Intel Unveils Meteor Lake Architecture: Intel 4 Heralds the Disaggregated Future of Mobile CPUs
by Gavin Bonshor on September 19, 2023 11:35 AM ESTSoC Tile, Part 2: NPU Adds a Physical AI Engine
The last major block on the SoC tile is a full-featured Neural Processing Unit (NPU), a first for Intel's client-focused processors. The NPU brings AI capabilities directly to the chip and is compatible with standardized program interfaces like OpenVINO. The architecture of the NPU itself is multi-engine in nature, which is comprised of two neural compute engines that can either collaborate on a single task or operate independently. This flexibility is crucial for diverse workloads and potentially benefits future workloads that haven't yet been optimized for AI situations or are in the process of being developed. Two primary components of these neural compute engines stand out: the Inference Pipeline and the SHAVE DSP.

The Inference Pipeline is primarily responsible for executing workloads in neural network execution. It minimizes data movement and focuses on fixed-function operations for tasks that require high computational power. The pipeline comprises a sizable array of Multiply Accumulate (MAC) units, an activation function block, and a data conversion block. In essence, the inference pipeline is a dedicated block optimized for ultra-dense matrix math.
The SHAVE DSP, or Streaming Hybrid Architecture Vector Engine, is designed specifically for AI applications and workloads. It has the capability to be pipelined along with the Inference Pipeline and the Direct Memory Access (DMA) engine, thereby enabling parallel computing on the NPU to improve overall performance. The DMA Engine is designed to efficiently manage data movement, contributing to the system's overall performance.
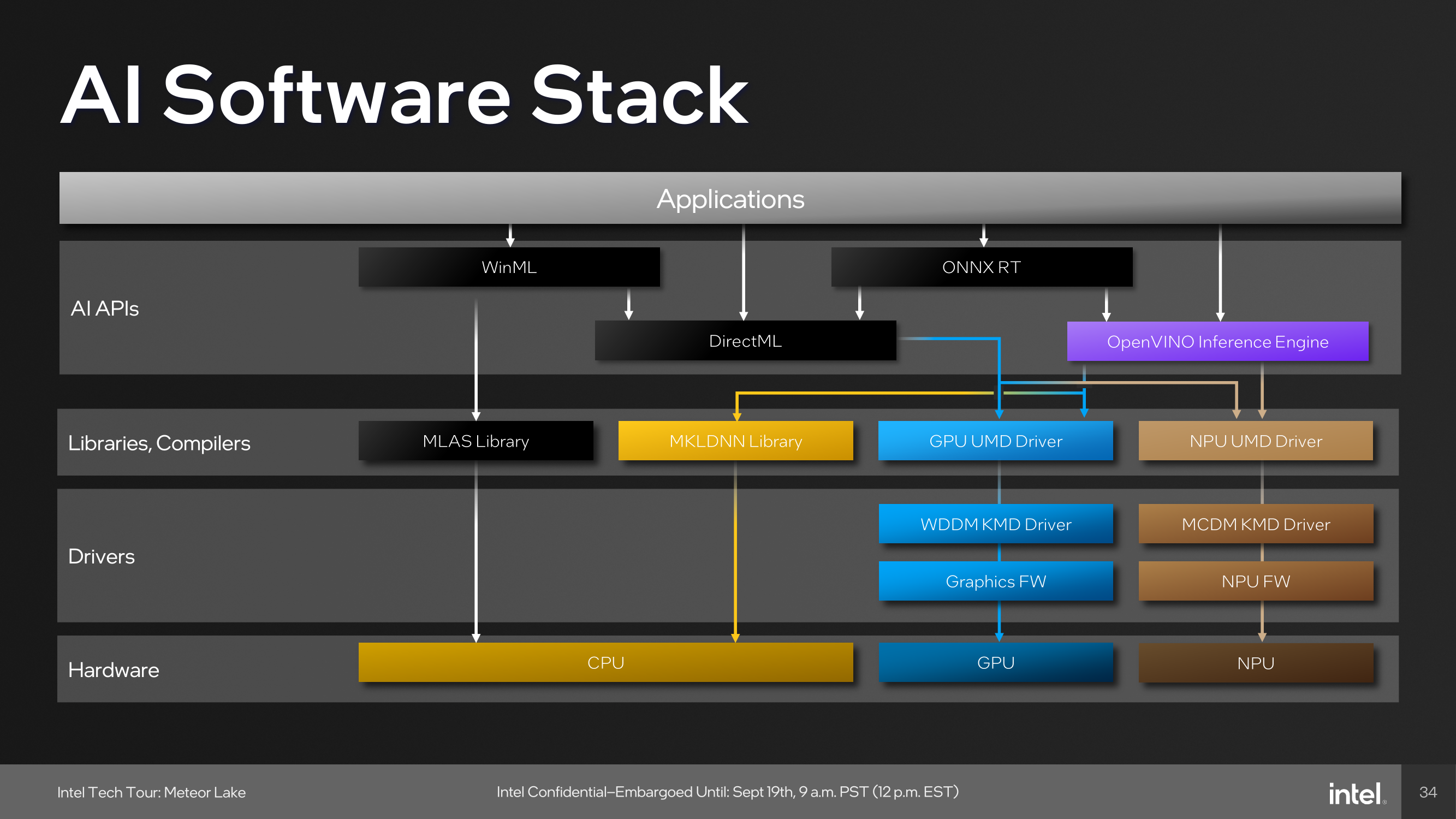
At the heart of device management, the NPU is designed to be fully compatible with Microsoft's new compute driver model, known as MCDM. This isn't merely a feature, but it's an optimized implementation with a strong emphasis on security. The Memory Management Unit (MMU) complements this by offering multi-context isolation and facilitates rapid and power-efficient transitions between different power states and workloads.

As part of building an ecosystem that can capitalize on Intel's NPU, they have been embracing developers with a number of tools. One of these is the open-source OpenVINO toolkit, which supports various