Intel 11th Generation Core Tiger Lake-H Performance Review: Fast and Power Hungry
by Brett Howse & Andrei Frumusanu on May 17, 2021 9:00 AM EST- Posted in
- CPUs
- Intel
- 10nm
- Willow Cove
- SuperFin
- 11th Gen
- Tiger Lake-H
CPU Tests: Microbenchmarks
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
In terms of the core-to-core tests on the Tiger Lake-H 11980HK, it’s best to actually compare results 1:1 alongside the 4-core Tiger Lake design such as the i7-1185G7:
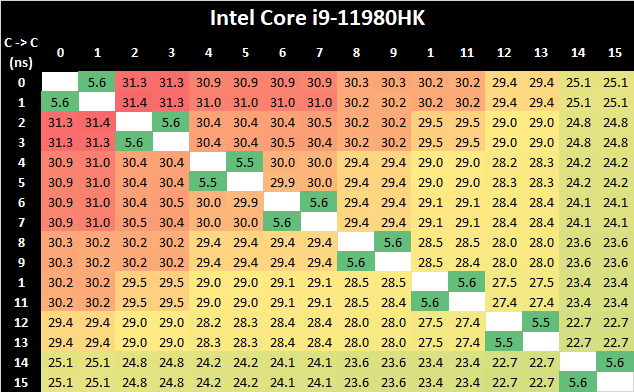

What’s very interesting in these results is that although the new 8-core design features double the cores, representing a larger ring-bus with more ring stops and cache slices, is that the core-to-core latencies are actually lower both in terms of best-case and worst-case results compared to the 4-core Tiger Lake chip.
This is generally a bit perplexing and confusing, generally the one thing to account for such a difference would be either faster CPU frequencies, or a faster clock of lower cycle latency of the L3 and the ring bus. Given that TGL-H comes 8 months after TGL-U, it is plausible that the newer chip has a more matured implementation and Intel would have been able to optimise access latencies.
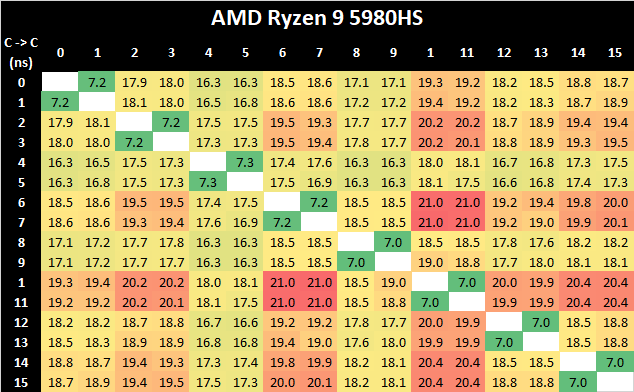
Due to AMD’s recent shift to a 8-core core complex, Intel no longer has an advantage in core-to-core latencies this generation, and AMD’s more hierarchical cache structure and interconnect fabric is able to showcase better performance.
Cache & DRAM Latency
This is another in-house test built by Andrei, which showcases the access latency at all the points in the cache hierarchy for a single core. We start at 2 KiB, and probe the latency all the way through to 256 MB, which for most CPUs sits inside the DRAM (before you start saying 64-core TR has 256 MB of L3, it’s only 16 MB per core, so at 20 MB you are in DRAM).
Part of this test helps us understand the range of latencies for accessing a given level of cache, but also the transition between the cache levels gives insight into how different parts of the cache microarchitecture work, such as TLBs. As CPU microarchitects look at interesting and novel ways to design caches upon caches inside caches, this basic test proves to be very valuable.
