The AMD Threadripper 2990WX 32-Core and 2950X 16-Core Review
by Dr. Ian Cutress on August 13, 2018 9:00 AM ESTCore to Core to Core: Design Trade Offs
AMD’s approach to these big processors is to take a small repeating unit, such as the 4-core complex or 8-core silicon die (which has two complexes on it), and put several on a package to get the required number of cores and threads. The upside of this is that there are a lot of replicated units, such as memory channels and PCIe lanes. The downside is how cores and memory have to talk to each other.
In a standard monolithic (single) silicon design, each core is on an internal interconnect to the memory controller and can hop out to main memory with a low latency. The speed between the cores and the memory controller is usually low, and the routing mechanism (a ring or a mesh) can determine bandwidth or latency or scalability, and the final performance is usually a trade-off.
In a multiple silicon design, where each die has access to specific memory locally but also has access to other memory via a jump, we then come across a non-uniform memory architecture, known in the business as a NUMA design. Performance can be limited by this abnormal memory delay, and software has to be ‘NUMA-aware’ in order to maximize both the latency and the bandwidth. The extra jumps between silicon and memory controllers also burn some power.
We saw this before with the first generation Threadripper: having two active silicon dies on the package meant that there was a hop if the data required was in the memory attached to the other silicon. With the second generation Threadripper, it gets a lot more complex.
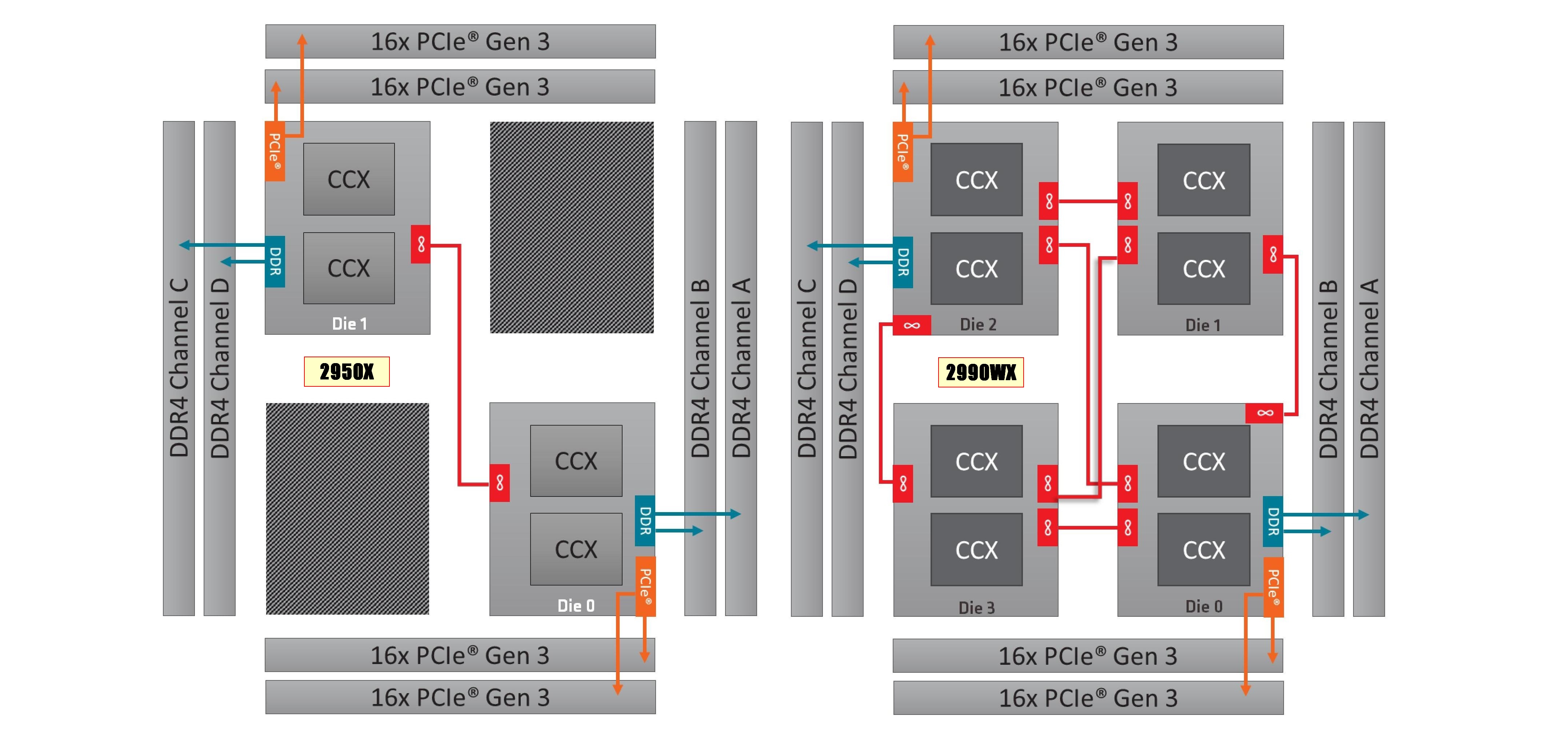
