Launching the #CPUOverload Project: Testing Every x86 Desktop Processor since 2010
by Dr. Ian Cutress on July 20, 2020 1:30 PM ESTCPU Tests: Synthetic
Most of the people in our industry have a love/hate relationship when it comes to synthetic tests. On the one hand, they’re often good for quick summaries of performance and are easy to use, but most of the time the tests aren’t related to any real software. Synthetic tests are often very good at burrowing down to a specific set of instructions and maximizing the performance out of those. Due to requests from a number of our readers, we have the following synthetic tests.
Linux OpenSSL Speed
In our last review, and on my twitter, I opined about potential new benchmarks for our suite. One of our readers reached out to me and stated that he was interested in looking at OpenSSL hashing rates in Linux. Luckily OpenSSL in Linux has a function called ‘speed’ that allows the user to determine how fast the system is for any given hashing algorithm, as well as signing and verifying messages.
OpenSSL offers a lot of algorithms to choose from, and based on a quick Twitter poll, we narrowed it down to the following:
- rsa2048 sign and rsa2048 verify
- sha256 at 8K block size
- md5 at 8K block size
For each of these tests, we run them in single thread and multithreaded mode.
To automate this test, Windows Subsystem for Linux is needed. For our last benchmark suite I scripted up enabling WSL with Ubuntu 18.04 on Windows in order to run SPEC, so that stays part of the suite (and actually now becomes the biggest pre-install of the suite).
OpenSSL speed has some commands to adjust the time of the test, however the way the script was managing it meant that it never seemed to work properly. However, the ability to adjust how many threads are in play does work, which is important for multithreaded testing.




This test produces a lot of graphs, so for full reviews I might keep the rsa2048 ones and just leave the sha256/md5 data in Bench.




The AMD CPUs do really well in the sha256 test due to native support for SHA256 instructions.
GeekBench 4: Link
As a common tool for cross-platform testing between mobile, PC, and Mac, GeekBench is an ultimate exercise in synthetic testing across a range of algorithms looking for peak throughput. Tests include encryption, compression, fast Fourier transform, memory operations, n-body physics, matrix operations, histogram manipulation, and HTML parsing.
I’m including this test due to popular demand, although the results do come across as overly synthetic, and a lot of users often put a lot of weight behind the test due to the fact that it is compiled across different platforms (although with different compilers). Technically GeekBench 5 exists, however we do not have a key for the pro version that allows for command line processing.
For reviews we are posting the overall single and multi-threaded results.

