Intel Xeon Sapphire Rapids: How To Go Monolithic with Tiles
by Dr. Ian Cutress on August 31, 2021 10:00 AM ESTAdd In Some HBM, Optane
The other angle to Sapphire Rapids is the versions with HBM on board. Intel announced this back in June, but there haven’t been many details. As part of Architecture Day, Intel stated that that HBM versions of Sapphire Rapids would be made public, and be made socket compatible with standard Sapphire Rapids. The first customer of the HBM versions of SPR is the Argonne National Lab, as part of its Aurora Exascale supercomputer.
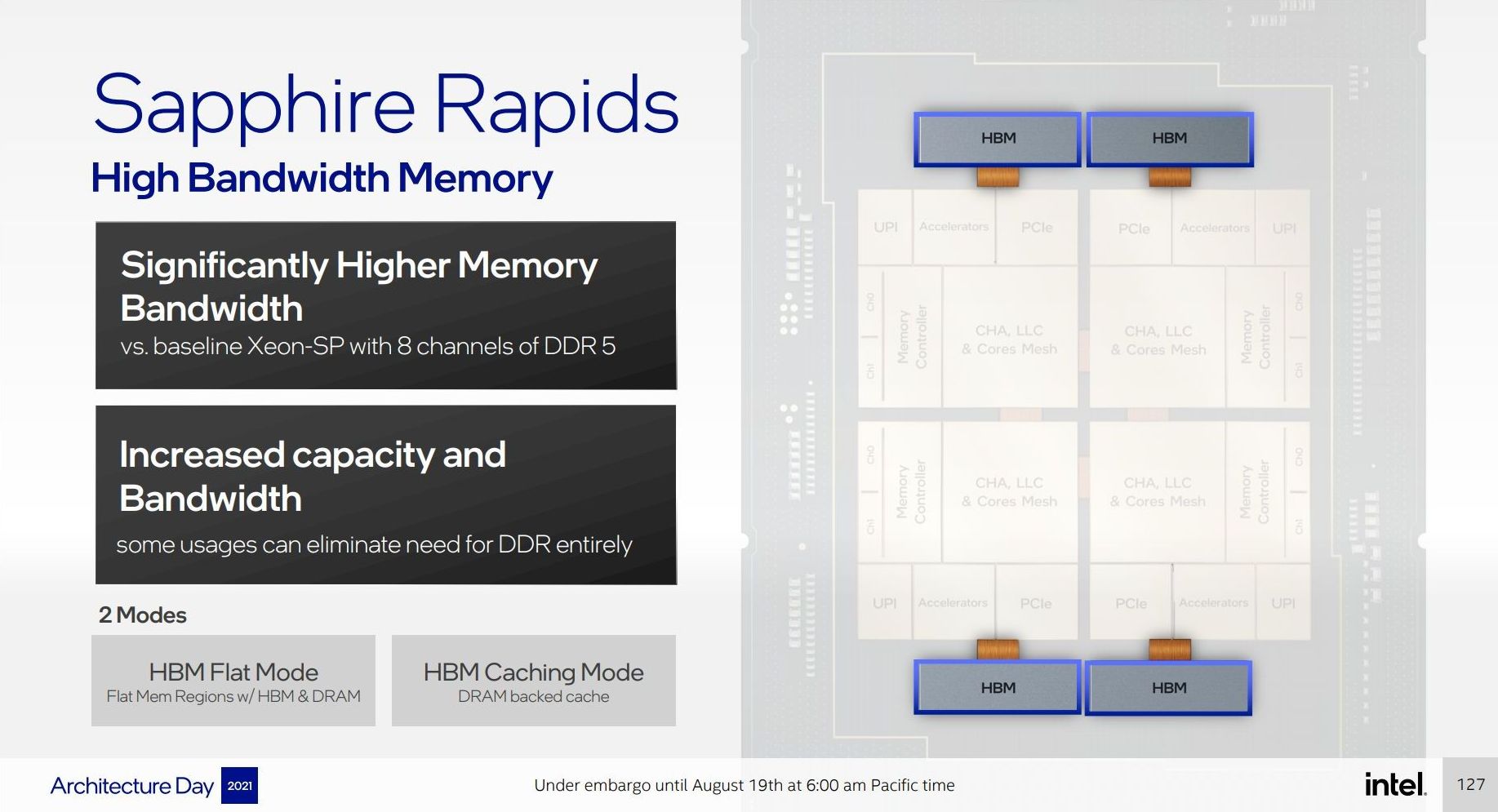
This diagram it showcases four HBM connections, one to each compute tile. Looking at the package, however, I don’t think that there’s realistically enough space unless Intel has commissioned some novel HBM that is long and narrow as it is in the diagram.

Even though Intel said that the HBM variants would be in the same socket, even their own slide from Hot Chips says different.