On the left is the 1950X/2950X design, with two active silicon dies. Each die has direct access to 32 PCIe lanes and two memory channels each, which when combined gives 60/64 PCIe lanes and four memory channels. The cores that have direct access to the memory/PCIe connected to the die are faster than going off-die.
For the 2990WX and 2970WX, the two ‘inactive’ dies are now enabled, but do not have extra access to memory or PCIe. For these cores, there is no ‘local’ memory or connectivity: every access to main memory requires an extra hop. There is also extra die-to-die interconnects using AMD’s Infinity Fabric (IF), which consumes power.
The reason that these extra cores do not have direct access is down to the platform: the TR4 platform for the Threadripper processors is set at quad-channel memory and 60 PCIe lanes. If the other two dies had their memory and PCIe enabled, it would require new motherboards and memory arrangements.
Users might ask, well can we not change it so each silicon die has one memory channel, and one set of 16 PCIe lanes? The answer is that yes, this change could occur. However the platform is somewhat locked in how the pins and traces are managed on the socket and motherboards. The firmware is expecting two memory channels per die, and also for electrical and power reasons, the current motherboards on the market are not set up in this way. This is going to be an important point when get into the performance in the review, so keep this in mind.
It is worth noting that this new second generation of Threadripper and AMD’s server platform, EPYC, are cousins. They are both built from the same package layout and socket, but EPYC has all the memory channels (eight) and all the PCIe lanes (128) enabled:
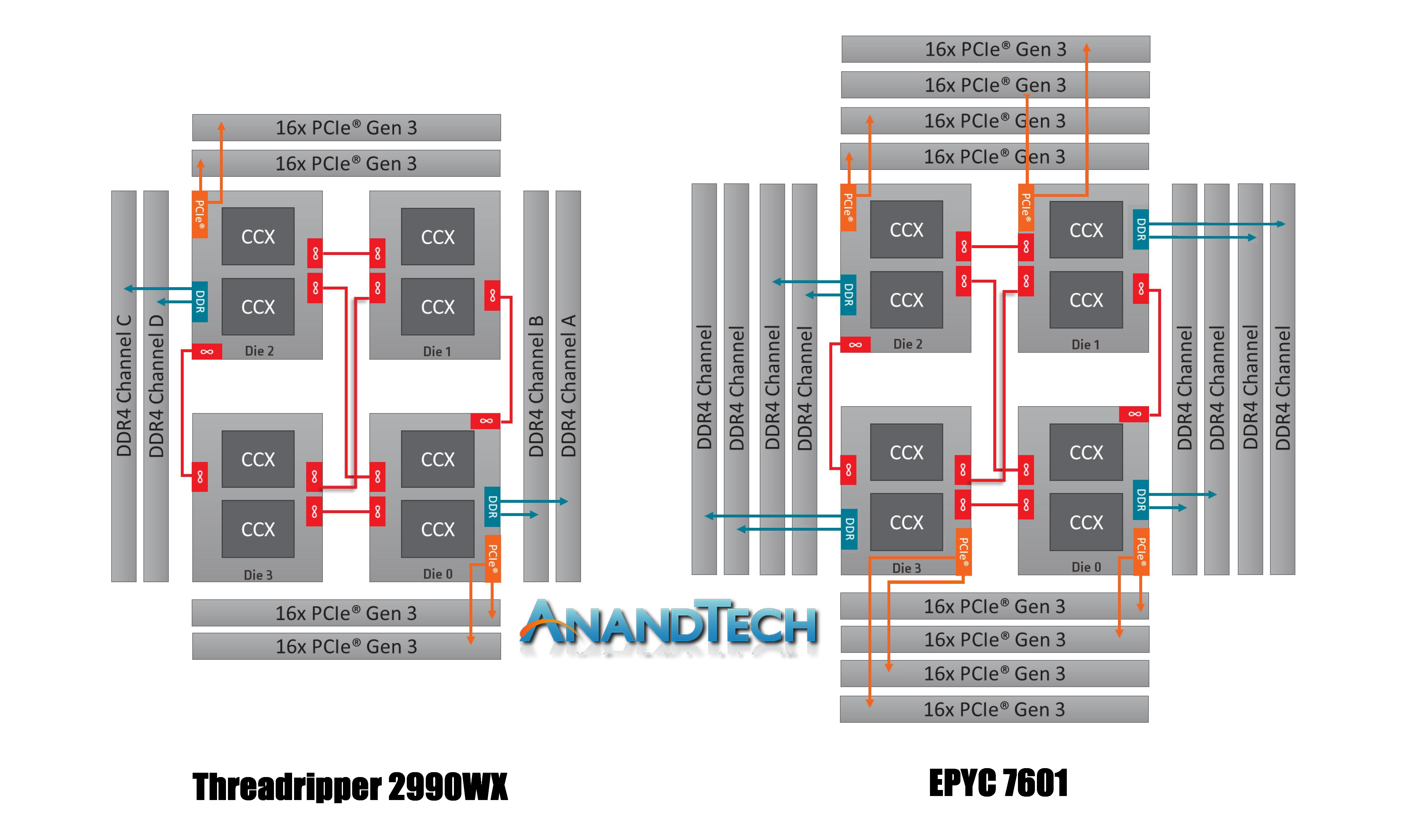
Where Threadripper 2 falls down on having some cores without direct access to memory, EPYC has direct memory available everywhere. This has the downside of requiring more power, but it offers a more homogenous core-to-core traffic layout.
