Intel Unveils Meteor Lake Architecture: Intel 4 Heralds the Disaggregated Future of Mobile CPUs
by Gavin Bonshor on September 19, 2023 11:35 AM ESTSoC Tile, Part 2: NPU Adds a Physical AI Engine
The last major block on the SoC tile is a full-featured Neural Processing Unit (NPU), a first for Intel's client-focused processors. The NPU brings AI capabilities directly to the chip and is compatible with standardized program interfaces like OpenVINO. The architecture of the NPU itself is multi-engine in nature, which is comprised of two neural compute engines that can either collaborate on a single task or operate independently. This flexibility is crucial for diverse workloads and potentially benefits future workloads that haven't yet been optimized for AI situations or are in the process of being developed. Two primary components of these neural compute engines stand out: the Inference Pipeline and the SHAVE DSP.

The Inference Pipeline is primarily responsible for executing workloads in neural network execution. It minimizes data movement and focuses on fixed-function operations for tasks that require high computational power. The pipeline comprises a sizable array of Multiply Accumulate (MAC) units, an activation function block, and a data conversion block. In essence, the inference pipeline is a dedicated block optimized for ultra-dense matrix math.
The SHAVE DSP, or Streaming Hybrid Architecture Vector Engine, is designed specifically for AI applications and workloads. It has the capability to be pipelined along with the Inference Pipeline and the Direct Memory Access (DMA) engine, thereby enabling parallel computing on the NPU to improve overall performance. The DMA Engine is designed to efficiently manage data movement, contributing to the system's overall performance.
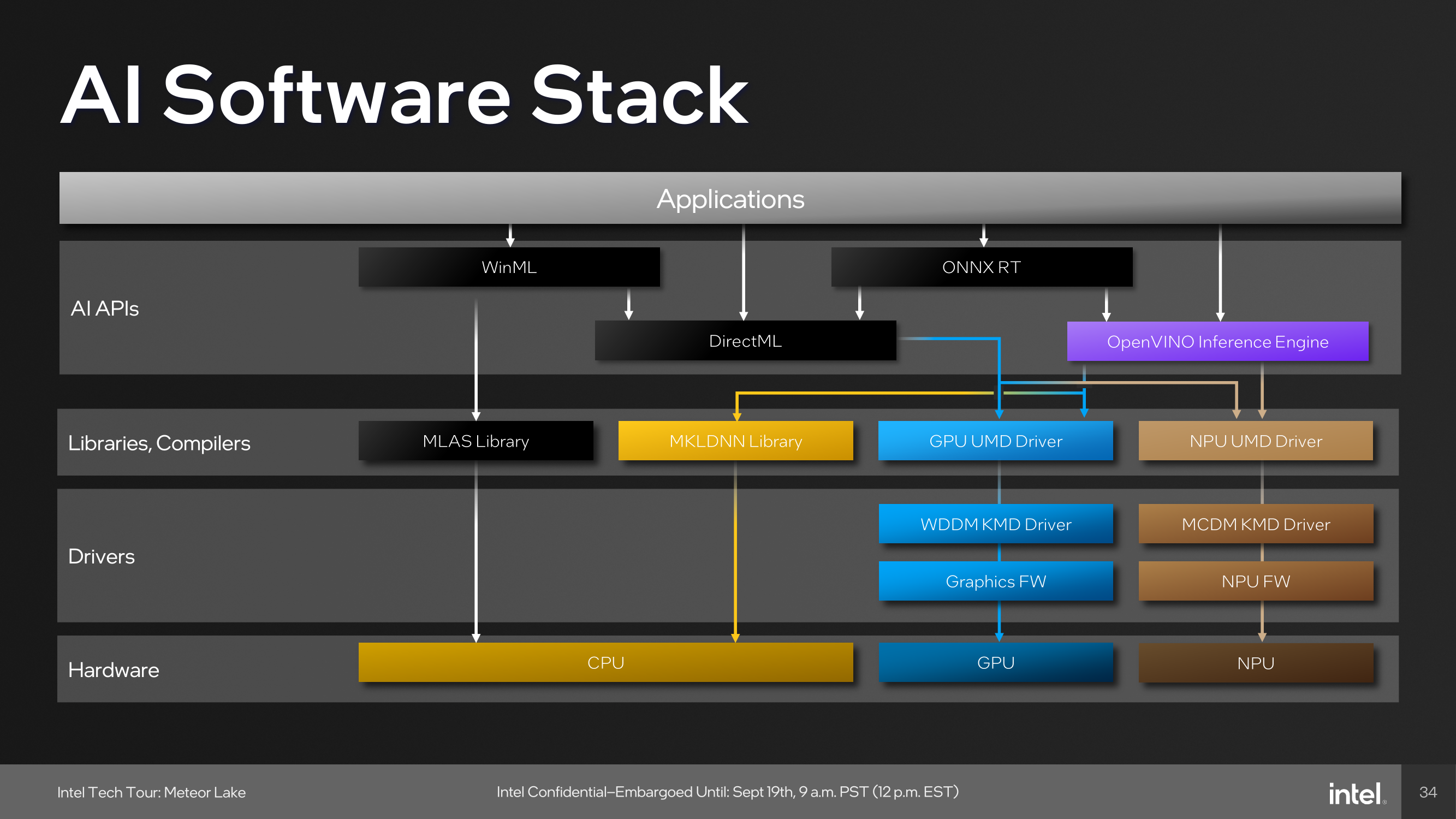
At the heart of device management, the NPU is designed to be fully compatible with Microsoft's new compute driver model, known as MCDM. This isn't merely a feature, but it's an optimized implementation with a strong emphasis on security. The Memory Management Unit (MMU) complements this by offering multi-context isolation and facilitates rapid and power-efficient transitions between different power states and workloads.