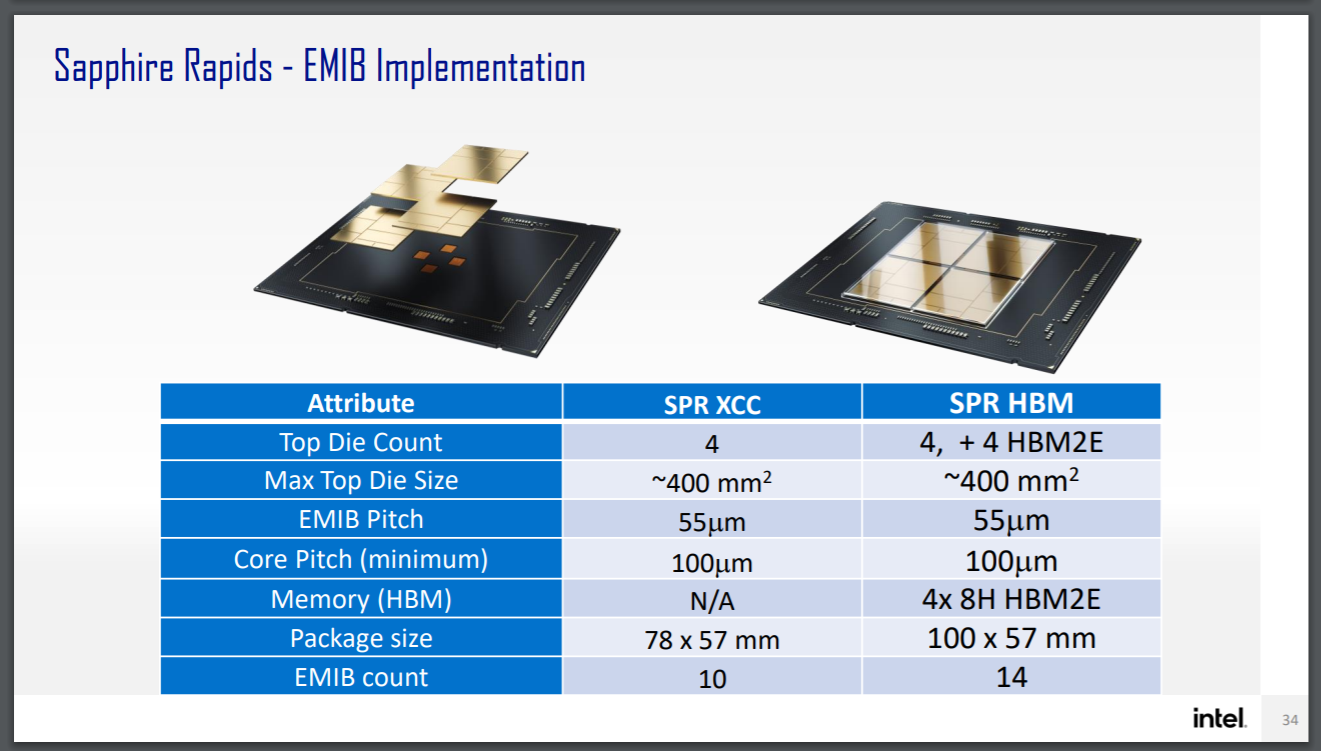
Here the package size with HBM says 100x57mm, compared to the SPR which is 78x57mm. So unless Intel is planning a reduced version for the 78x57mm socket, it's going to be in a different socket.
It is important to note that HBM will act in a similar capacity to Optane – either as an HBM flat mode with DRAM that equates the two, or as an HBM caching mode that acts similar to an L4 cache before hitting main memory. Optane on top of this can also be in a flat mode, a caching mode, or as a separate storage volume.
HBM will add power consumption to the package, which means we’re unlikely to see the best CPU frequencies paired with HBM if it is up against the socket limit. Intel has not announced how many HBM stacks or what capacities will be used in SPR, however it has said that they will be underneath the heatspreader. If Intel are going for a non-standard HBM size, then it’s anyone’s guess what the capacity is. But we do know that it will be connected to the tiles via EMIB.
A side note on Optane DC Persistent Memory – Sapphire Rapids will support a new 300 series Optane design. We asked Intel if this was the 200-series but using a DDR5 controller, and were told that no, this is actually a new design. More details to follow.
UPI Links
Each Sapphire Rapids Processor will have up to four x24 UPI 2.0 links to connect to other processors in a multi-socket design. With SPR, Intel is aiming for up to eight socket platforms, and in order to increase bandwidth has upgraded from three links in ICL to four (CLX had 2x3, technically), and moved to a UPI 2.0 design. Intel would not expand more on what this means, however they will have a new eight-socket UPI topology.