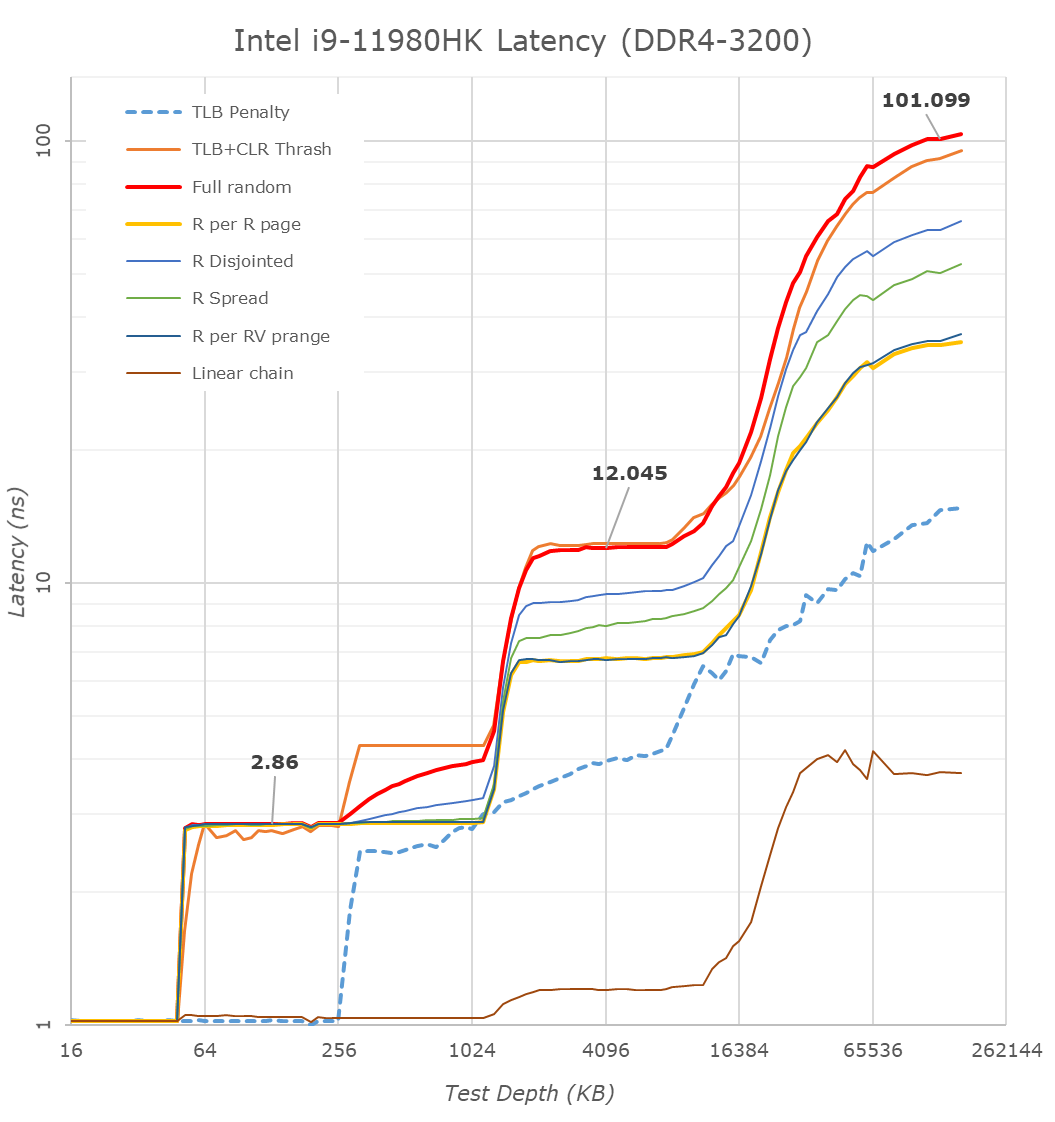
What’s of particular note for TGL-H is the fact that the new higher-end chip does not have support for LPDDR4, instead exclusively relying on DDR4-3200 as on this reference laptop configuration. This does favour the chip in terms of memory latency, which now falls in at a measured 101ns versus 108ns on the reference TGL-U platform we tested last year, but does come at a cost of memory bandwidth, which is now only reaching a theoretical peak of 51.2GB/s instead of 68.2GB/s – even with double the core count.
What’s in favour of the TGL-H system is the increased L3 cache from 12MB to 24MB – this is still 3MB per core slice as on TGL-U, so it does come with the newer L3 design which was introduced in TGL-U. Nevertheless, this fact, we do see some differences in the L3 behaviour; the TGL-H system has slightly higher access latencies at the same test depth than the TGL-U system, even accounting for the fact that the TGL-H CPUs are clocked slightly higher and have better L1 and L2 latencies. This is an interesting contradiction in context of the improved core-to-core latency results we just saw before, which means that for the latter Intel did make some changes to the fabric. Furthermore, we see flatter access latencies across the L3 depth, which isn’t quite how the TGL-U system behaved, meaning Intel definitely has made some changes as to how the L3 is accessed.