models such as TensorFlow, PyTorch, and Caffe. Supported APIs include Windows Machine Learning (WinML), which also includes the DirectML component of the library, the ONNX Runtime accelerator, and OpenVINO.
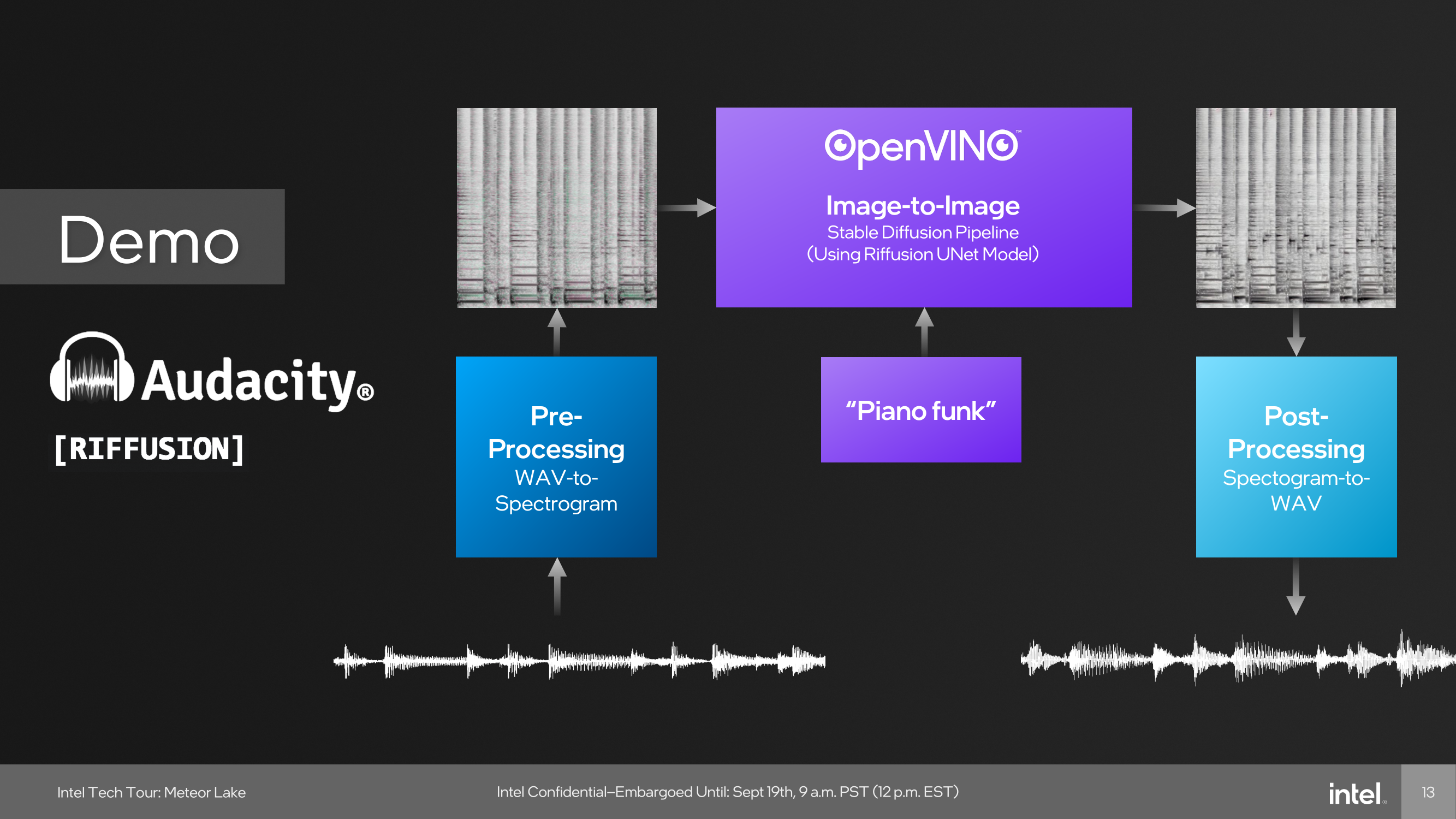
One example of the capabilities of the NPU was provided through a demo using Audacity during Intel's Tech Tour in Penang, Malaysia. During this live demo, Intel Fellow Tom Peterson, used Audacity to showcase a new plugin called Riffusion. This fed a funky audio track with vocals through Audacity and separated the audio tracks into two, vocals and music. Using the Riffusion plugin to separate the tracks, Tom Peterson was then able to change the style of the music audio track to a dance track.
The Riffusion plugin for Audacity uses Stable Diffusion, which is an open-source AI model that traditionally generates images from text. Riffusion goes one step further by generating images of spectrograms, which can then be converted into audio. We touch on Riffusion and Stable Diffusion because this was Intel's primary showcase of the NPU during Intel's Tech Tour 2023 in Penang, Malaysia.
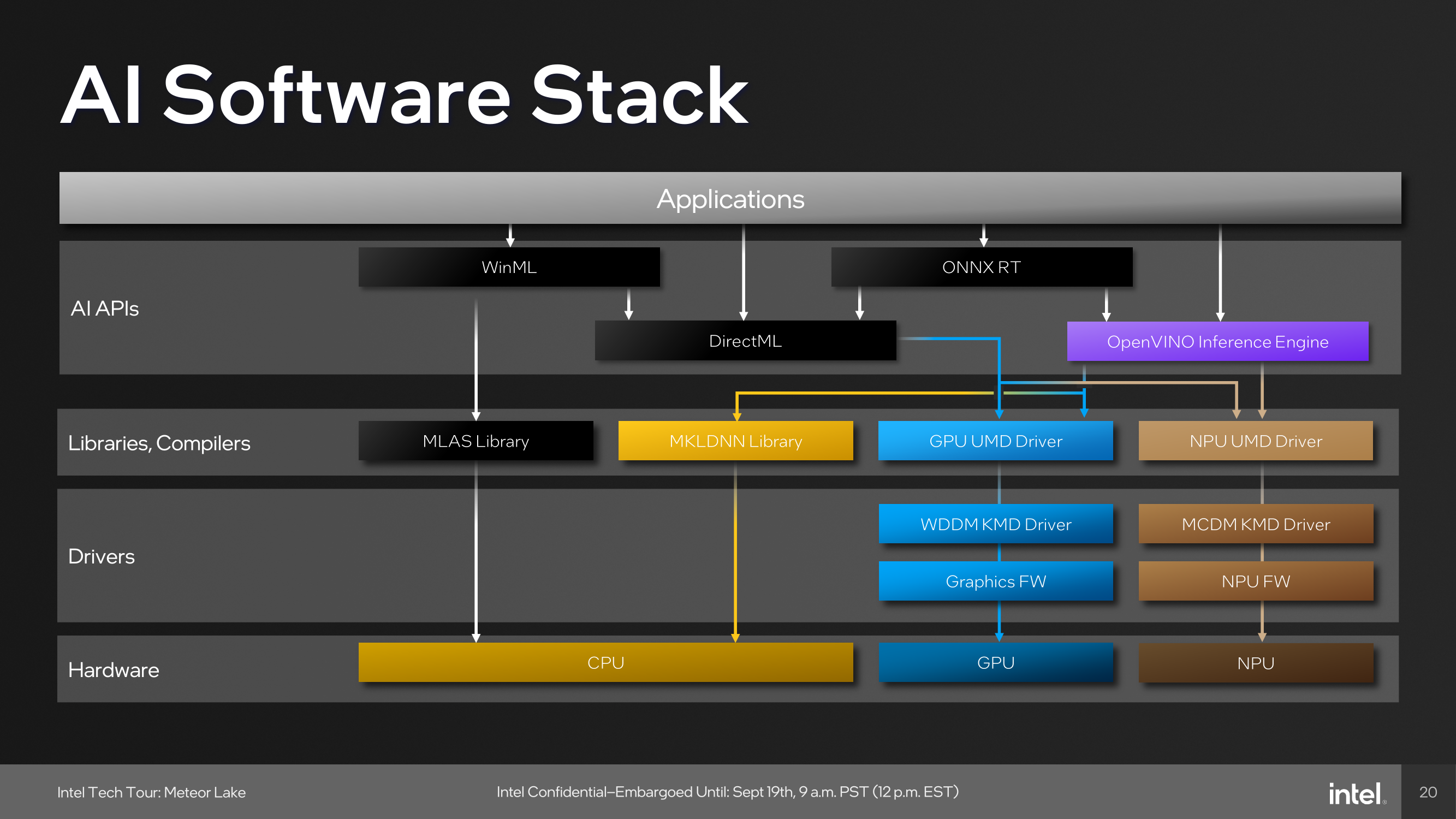