As part of building an ecosystem that can capitalize on Intel's NPU, they have been embracing developers with a number of tools. One of these is the open-source OpenVINO toolkit, which supports various models such as TensorFlow, PyTorch, and Caffe. Supported APIs include Windows Machine Learning (WinML), which also includes the DirectML component of the library, the ONNX Runtime accelerator, and OpenVINO.
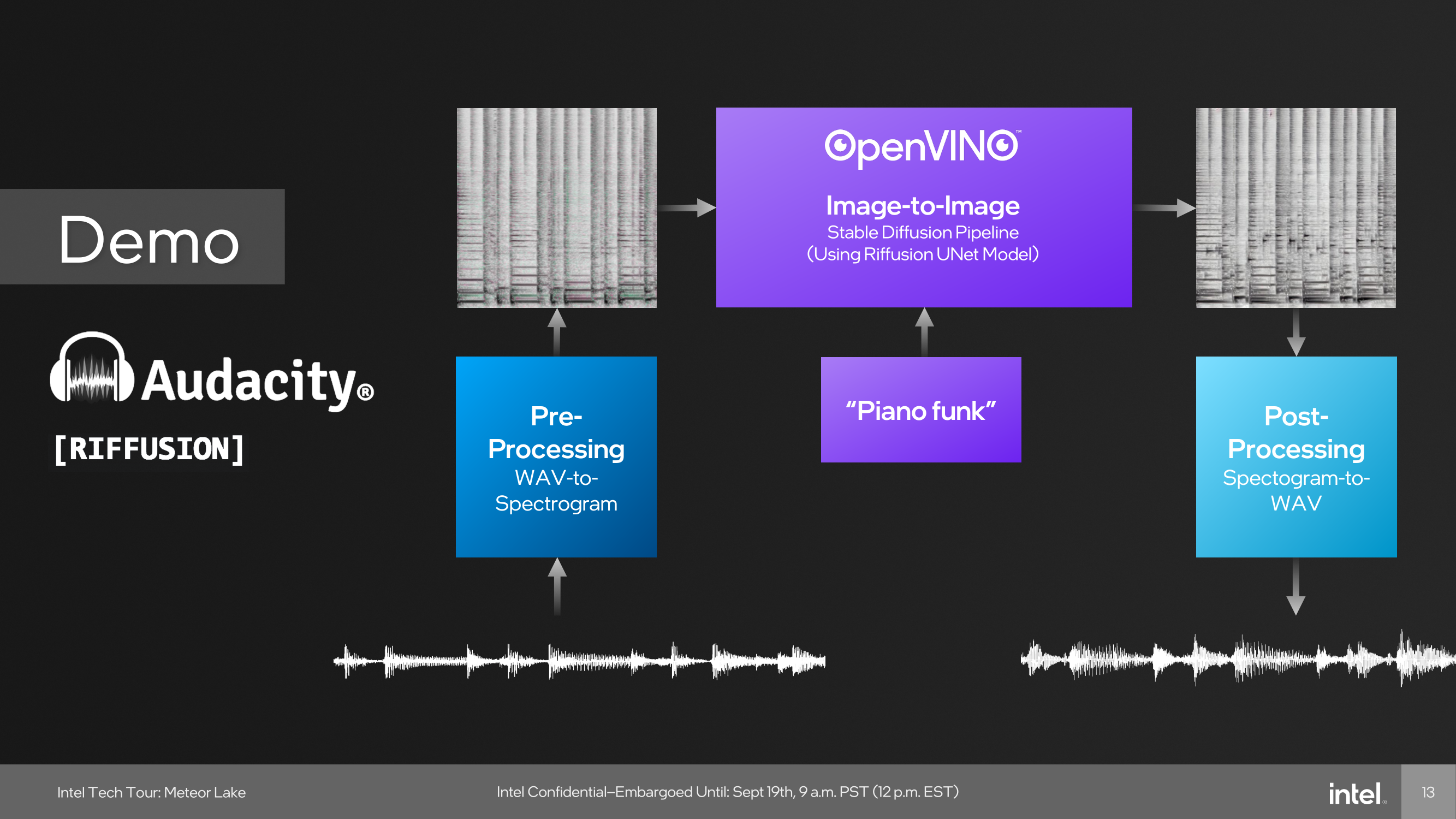
One example of the capabilities of the NPU was provided through a demo using Audacity during Intel's Tech Tour in Penang, Malaysia. During this live demo, Intel Fellow Tom Peterson, used Audacity to showcase a new plugin called Riffusion. This fed a funky audio track with vocals through Audacity and separated the audio tracks into two, vocals and music. Using the Riffusion plugin to separate the tracks, Tom Peterson was then able to change the style of the music audio track to a dance track.
The Riffusion plugin for Audacity uses Stable Diffusion, which is an open-source AI model that traditionally generates images from text. Riffusion goes one step further by generating images of spectrograms, which can then be converted into audio. We touch on Riffusion and Stable Diffusion because this was Intel's primary showcase of the NPU during Intel's Tech Tour 2023 in Penang, Malaysia.