229 Comments
View All Comments
Bagheera - Tuesday, May 18, 2021 - link
Intel isn't gonna have enough EUV in time to ramp 7nm by 2023. they are in serious trouble and floating on borrowed time, most analysts just aren't aware.https://semiwiki.com/forum/index.php?threads/will-...
Intel's 10nm is indeed competitive with TSMC 7nm in terms of density, but AMD will be moving to 5nm with Zen 4 next year, what can Intel's response be? They can increase outsourcing to TSMC but that means less utilization of their own fabs which is bad. They absolutely won't be able to get 7nm ready in time to compete with AMD on TSMC 5nm. It will be back to the status quo of Intel lagging behind AMD by one full node, and likely foregoing power efficiency for performance parity.
Bagheera - Tuesday, May 18, 2021 - link
no actual semiconductor professional expected Intel 10nm to surpass TSMC 7nm in any tangible way. the only people who expected otherwise are uniformed enthusiasts (usually gamers, who the to be partial to Intel)The gap will only widen from here. Intel really shot itself in the foot with bad EUV planning.
https://semiwiki.com/semiconductor-services/ic-kno...
watzupken - Tuesday, May 18, 2021 - link
I feel this review concludes that Intel have effectively lost their competitive edge when their fab started to lag behind. In fact, its also conclusive that the SuperFin is really nothing super at all even when compared to TSMC's 7nm. Its just 10nm on steroids just like what they have been doing to their 14nm. From an architect standpoint, Willow Cove is decent, but the bulk of the performance is due to pushing for very high clock speed at the expense of very high power consumption. If this was released on a desktop, it will be a hit. But on mobile, I don't think one can easily find a laptop that have the cooling capability to tame the heat output and also maintain a decent battery life. Especially this processor will likely be paired with a high end GPU. To me, this is a worrying trend for Intel because they will likely have to stick around with 10nm for another couple of years at least. If their new CPU architect is unable to provide decent IPC gains without bursting the power limit, they will surely be in trouble, especially when AMD's 5nm chips may appear in the market first.mode_13h - Tuesday, May 18, 2021 - link
> If this was released on a desktop, it will be a hit.Yes.
> I don't think one can easily find a laptop that have the cooling capability
> to tame the heat output and also maintain a decent battery life.
At 35 W, it would probably make a fine laptop. Unfortunately, competitive pressure is pushing Intel to juice their CPUs more than they really should.
sandeep_r_89 - Tuesday, May 18, 2021 - link
Can you please please stop using the word BIOS for modern devices? Pretty much all devices have been on UEFI only for several years now.Silver5urfer - Tuesday, May 18, 2021 - link
Ah the M1 fastest CPU ever, doesn't make it to SMT SPEC scores for some reason, like always. Don't worry we will see the Apple CPU which would be X version of the chip iteration when it finally catches up to the SMT of these SMT until then M1 is the best CPU ever.TGL machines will throttle to peak with the thin and light garbage heatsinks. That's a given, people should stop buying these parts. Laptop batteries will be destroyed eventually and none of them will have the Dell Desktop Power plan only Workstations have that feature (Lenovo and Dell), Alienware used to have, not sure about now their A51M R1 and R2 also they had their GFX modules smoke, anyways the battery won't be available for the end user to service and the expensive machine will die and BGA with soldered HW to further limit everything, add the overheating NVMe SSDs due to poor ventilation, happens in Alienware machines too which are targeted as maximum performance.
Spunjji - Thursday, May 20, 2021 - link
🤪🤡😤🤬🤥💩mode_13h - Friday, May 21, 2021 - link
Oof. Looks like *someone* is giving Emojipedia a workout!: )
Spunjji - Tuesday, May 18, 2021 - link
This ended up how I was expecting - superior single-core performance where there's thermal headroom, dropping down to broadly competitive multi-performance at the rated TDP, and with a faintly ludicrous maximum power draw under all-core boost.I'm glad it's competitive. That's needed. What I'm a little less glad about is that we're almost certainly in for another round of CPU performance varying *wildly* between different designs, which has been true to some extent for a while, but getting steadily worse ever since Ice Lake showed up.
Given most OEMs' approach to cooling, I'd wager that the average device shipping with Cezanne will provide better CPU performance than the average device with Tiger 45 simply because of Cezanne's greater efficiency.
tekit - Tuesday, May 18, 2021 - link
Heard they enabled undervolting again for tiger lake-h, can anyone confirm? I wonder how much undervolting potential there is and if that could balance the equation against AMD.