Going back to Threadripper 2, it is important to understand how the chip is going to be loaded. We confirmed this with AMD, but for the most part the scheduler will load up the cores that are directly attached to memory first, before using the other cores. What happens is that each core has a priority weighting, based on performance, thermals, and power – the ones closest to memory get a higher priority, however as those fill up, the cores nearby get demoted due to thermal inefficiencies. This means that while the CPU will likely fill up the cores close to memory first, it will not be a simple case of filling up all of those cores first – the system may get to 12-14 cores loaded before going out to the two new bits of silicon.








171 Comments
View All Comments
ibnmadhi - Monday, August 13, 2018 - link
It's over, Intel is finished.milkod2001 - Monday, August 13, 2018 - link
Unfortunately not even close. Intel was dominating for last decade or so. Now when AMD is back in game, many will consider AMD but most will still get Intel instead. Damage was done.It took forever to AMD to recover from being useless and will take at least 5 years till it will get some serious market share. Better late than never though...tipoo - Monday, August 13, 2018 - link
It's not imminent, but Intel sure seems set for a gradual decline. It's hard to eke out IPC wins these days so it'll be hard to shake AMD off per-core, they no longer have a massive process lead to lead on core count with their margins either, and ARM is also chipping away at the bottom.Intel will probably be a vampire that lives another hundred years, but it'll go from the 900lb gorilla to one on a decent diet.