Although it did require resources from both the compute and graphics tile, everything was brought together by the NPU, which processes multiple elements to spit out an EDM-flavored track featuring the same vocals. An example of how applications pool together the various tiles include those through WinML, which has been part of Microsoft's operating systems since Windows 10, typically runs workloads with the MLAS library through the CPU, while those going through DirectML are utilized by both the CPU and GPU.
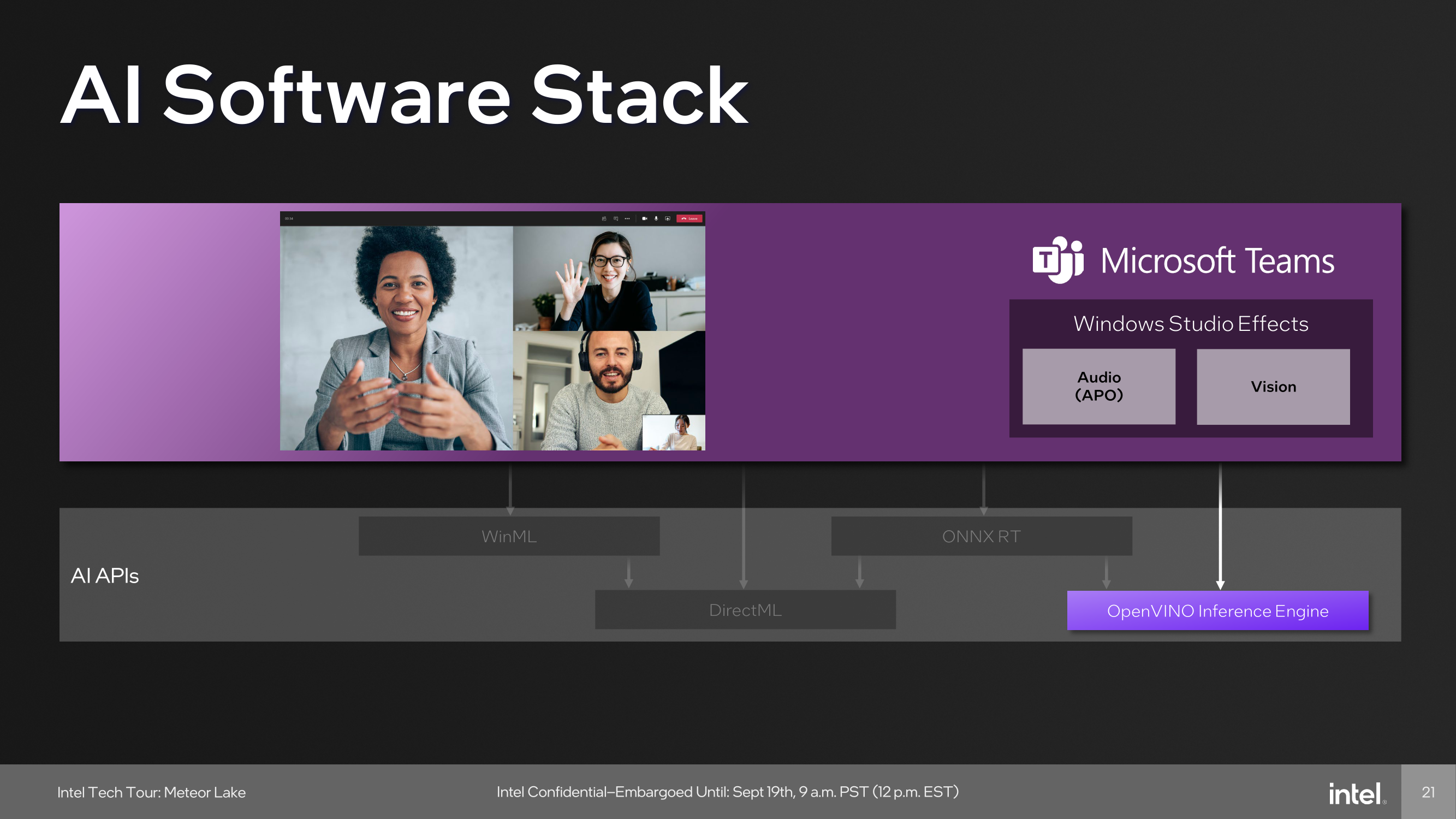
Other developers include Microsoft, which uses the capability of the NPU in tandem with the OpenVINO inferencing engine to provide cool features like speech-to-text transcripts of meetings, audio improvements such as suppressing background noise, and even enhancing backgrounds and focusing capabilities. Another big gun using AI and is supported through the NPU is Adobe, which adds a host of features for adopters of Adobe Creative applications use. These features include generative AI capabilities, including photo manipulative techniques in Photoshop such as refining hair, editing elements, and neural filters; there's a lot going on.








107 Comments
View All Comments
FWhitTrampoline - Thursday, September 21, 2023 - link
That would be more of DIY friendly Very Small Form Factor Enthusiast/end user there! And with a reasonable expectation that the vibrant DIY Small Form Factor devices(Mini desktop PCs) market continue to be offered Socket Packaged Processors with newer than Ryzen 5000G/Zen-3 and Vega 8CU iGPU based graphicsIP, and Ditto for any Intel based options as well.
So it's wrong to expect any Further Ryzen G series Desktop[Socket Packaged] APUs from AMD because that's not good for the OEMs there and their business models that are not so DIY friendly for Processor Upgrades if the Processor comes BGA wedded to the Motherboard! And OEM products that are not so good for eWaste reduction because if the processor goes that can not be easily replaced/upgraded by the end user(DIY sorts of Folks).
There needs to be a Right to Processor Upgrade just as much as a Right to Repair and with Socket packaged processors those rights go hand in hand there along with any environmental eWaste concerns. But we must not trample upon those Business Models as that's just not good for OEM Profits there, consumers be damned!
And InWin Chopin or ASRock Desk Mini, Socket Packaged APUs/SOCs are the best option as that's by definition DIY friendly there.
