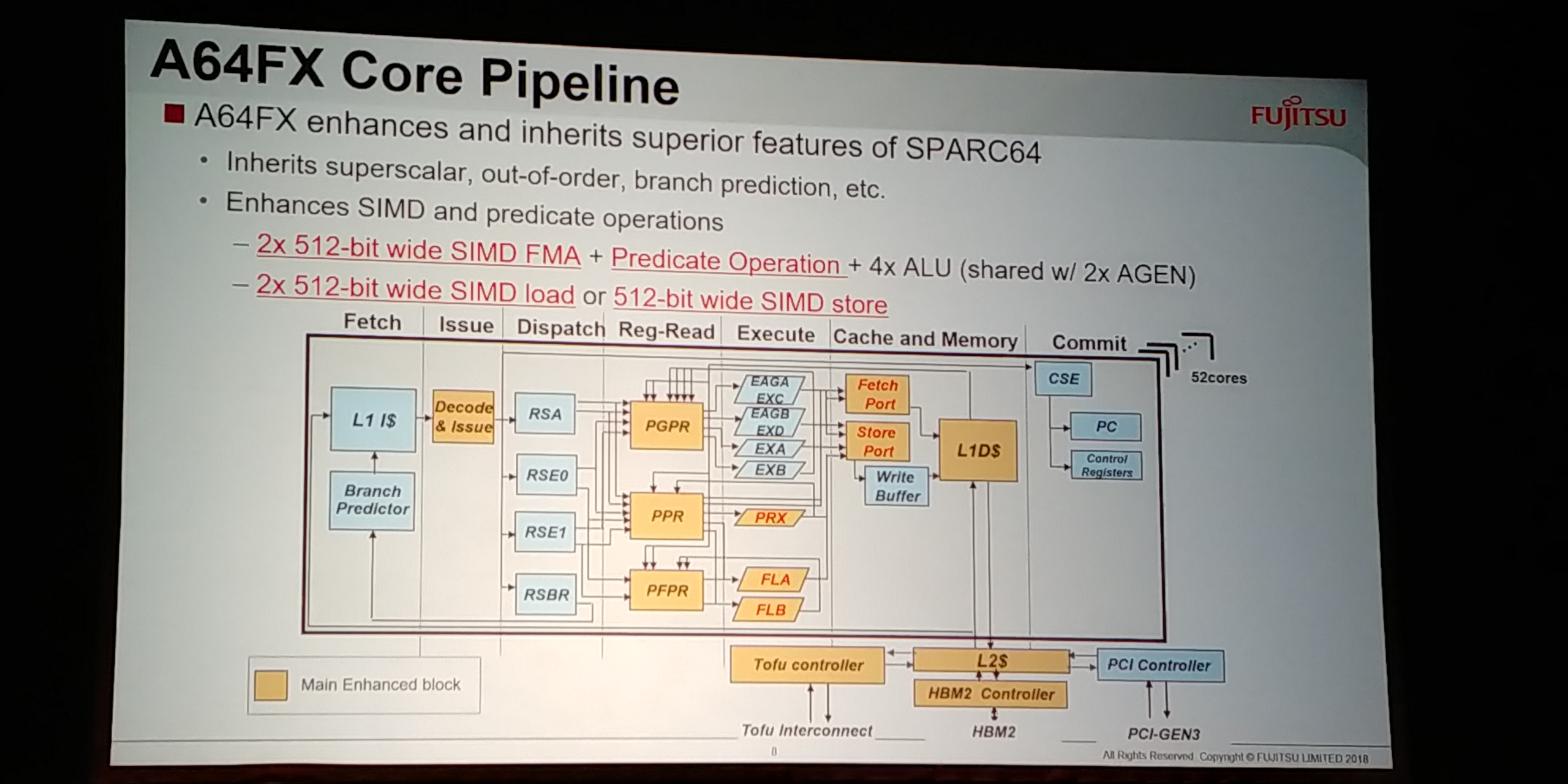
08:40PM EDT - Predicated operations dedicated pipe
08:41PM EDT - SVE has limitation on operands - FMA equivalent requires destructive 3-operand FMA3

08:41PM EDT - MOVPRFX instruction
08:41PM EDT - hides overhead of main pipelin
08:42PM EDT - 21.6 TOPS for INT8 dot product
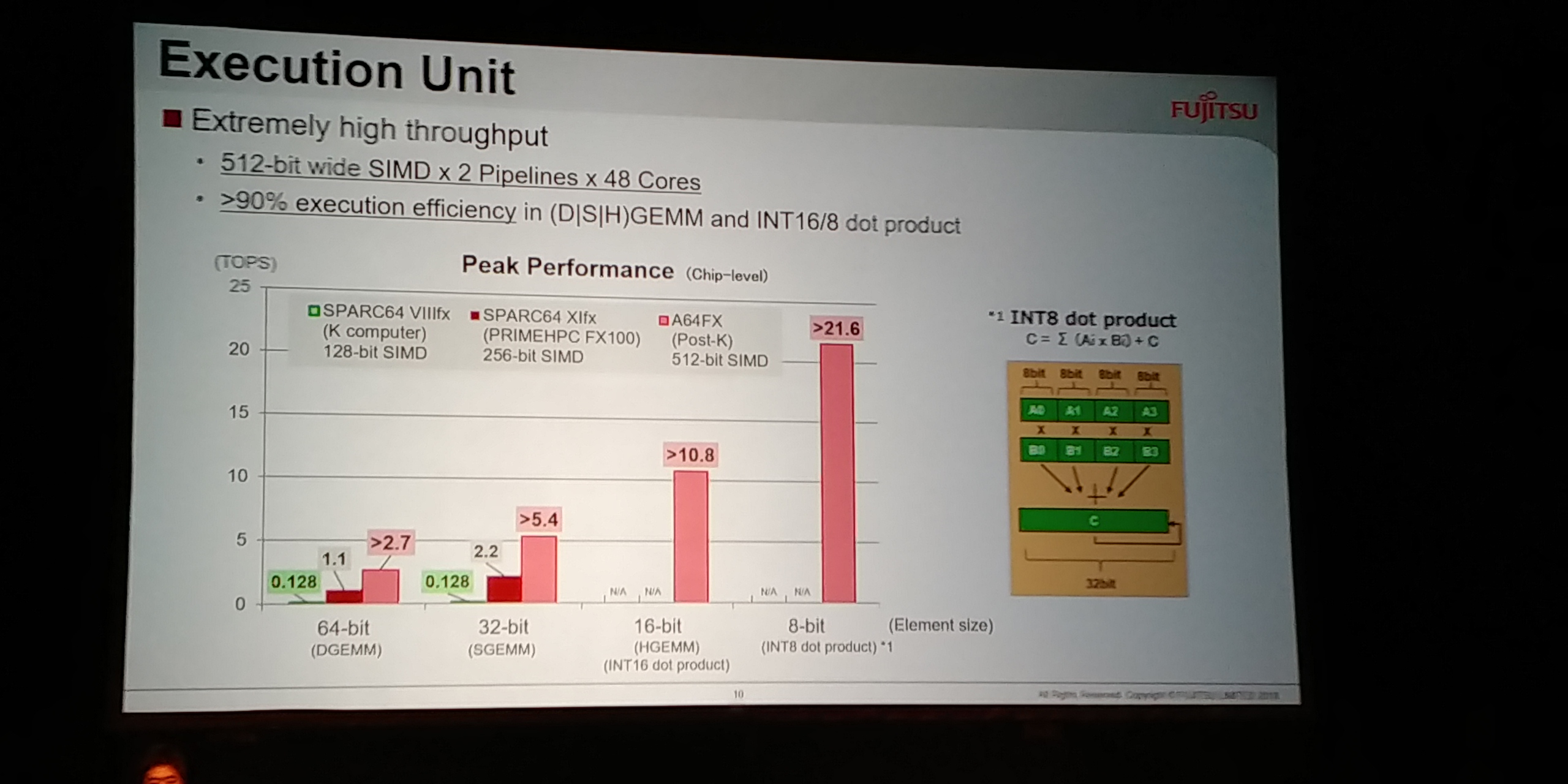
08:42PM EDT - 90% execution efficiency
08:42PM EDT - Still 2x in 64-bit DGEMM over SPARC64 PrimeHPC FX100
08:43PM EDT - Almost 20x the K comp in DGEMM
08:43PM EDT - L1 cache is key to design for 512-bit SIMD