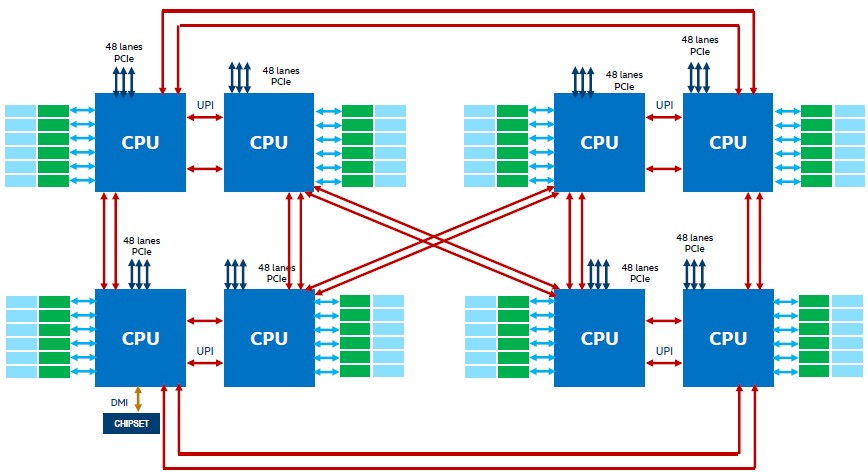
Current Intel Hypercube
Current eight-socket designs use a twisted hypercube topology: two groups of four form a box, and one pair is connected to the same vertex on the other set of four, while the second pair is inverted. Make sense? No, not really. Essentially each CPU is directly connected to three others, and the other four are two hops away. With the new topology, each CPU gets a direct connection to another, which moves the design more towards a fully connected topology, however exactly which CPU that connection should go to, Intel hasn’t stated yet.
Security
Intel has stated that it will be announcing full Security updates for SPR at a later time, however features like MKTME and SGX are key priorities.
Conclusions
For me, the improved cores, upgraded PCIe/DDR, and the ‘appears as a monolith’ approach are the highlights to date. However, there are some very obvious questions still to be answered – core counts, power consumption, how lower core counts would work (even suggestions that the LCC version is actually monolithic), and what the HBM enabled versions will look like. The HBM versions, with the added EMIB, are going to cost a good amount, which isn’t great at a time when AMD’s pricing structure is very competitive.
It is expected that when Sapphire Rapids is released, AMD will still be in the market with Milan (or as some are postulating, 3D V-Cache versions of Milan, but nothing is confirmed) and it won’t be until the end of 2022 when AMD launches Zen 4. If Intel can execute and bring SPR into the market, it will have a small time advantage in which to woo potential customers. Ice Lake is being sold on its specific accelerator advantages, rather than raw core performance, and we will have to wait and see if Sapphire Rapids can bring more to the table.
Intel moving to a tile/chiplet strategy in the enterprise has been expected for a number of years – at least on this side of the fence, ever since AMD made it work and scale beyond standard silicon limits, regardless of whatever horse-based binding agent is used between the silicon, Intel would have to go down this route. It has been delayed, mostly due to manufacturing but also optimizing things like EMIB which also takes time. EMIB as a technology is really impressive, but the more chips and bridges you put together, even if you have a 99% success rate, that cuts into yield. But that's what Intel has been working on, and for the enterprise market, Sapphire Rapids is the first step.








94 Comments
View All Comments
coburn_c - Tuesday, August 31, 2021 - link
Lot of redundancies, guess they were shy to move controllers to separate silicon.. specially 14nm silicon...TeXWiller - Tuesday, August 31, 2021 - link
I forgot to ask about the Alderlake AVX support. I quickly looked at the Intel's presentation and it casted AMX acceleration as enterprise feature in no uncertain terms, which the slides show in this article as well (some journalists got confused at this point). However, the AVX512 support was simply thrown in as a feature of all P-cores without a distinction. Where did you get the information on the status of the consumer AVX512 support?thestryker - Tuesday, August 31, 2021 - link
ADL E-cores do not have AVX512 and there's no effective way currently deal with having two different levels of AVX support in the same processor. If you read through the ADL coverage here on AnandTech you'll see it isn't in any of the slides, and I believe it was Ian who confirmed they're fusing it off for ADL.JayNor - Wednesday, September 1, 2021 - link
I think their dpc++ could handle it just as easily as handling the CPU vs GPU differences. Just need to add another device type.psyclist80 - Tuesday, August 31, 2021 - link
Hey look intel woke up! welcome to 2021! things have changed quite a bit, good luck!diediealldie - Tuesday, August 31, 2021 - link
HBM variants are quite interesting. HBMs can work as an L4 cache, but they have latency penalties due to lower clocks(thermal limit). Quite curious how high latency + high bandwidth will work with various workloads.JayNor - Wednesday, September 1, 2021 - link
Intel commented that HBM wasn't fast enough for all their needs on Ponte Vecchio. They added large L1 and L2 caches and a Rambo Cache that has yet to be fully described.emn13 - Wednesday, September 1, 2021 - link
I'm almost disappointed they're not using gracemont - I suppose that wasn't realistic. In any case, either the tantalizing leaks of gracemonts perf and efficiency are false, or it would be a fantastic server chip - almost 4x the cores, albeit significantly slower ones? Yes please!Calin - Wednesday, September 1, 2021 - link
They would run straight into the ARM powered microprocessors - see https://aws.amazon.com/ec2/graviton/Intel doesn't really want to compete at the low end (many cheap cores), its entire marketing message is "we make fast and expensive microprocessors in the server market".
emn13 - Wednesday, September 1, 2021 - link
I guess, but it's still a shame - and simply having something *available* would discourage people from bothering to switch architecture, you'd think.Then again, perhaps AMD's EPYC is good enough for that, at least for now.