ACE76 - Monday, August 13, 2018 - link
AMD retail sales are equal to Intel now...and they are starting to make a noticeable dent in the server market as well...it won't take 5 years for them to be on top...if Ryzen 2 delivers a 25% increase in performance, they will topple Intel in 2019/2020HStewart - Monday, August 13, 2018 - link
"AMD retail sales are equal to Intel now"Desktop maybe - but that is minimal market.
monglerbongler - Monday, August 13, 2018 - link
Pretty much this.No one really cares about workstation/prosumer/gaming PC market. Its almost certainly the smallest measurable segment of the industry.
As far as these companies' business models are concerned:
Data center/server/cluster > OEM consumer (dell, hp, microsoft, apple, asus, toshiba, etc.) > random categories like industrial or compact PCs used in hospitals and places like that > Workstation/prosumer/gaming
AMD's entire strategy is to desperately push as hard as they can into the bulwark of Intel's cloud/server/data center dominance.
Though, to be completely honest, for that segment they really only offer pure core count and PCIe as benefits. Sure they have lots of memory channels, but server/data center and cluster are already moving toward the future of storage/memory fusion (eg Optane), so that entire traditional design may start to change radically soon.
All important: Performance per unit of area inside of a box, and performance per watt? Not the greatest.
That is exceptionally important for small companies that buy cooling from the power grid (air conditioning). If you are a big company in Washington and buy your cooling via river water, you might have to invest in upgrades to your cooling system.
Beyond all that the Epyc chips are so freaking massive that they can literally restrict the ability to design 2 slot server configuration motherboards that also have to house additional compute hardware (eg GPGPU or FPGA boards). I laugh at the prospect of a 4 slot epyc motherboard. The thing will be the size of a goddamn desk. Literally a "desktop" sized motherboard.
If you cant figure it out, its obvious:
Everything except for the last category involves massive years-spanning contracts for massive orders of hundreds of thousands or millions of individual components.
You can't bet hundreds of millions or billions in R&D, plus the years-spanning billion dollar contracts with Global Foundries (AMD) or the tooling required to upgrade and maintain equipment (Intel) on the vagaries of consumers, small businesses that make workstations to order, that small fraction of people who buy workstations from OEMs, etc.
Even if you go to a place like Pixar studios or a game developer, most of the actual physical computers inside are regular, bone standard, consumer-level hardware PCs, not workstation level equipment. There certainly ARE workstations, but they are a minority of the capital equipment inside such places.
Ultimately that is why, despite all the press, despite sending out expensive test samples to Anandtech, despite flashy powerpoint presentations given by arbitrary VPs of engineering or CEOs, all of the workstation/Prosumer/gaming stuff is just low-binned server equipment.
because those are really the only 2 categories of products they make;
pure consumer, pure workstation. Everything else is just partially enabled/disabled variations on those 2 flavors.
Icehawk - Monday, August 13, 2018 - link
I was looking at some new boxes for work and our main vendors offer little if anything AMD either for server roles or desktop. Even if they did it's an uphill battle to push a "2nd tier" vendor (AMD is not but are perceived that way by some) to management.PixyMisa - Tuesday, August 14, 2018 - link
There aren't any 4-socket EPYC servers because the interconnect only allows for two sockets. The fact that it might be difficult to build such servers is irrelevant because it's impossible.leexgx - Thursday, August 16, 2018 - link
is more then 2 sockets needed when you have so many cores to play withRelic74 - Wednesday, August 29, 2018 - link
Actually there are, kind of, supermicro for example has created a 4 node server for the Epyc. Basically it's 4 computers in one server case but the performance is equal to that if not better than that of a hardware 4 socket server. Cool stuff, you should check it out. In fact, I think this is the way of the future and multi socket systems are on their way out as this solution provides more control over what CPU. As well as what the individual cores are doing and provides better power management as you can shut down individual nodes or put them in stand by where as server with 4 sockets/CPU's is basically always on.There is a really great white paper on the subject that came out of AMD, where the stated that they looked into creating a 4 socket CPU and motherboard capable of handling all of the PCI lanes needed, however it didn't make any sense for them to do so as there weren't any performance gains over the node solution.
In fact I believe we will see a resurrection of blade systems using AMD CPU's, especially now with all of the improvements that have been made with multi node cluster computing over the last few years.