08:43PM EDT - Combined Gather mechanism to increase throughput
08:44PM EDT - Combined Gather enables return up to two consecutive elements in a 128-byte aligned block

08:44PM EDT - Throughput per core is 32 bytes/cycle
08:44PM EDT - Full chip is Divided into four memory groups
08:45PM EDT - One CMG is 13 cores, an L2 cache, and a memory controller
08:45PM EDT - One core handles Daemon/IO

08:45PM EDT - Cache coherency by ccNUMA with on-chip directory
08:45PM EDT - X-bar connection for L2 cache efficiency
08:45PM EDT - Process binding ensures scaling
08:45PM EDT - Wide Ring Bus for IO across whole chip
08:46PM EDT - Bandwidth in cache and memory is key

08:46PM EDT - Out-of-order mechanisms in cores, caches, and IMCs
08:46PM EDT - L1 cache at 11.0 TB/s
08:46PM EDT - L2 cache is 3.6 TB/s
08:47PM EDT - Normalized compared to previous processor, perf is 2x across wide range of workloads
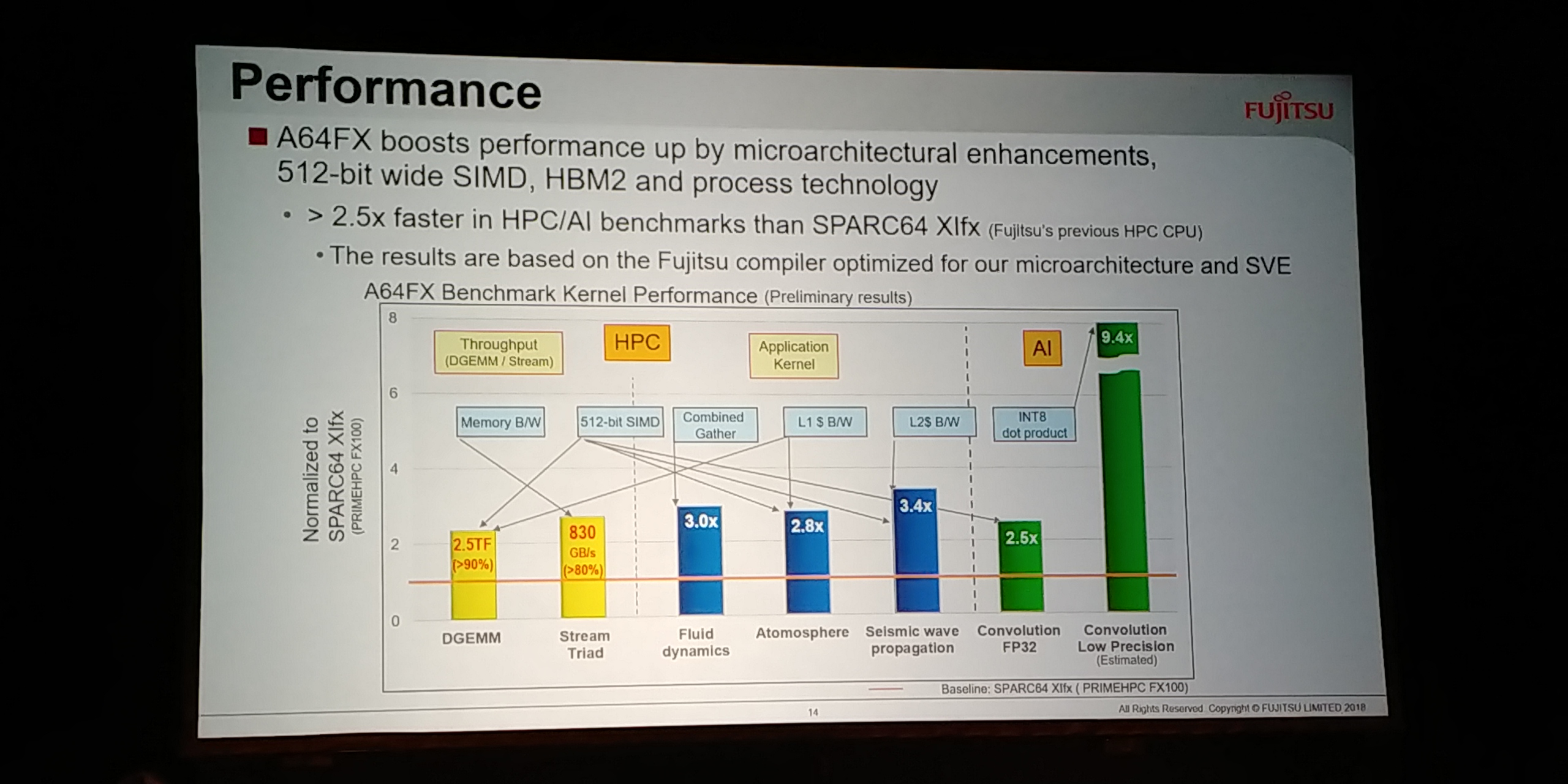
08:48PM EDT - For AI, convolution low precision is 9.4x using INT8 dot product
08:48PM EDT - Each chip has energy monitor in msec
08:49PM EDT - Each core has energy analyzer in nanosec