I'll expect no Complaints from you if the entire PC market goes BGA Packaged Processors only and you'll have to buy the Processor Attached to the Motherboard, take it or leave it!
brucethemoose - Wednesday, September 20, 2023 - link
> That might make a really nice media playerSeems like a lot of silicon for what's essentially the job of a dirt cheap ARM SoC. And its a questionable fit for a headless system unless its like a stable diffusion/transcoding host.
It *does* seems like an interesting fit for a smart TV chip, maybe with a small GPU die, as they would actually use the NPU for their internal video filtering.
emvonline - Tuesday, September 19, 2023 - link
Intel 4 will not be shipping any products to customers until Mid December. This after stating it is in production in December 2022. 12 months from production starts to PCs out is not good. And I better be able to buy meteor lake Notebook on Dec 14th 2023 or this is exactly like old Intel (Launch means we may have sold some parts to someone somewhere). This claiming a node is done when its production ready, when you ship nothing is problematic. FYI Meteor Lake is 2x the cost of Raptor lake in 2024. Intel 4 is not a cost reduction. The product might be great but it is expensiveRoy2002 - Tuesday, September 19, 2023 - link
4 was in production in December 2022? No way! It should be started not long ago.Usually the first real product silicon would be taped out one year ahead of release date. And that silicon would be very buggy and needs several steppings to have bugs fixed.
Roy2002 - Tuesday, September 19, 2023 - link
So December 2022 is the initial project tapein date and silicon debug follows.ChrisGar15 - Tuesday, September 19, 2023 - link
Probably called "manufacturing ready."xol - Wednesday, September 20, 2023 - link
So Xe-lpg is still intel uhd graphics (13\14th gen now?) with top EU count of 128 up from 96. Fine.maybe about 3TF fp32, not quite xbox Series S level
They added RT support which is good i guess but will it ever be used in a gpu that is really PS4 performance?, or maybe there are not gaming applications.
product sounds good, just wait for the numbering scheme
JBCIII - Wednesday, September 20, 2023 - link
"An example of how applications pool together the various tiles include those through WinML, which has been part of Microsoft's operating systems since Windows 10, typically runs workloads with the MLAS library through the CPU, while those going through DirectML are utilized by both the CPU and GPU."This sentence is really a mess. Editor: please take note. Is "example" the subject of "include"? That would make "includes" the necessary form of the verb. What is the subject of "runs"? I'm guessing WinML. Maybe it should be "WinML...which typically runs" but the long parenthetical expression about Windows 10 support makes it hard to bridge the gap. Maybe parentheses would be more clear instead of commas to keep the meaning on track. I'm still not sure what was meant.
GeoffreyA - Thursday, September 21, 2023 - link
WinML is the higher-level abstraction, and DirectML, the lower-level one.Kevin G - Wednesday, September 20, 2023 - link
This is what I was hoping to see Intel pull off in the late 14 nm/early 10 nm days when their foundries were having difficulties. Intel should have pivoted int his direction at the first sign of trouble with those as the packaging side of this, while cutting edge back then, could have been pulled off. Better late than never.However with Meteor Lake around the corner, it is shaping up to a pretty good design. Both the CPU and GPU sides can scale and evolve independently from the central SoC. The GPU portion that was moved onto the SoC makes sense as the codecs and display logic are not going to change over the next few generations. I would quibble about the point made that putting them next to the NPU is more advantageous than next to the GPU cores. There certainly is a benefit for AI upscaling of movies but my presumption is that I'd be lower power/lower latency to have the encoders next to the GPU cache which houses the final render frame for encoding and transmission. The tasks that's benefit here would be gaming streaming or remote access. Both things can be true hence why it is a quibble as it'll matter to individual use cases which one approach is superior.
My initial presumption for the IO die was that it was to house various analog circuits that would then be leveraged by the SoC die. This is a clever means of process optimization as analog circuitry does not scale at the same rate as logic. Similarly this would permit a cheaper die to extend the number of area intensive IO pads.
The last thing missing is the L4 cache die that was hinted at in earlier Linux patches. That'll probably come along with the Lunar Lake generation.