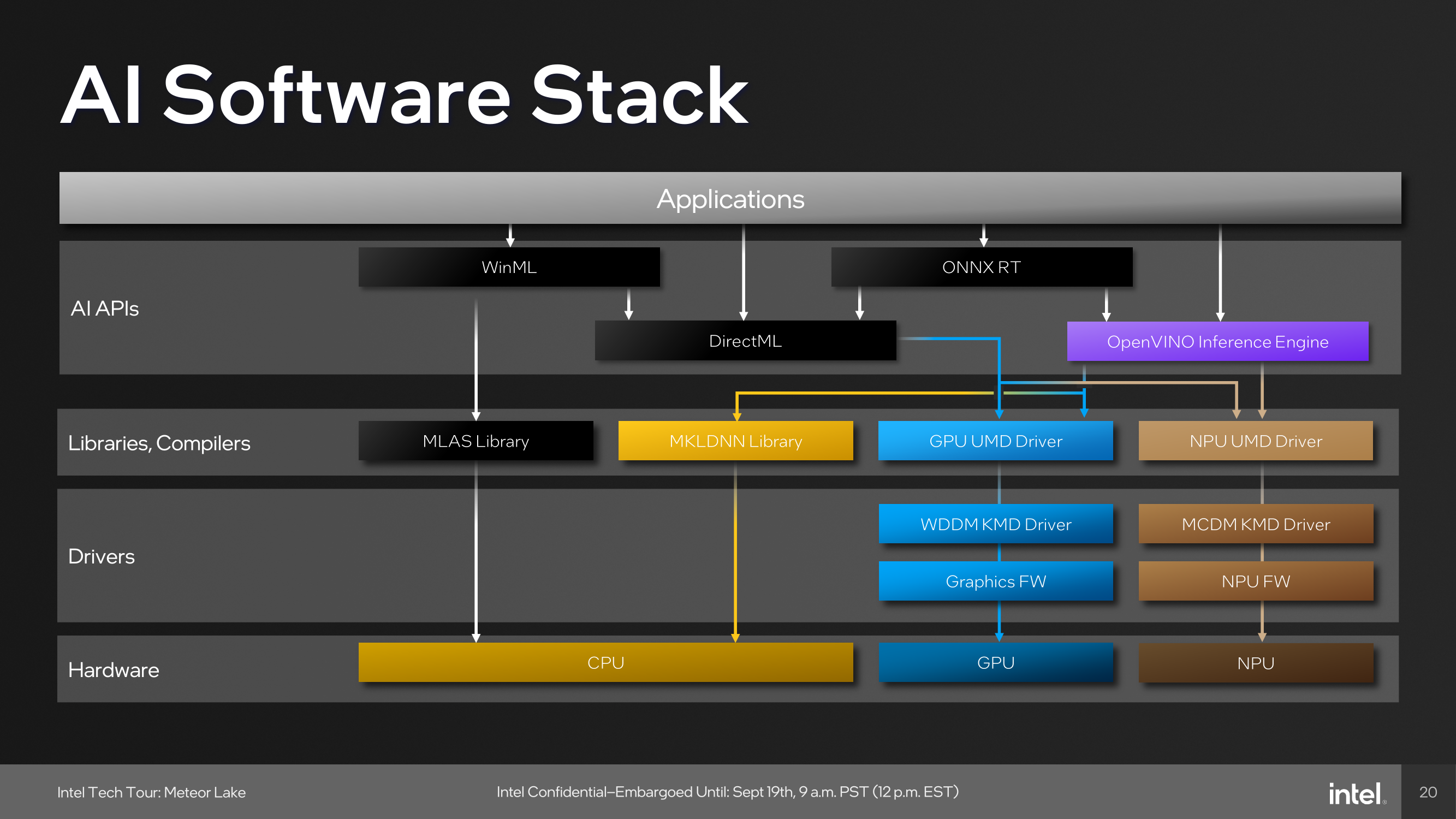
Although it did require resources from both the compute and graphics tile, everything was brought together by the NPU, which processes multiple elements to spit out an EDM-flavored track featuring the same vocals. An example of how applications pool together the various tiles include those through WinML, which has been part of Microsoft's operating systems since Windows 10, typically runs workloads with the MLAS library through the CPU, while those going through DirectML are utilized by both the CPU and GPU.