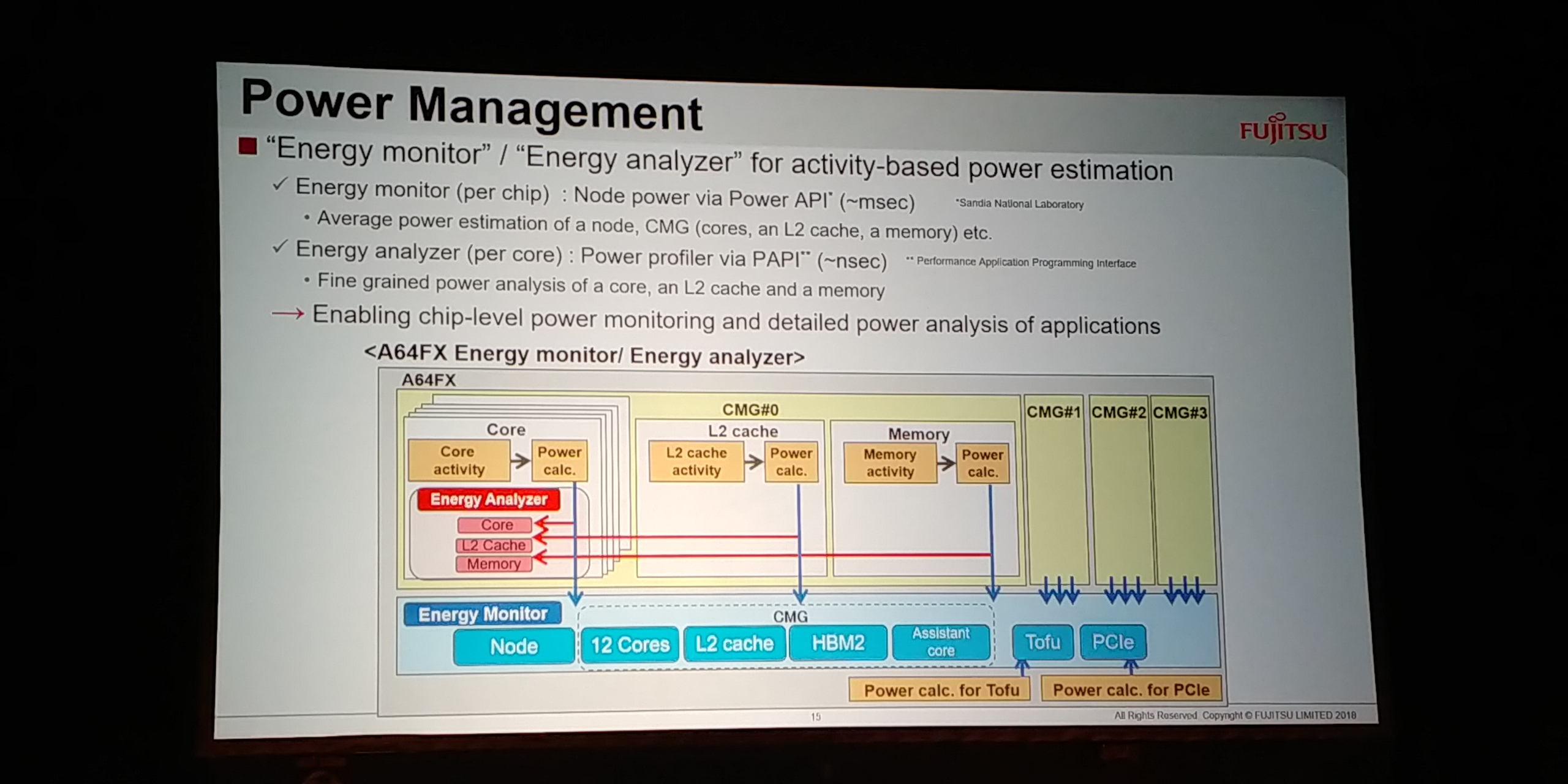
08:49PM EDT - Fine grained power analysis of a core, an L2 cache and memory
08:49PM EDT - Power Knob for optimization
08:49PM EDT - Can change hardware config for power
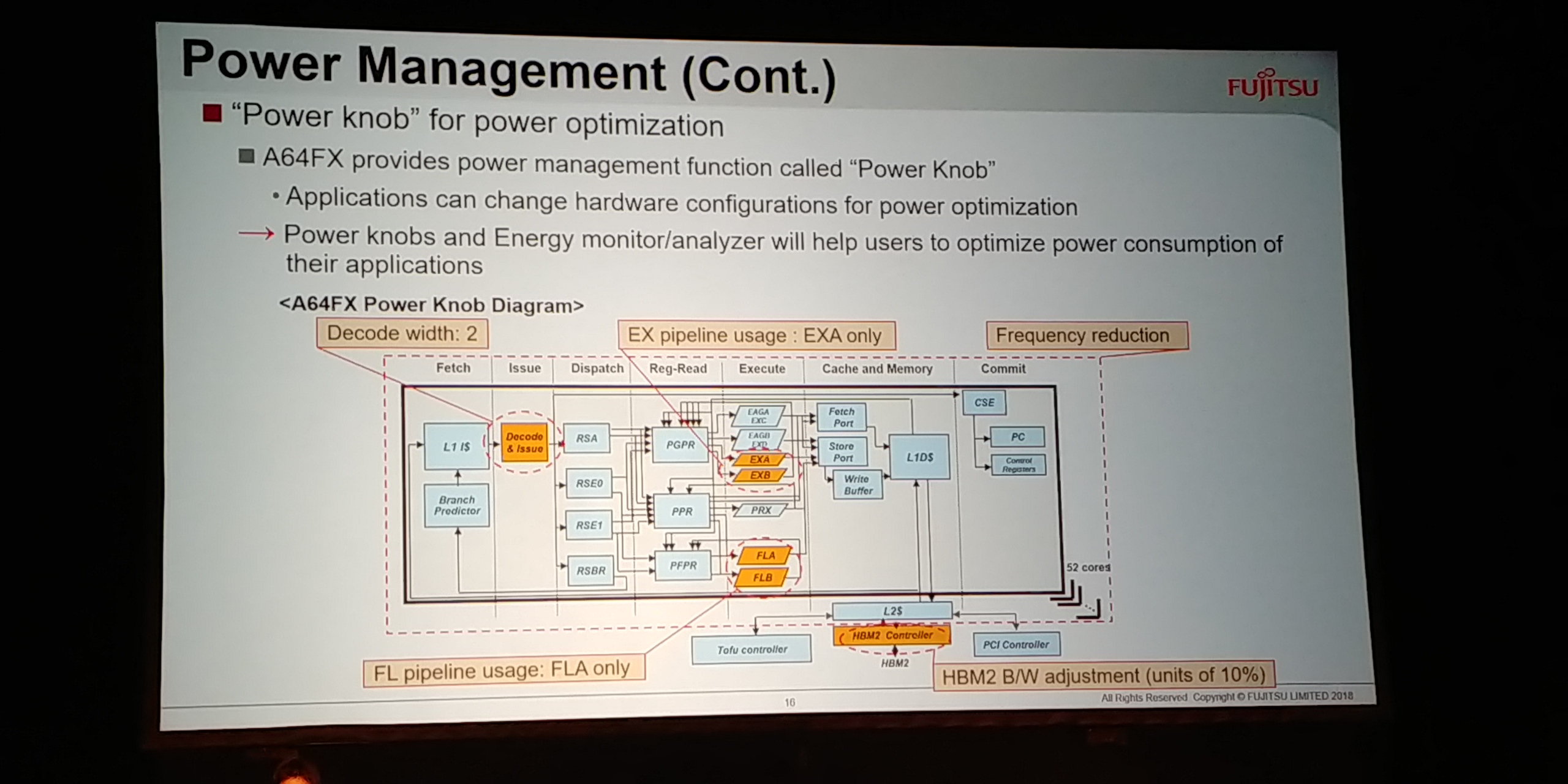
08:50PM EDT - Change decode width, floating point pipeline, and general frequency reduction
08:50PM EDT - Extensive RAS
08:50PM EDT - ECC on all caches
08:50PM EDT - Parity cehc on execution units
08:50PM EDT - 128400 error checkers

08:50PM EDT - Parity Check* on execution units

08:51PM EDT - Hardware instruction retry
08:52PM EDT - Software stacks developed by RIKEN and Fujitsu

08:52PM EDT - Will continue to use Arm in the future
08:52PM EDT - Work with partners

08:53PM EDT - Q&A time
08:54PM EDT - Q: When can you reach exascale? A: The Post-K system will be available in 2021. 100x perf from K-comp. But exa-scale not answerable
08:55PM EDT - Q: nanosecond level power monitoring - what techniques do you use? A: Activity based on coefficient based on operations
08:56PM EDT - Q: Support 64-bit FP, not 128-bit? A: No.