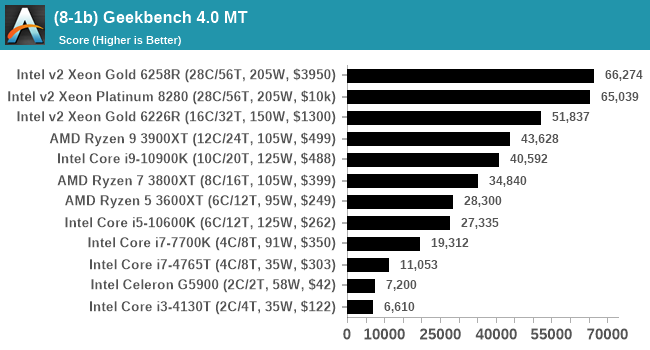
I have noticed that Geekbench 4 over Geekbench 5 does rely a lot on its memory subtests, which could play a factor if we have to test limited-access CPUs in different systems.
AIDA64 Memory Bandwidth: Link
Speaking of memory, one of the requests we have had is to showcase memory bandwidth. Lately AIDA64 has been doing some good work in providing automation access, so for this test I used the command line and some regex to extract the data from the JSON output. AIDA also provides screenshots of its testing windows as required.
For the most part, we expect CPUs of the same family with the same memory support to not differ that much – there will be minor differences based on the exact frequency of the time, or how the power budget gets moved around, or how many cores are being fed by the memory at one time.
LinX 0.9.5 LINPACK
One of the benchmarks I’ve been after for a while is just something that outputs a very simple GFLOPs FP64 number, or in the case of AI I’d like to get a value for TOPs at a given level of quantization (FP32/FP16/INT8 etc). The most popular tool for doing this on supercomputers is a form of LINPACK, however for consumer systems it’s a case of making sure that the software is optimized for each CPU.
LinX has been a popular interface for LINPACK on Windows for a number of years. However the last official version was 0.6.5, launched in 2015, before the latest Ryzen hardware came into being. HWTips in Korea has been updating LinX and has separated out into two versions, one for Intel and one for AMD, and both have reached version 0.9.5. Unfortunately the AMD version is still a work in progress, as it doesn’t work on Zen 2.
There does exist a program called Linpack Extreme 1.1.3, which claims to be updated to use the latest version of the Intel Math Kernel Libraries. It works great, however the way the interface has been designed means that it can’t be automated for our uses, so we can’t use it.
For LinX 0.9.5, there also is a difficulty of what parameters to put into LINPACK. The two main parameters are problem size and time – choose a problem size too small, and you won’t get peak performance. Choose it too large, and the calculation can go on for hours. To that end, we use the following algorithms as a compromise:
- Memory Use = Floor(1000 + 20*sqrt(threads)) MB
- Time = Floor(10+sqrt(threads)) minutes
For a 4 thread system, we use 1040 MB and run for 12 minutes.
For a 128 thread system, we use 1226 MB and run for 21 minutes.
We take the peak value of GFLOPs by the output as a result. Unfortunately the output doesn’t come out in a clean UTF-8 regular output, which means this is one result we have to read direct from the results file.

As we add in more CPUs, this graph should look more interesting. If a Zen2 version is deployed, we will adjust our script accordingly.








110 Comments
View All Comments
DiHydro - Monday, July 20, 2020 - link
This is epic. Thank you for doing this.DiHydro - Monday, July 20, 2020 - link
To add a note: I think the ~$300 CPU year-over-year performance would be an interesting metric to see. That price point seems to be pretty popular for enthusiasts, and seeing back 5-6 years how that performance has increased per dollar would be neat.bldr - Monday, July 20, 2020 - link
Agree!close - Monday, July 20, 2020 - link
It will be especially interesting to see those CPUs (the popular mainstream ones) tested now and compared to the numbers they got originally to see how much they lost with all the recent mitigations.close - Tuesday, July 21, 2020 - link
Oh, because I forgot previously, congratulations and good luck with the endeavor! I got exhausted only by reading about the work you're going to have to doFozzie - Monday, July 20, 2020 - link
Except keep in mind that adjusted for inflation $200 in the year 2000 is worth over $300 now.You'd either be making a chart of the increased value over time just due to inflation or in fact the every increasing value at the $300 price point due to the reduced value of the Dollar on top of whatever performance gains occurred.
biosstar - Friday, July 24, 2020 - link
You could also use the value of a dollar in a certain year (let's say 2020) and compare the processors in the inflation adjusted equal categories.PeterCollier - Monday, July 20, 2020 - link
What's the point of this Geekbench/Userbenchmark knockoff? I've never used AT's Bench tool. Especially not for smartphones, since the Bench tool is about 5 years out of date.BushLin - Monday, July 20, 2020 - link
A controlled environment across all tests is reason enough. Even if I don't agree with AT policy on what speed they allow RAM to operate, it is a fair comparison.Byte - Monday, July 20, 2020 - link
RAM is a really important topic. I think at this point in time, we can reasonable put almost maxed out ram for every platform. Like DDR3 can run at 2133, DDR4 we can run it at 3200 as prices are so close.It is like rating sports cars but all have Goodride tires on them.
A dodge viper was a widowmaker when it came out. Today with a good set of summers like PS4S or PZero, you will have a hard time slipping even if you tried.