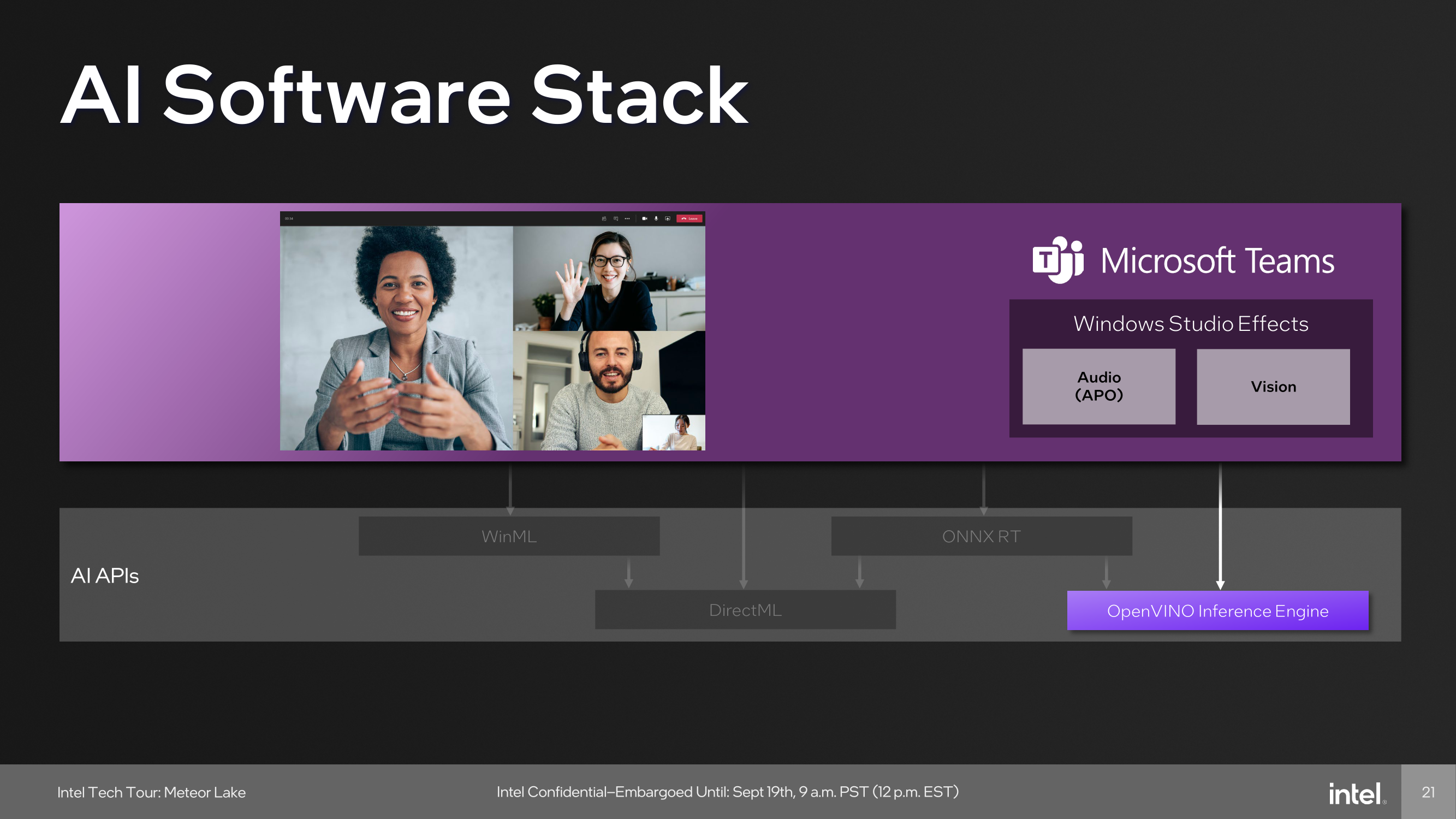
Other developers include Microsoft, which uses the capability of the NPU in tandem with the OpenVINO inferencing engine to provide cool features like speech-to-text transcripts of meetings, audio improvements such as suppressing background noise, and even enhancing backgrounds and focusing capabilities. Another big gun using AI and is supported through the NPU is Adobe, which adds a host of features for adopters of Adobe Creative applications use. These features include generative AI capabilities, including photo manipulative techniques in Photoshop such as refining hair, editing elements, and neural filters; there's a lot going on.