08:59PM EDT - That's a wrap. Next talk is on the NEC Vector processor: https://www.anandtech.com/show/13259/hot-chips-2018-nec-vector-processor-live-blog








9 Comments
View All Comments
eastcoast_pete - Wednesday, August 22, 2018 - link
Thanks Ian! One immediate takeaway: Interesting design, but why only 16 PCIe Gen3 lanes? That can really limit the A64fx's usefulness. Any comments from Fujitsu, and your thoughts?TeXWiller - Wednesday, August 22, 2018 - link
My guess would be that the PCIe bus is mostly used for burst buffers (non-volatile fast storage) and system management (networking) and most of the magic happens through the Tofu in the very large system these processors are part of.eastcoast_pete - Thursday, August 23, 2018 - link
Hi TeXWiller, that was my initial thought, too. But, why limit this chip "only" to supercomputer-type machines? They did show their new chip as being superior to their SPARC64 in their talk, which is why I found this confusing, and Fujitsu needs a follow-up to their Sparc64 line ASAP, unless they have given up on the server category. However, for server use, 16 Gen3 PCIe lanes won't cut it by a mile. The A64fx design could fit the bill, and the ability to run 512 bit SIMD extensions (vs. 256 bit for current gen Sparc64) would add a strong performance boost (absolute and perf/Wh) for some key server-run applications.TeXWiller - Thursday, August 23, 2018 - link
They did the same thing with the K-computer: some of the HPC features that were useful for the server version were integrated into it. As to SPARC -> ARM transition, the post-K project has to show its performance and reliability, both in terms of hardware and software first. By that time the server version can be integrated with any next generation IO that is needed. That is my relatively humble opinion. ;)SarahKerrigan - Saturday, August 25, 2018 - link
They compare it to SPARC64fx, which is also supercompute-only and highly limited on the peripheral side. SPARC64 XIfx also has exactly 16 PCIe 3 lanes, just like A64FX does.SPARC64 and SPARC64fx are not the same - SPARC64 are commercial systems running Solaris, with multithreading, SMP, and support for more than the 32GB per node of RAM present in the A64FX and SPARC64 XIfx. SPARC64 XIfx is SMP-less (multi-node is done via Tofu), has no multithreading, and has a significantly different cache configuration from SPARC64 XII (or X.)
There's a new SPARC64 on the roadmap, although I'm skeptical there will be another one after, given the decline in the commercial UNIX market.
Santoval - Wednesday, August 22, 2018 - link
Are they actually going to make a supercomputer in 2021 with no PCIe 4.0 and HBM3 memory? By that time both will certainly be the norm (with the final spec of PCIe 5.0 already released), so it would be very strange.SquarePeg - Wednesday, August 22, 2018 - link
08:35PM EDT - (A64FX doesn't mean Athlon 64, FX)My immediate thought when I read the title was "how the fook are they going to use that branding". Because that's what I was reminded of right away.
Nehemoth - Thursday, August 23, 2018 - link
I guess that the intended target for the product are very different from the one of AMD Athlon :)x0 - Friday, October 30, 2020 - link
My English is not perfect.This is my favourite chip. I wish a laptop workstation with Fujitsu A64FX, with mainframe RAS.
Does the 32 Gib HBM2 has ECC? And address/control parity?
Does will be desktop versions? Workstation, Laptop workstation: USB C 4.0, USB A 3.1, 10-100 Gbit/s ethernet, DisplayPort, HDMI, DVI, 15 pin mini D-Sub, audio jack and digital connectors, PCI-Express 5.0/6.0, M.2, U.2, SAS, SATA, SIM, wifi, etc.