107 Comments
View All Comments
kwohlt - Tuesday, September 19, 2023 - link
The market for people who find TB4 to be insufficient is too small to delay MTL for themExotica - Wednesday, September 20, 2023 - link
Source or market research please ? I have the feeling that many enthusiasts will not be interested. Because of missing TB5. And also because of its ipc improvements (or lack thereof) vs raptor lake.Meteor lake certainly is impressive. But it seems to be less about raw performance and more about the process improvement. Foveros. Chiplets. Euv. New manufacturing abilities. AI engine. Power efficiency. Newish gpu.
But from a generational uplift perspective, from a raw cpu performance to the thunderbolt io, I t’s not much of an upgrade for enthusiasts. Intel should’ve just launched MTL in Dec and then announced TB5 in January. What was the reason to announce TB5 before the MTL reveal?
I guess we will have to wait on arrow lake mobile (if that’s a thing) or lunar lake for TB5 on laptops.
kwohlt - Wednesday, September 20, 2023 - link
You need Market Research to tell you TB4 bandwidth is sufficient for majority of users? 40Gb/s can drive easily gigabit interent and multiple monitors. Most jobs do not require more. At the Fortune 500 I manage IT for, we still haven't even switched to thunderbolt as 3.1 docks are more than sufficient.There's market research on TB4 trends for purchase, that i'm not going to pay for, so we'll just have to settle on "Intel's market research determined that delaying their next gen product line for this 1 feature, potentially causing delays across OEMs 2024 product lines in the process, was not worth it"
PeachNCream - Thursday, September 21, 2023 - link
"...many enthusiasts..."While that segment might be outspoken, the percentage of the overall market is tiny and the percentage that cares among that fraction is even smaller. Basement dweller computer nerds and the e-sports people they idolize don't buy the hundreds of thousands of units that a computer manufacturer purchases. Sure, they get a minor head nod from the company to keep them from slobbering and raving about being ignored, but that's done because it's cheap to coddle them with marketing speak and make them believe features are targeted at them so their ego balloons aren't popped and sites like this have a bone or two to throw them once in a while, but ultimately, no one cares what they want as long as they fanboy argue in favor of their preferred brand with other nerds that like the competition.
TheinsanegamerN - Thursday, September 21, 2023 - link
Exactly. TB5 is exciting and meteor lake is mostly DoA without it. Who would invest thousands into a machine that cant make use of newer functionality?KaarlisK - Tuesday, September 19, 2023 - link
Was this just written by having an AI interpret the slides? And then OCR failed?"This means that higher Out-of-Service (OoS) work is allocated to P-cores for more demanding and intensive workloads, while lower Quality-of-Service (QoS) workloads are directed to E-cores, primarily to save power"
Ryan Smith - Tuesday, September 19, 2023 - link
No, it was done by a sleep-deprived human.KaarlisK - Tuesday, September 19, 2023 - link
Thank you for the explanation.The problem is, I caught at least three more mistakes like this, where a wrong assumption is made about what the text on a slide actually means. In which case (knowing that I'm not an expert), how can I be certain that there aren't many more mistakes that I haven't spotted?
We do come to Anandtech for in-depth analysis, which requires that trust.
Ryan Smith - Tuesday, September 19, 2023 - link
The blunt answer is that we're imperfect (to err is human). We've made mistakes in the past and will continue to do so in the future. But we always own up to those mistakes, and will correct anything if we catch it (or if it gets pointed out).DannyH246 - Tuesday, September 19, 2023 - link
Wow! Intel have some revolutionary ideas here!! Their chiplet approach will change the industry.Would be what i'd have said if they'd have presented this 6 years ago. My response today is...meh.